 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven building energy efficiency prediction based on envelope heat losses using physics-informed neural networks
Nov 14, 2023The analytical prediction of building energy performance in residential buildings based on the heat losses of its individual envelope components is a challenging task. It is worth noting that this field is still in its infancy, with relatively limited research conducted in this specific area to date, especially when it comes for data-driven approaches. In this paper we introduce a novel physics-informed neural network model for addressing this problem. Through the employment of unexposed datasets that encompass general building information, audited characteristics, and heating energy consumption, we feed the deep learning model with general building information, while the model's output consists of the structural components and several thermal properties that are in fact the basic elements of an energy performance certificate (EPC). On top of this neural network, a function, based on physics equations, calculates the energy consumption of the building based on heat losses and enhances the loss function of the deep learning model. This methodology is tested on a real case study for 256 buildings located in Riga, Latvia. Our investigation comes up with promising results in terms of prediction accuracy, paving the way for automated, and data-driven energy efficiency performance prediction based on basic properties of the building, contrary to exhaustive energy efficiency audits led by humans, which are the current status quo.
Transfer learning for day-ahead load forecasting: a case study on European national electricity demand time series
Oct 24, 2023Short-term load forecasting (STLF) is crucial for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. Various forecasting approaches have been proposed for improving STLF, including neural network (NN) models which are trained using data from multiple electricity demand series that may not necessary include the target series. In the present study, we investigate the performance of this special case of STLF, called transfer learning (TL), by considering a set of 27 time series that represent the national day-ahead electricity demand of indicative European countries. We employ a popular and easy-to-implement NN model and perform a clustering analysis to identify similar patterns among the series and assist TL. In this context, two different TL approaches, with and without the clustering step, are compiled and compared against each other as well as a typical NN training setup. Our results demonstrate that TL can outperform the conventional approach, especially when clustering techniques are considered.
Calibration of Transformer-based Models for Identifying Stress and Depression in Social Media
May 26, 2023
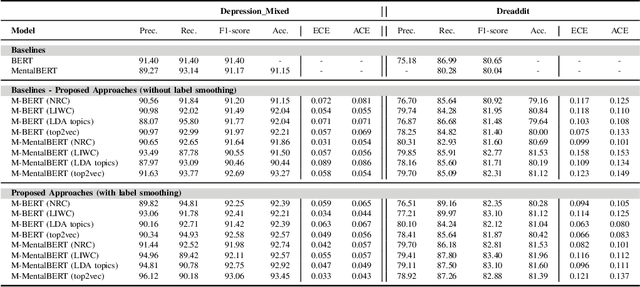
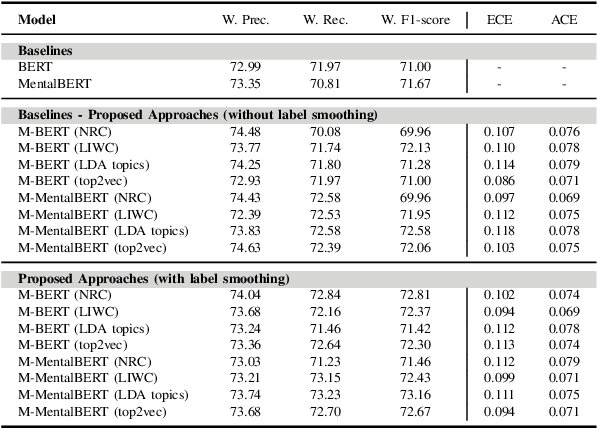
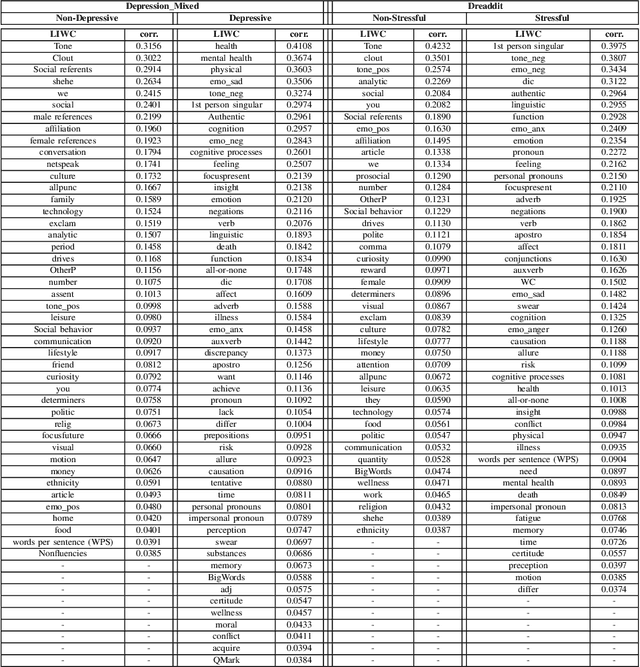
In today's fast-paced world, the rates of stress and depression present a surge. Social media provide assistance for the early detection of mental health conditions. Existing methods mainly introduce feature extraction approaches and train shallow machine learning classifiers. Other researches use deep neural networks or transformers. Despite the fact that transformer-based models achieve noticeable improvements, they cannot often capture rich factual knowledge. Although there have been proposed a number of studies aiming to enhance the pretrained transformer-based models with extra information or additional modalities, no prior work has exploited these modifications for detecting stress and depression through social media. In addition, although the reliability of a machine learning model's confidence in its predictions is critical for high-risk applications, there is no prior work taken into consideration the model calibration. To resolve the above issues, we present the first study in the task of depression and stress detection in social media, which injects extra linguistic information in transformer-based models, namely BERT and MentalBERT. Specifically, the proposed approach employs a Multimodal Adaptation Gate for creating the combined embeddings, which are given as input to a BERT (or MentalBERT) model. For taking into account the model calibration, we apply label smoothing. We test our proposed approaches in three publicly available datasets and demonstrate that the integration of linguistic features into transformer-based models presents a surge in the performance. Also, the usage of label smoothing contributes to both the improvement of the model's performance and the calibration of the model. We finally perform a linguistic analysis of the posts and show differences in language between stressful and non-stressful texts, as well as depressive and non-depressive posts.
Towards a real-time demand response framework for smart communities using clustering techniques
Mar 01, 2023
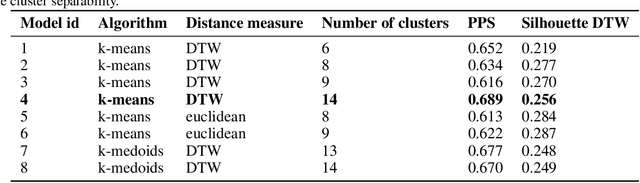


The present study explores the use of clustering techniques for the design and implementation of a demand response (DR) program for commercial and residential prosumers. The goal of the program is to shift the participants' consumption behavior to mitigate two issues a) the reverse power flow at the primary substation, that occurs when generation from solar panels in the local grid exceeds consumption and b) the system wide peak demand, that typically occurs during hours of the late afternoon. For the clustering stage, three popular algorithms for electrical load clustering are employed -- namely k-means, k-medoids and a hierarchical clustering algorithm -- alongside two different distance metrics -- namely euclidean and constrained Dynamic Time Warping (DTW). We evaluate the methods using different validation metrics including a novel metric -- namely peak performance score (PPS) -- that we propose in the context of this study. The best setup is employed to divide daily prosumer load profiles into clusters and each cluster is analyzed in terms of load shape, mean entropy and distribution of load profiles from each load type. These characteristics are then used to distinguish the clusters that would be most likely to aid with the DR schemes would fit each cluster. Finally, we conceptualize a DR system that combines forecasting, clustering and a price-based demand projection engine to produce daily individualized DR recommendations and pricing policies for prosumers participating in the program. The results of this study can be useful for network operators and utilities that aim to develop targeted DR programs for groups of prosumers within flexible energy communities.
In Search of Deep Learning Architectures for Load Forecasting: A Comparative Analysis and the Impact of the Covid-19 Pandemic on Model Performance
Feb 25, 2023In power grids, short-term load forecasting (STLF) is crucial as it contributes to the optimization of their reliability, emissions, and costs, while it enables the participation of energy companies in the energy market. STLF is a challenging task, due to the complex demand of active and reactive power from multiple types of electrical loads and their dependence on numerous exogenous variables. Amongst them, special circumstances, such as the COVID-19 pandemic, can often be the reason behind distribution shifts of load series. This work conducts a comparative study of Deep Learning (DL) architectures, namely Neural Basis Expansion Analysis Time Series Forecasting (N-BEATS), Long Short-Term Memory (LSTM), and Temporal Convolutional Networks (TCN), with respect to forecasting accuracy and training sustainability, meanwhile examining their out-of-distribution generalization capabilities during the COVID-19 pandemic era. A Pattern Sequence Forecasting (PSF) model is used as baseline. The case study focuses on day-ahead forecasts for the Portuguese national 15-minute resolution net load time series. The results can be leveraged by energy companies and network operators (i) to reinforce their forecasting toolkit with state-of-the-art DL models; (ii) to become aware of the serious consequences of crisis events on model performance; (iii) as a high-level model evaluation, deployment, and sustainability guide within a smart grid context.
A comparative assessment of deep learning models for day-ahead load forecasting: Investigating key accuracy drivers
Feb 23, 2023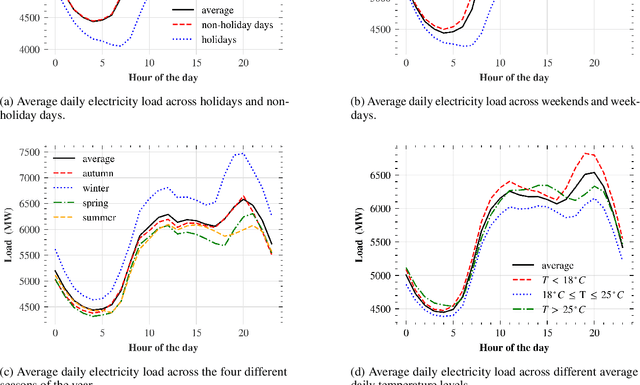
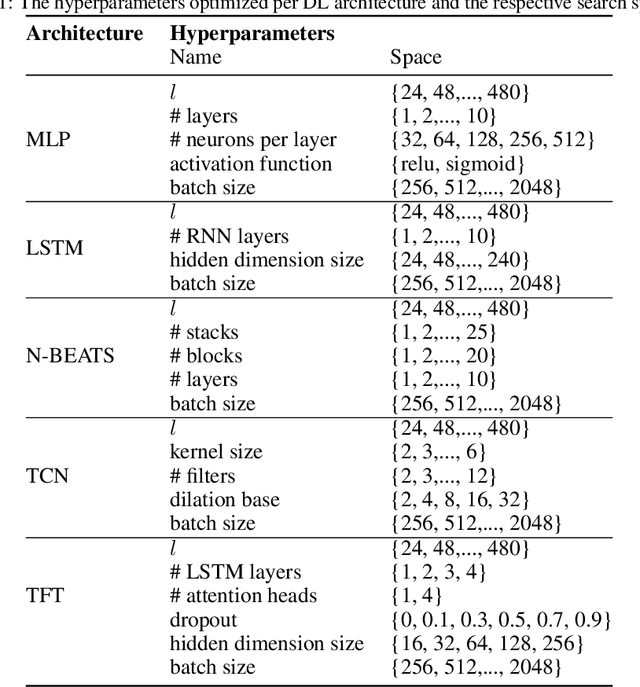
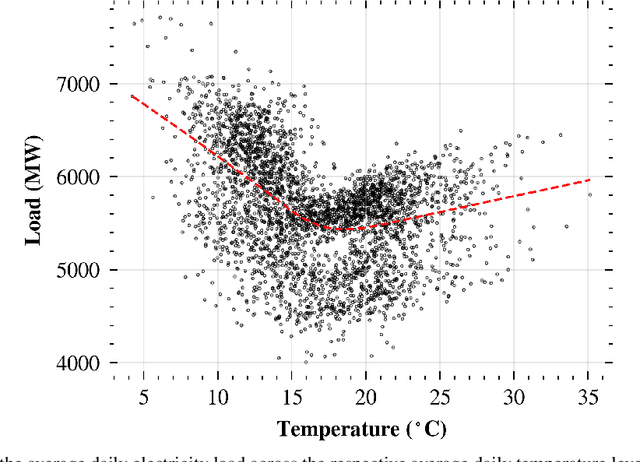
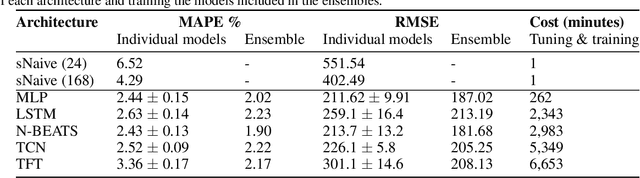
Short-term load forecasting (STLF) is vital for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. To that end, different forecasting methods have been proposed in the literature for day-ahead load forecasting, including a variety of deep learning models that are currently considered to achieve state-of-the-art performance. In order to compare the accuracy of such models, we focus on national net aggregated STLF and examine well-established autoregressive neural networks of indicative architectures, namely multi-layer perceptrons, N-BEATS, long short-term memory neural networks, and temporal convolutional networks, for the case of Portugal. To investigate the factors that affect the performance of each model and identify the most appropriate per case, we also conduct a post-hoc analysis, correlating forecast errors with key calendar and weather features. Our results indicate that N-BEATS consistently outperforms the rest of the examined deep learning models. Additionally, we find that external factors can significantly impact accuracy, affecting both the actual and relative performance of the models.