 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Day Ahead Market Prices Forecasting: A Focus on Short Training Set Windows
Jun 12, 2025This study investigates the performance of machine learning models in forecasting electricity Day-Ahead Market (DAM) prices using short historical training windows, with a focus on detecting seasonal trends and price spikes. We evaluate four models, namely LSTM with Feed Forward Error Correction (FFEC), XGBoost, LightGBM, and CatBoost, across three European energy markets (Greece, Belgium, Ireland) using feature sets derived from ENTSO-E forecast data. Training window lengths range from 7 to 90 days, allowing assessment of model adaptability under constrained data availability. Results indicate that LightGBM consistently achieves the highest forecasting accuracy and robustness, particularly with 45 and 60 day training windows, which balance temporal relevance and learning depth. Furthermore, LightGBM demonstrates superior detection of seasonal effects and peak price events compared to LSTM and other boosting models. These findings suggest that short-window training approaches, combined with boosting methods, can effectively support DAM forecasting in volatile, data-scarce environments.
A multi-dimensional unsupervised machine learning framework for clustering residential heat load profiles
Nov 11, 2024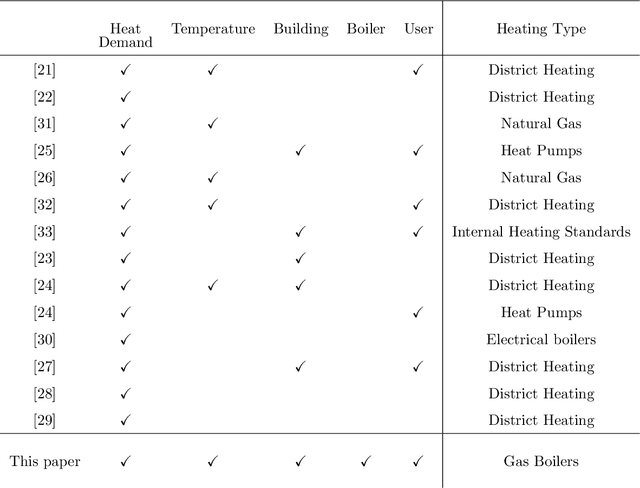


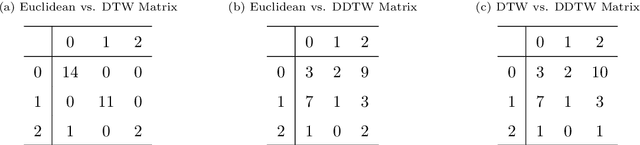
Central to achieving the energy transition, heating systems provide essential space heating and hot water in residential and industrial environments. A major challenge lies in effectively profiling large clusters of buildings to improve demand estimation and enable efficient Demand Response (DR) schemes. This paper addresses this challenge by introducing an unsupervised machine learning framework for clustering residential heating load profiles, focusing on natural gas space heating and hot water preparation boilers. The profiles are analyzed across five dimensions: boiler usage, heating demand, weather conditions, building characteristics, and user behavior. We apply three distance metrics: Euclidean Distance (ED), Dynamic Time Warping (DTW), and Derivative Dynamic Time Warping (DDTW), and evaluate their performance using established clustering indices. The proposed method is assessed considering 29 residential buildings in Greece equipped with smart meters throughout a calendar heating season (i.e., 210 days). Results indicate that DTW is the most suitable metric, uncovering strong correlations between boiler usage, heat demand, and temperature, while ED highlights broader interrelations across dimensions and DDTW proves less effective, resulting in weaker clusters. These findings offer key insights into heating load behavior, establishing a solid foundation for developing more targeted and effective DR programs.
Data-driven building energy efficiency prediction based on envelope heat losses using physics-informed neural networks
Nov 14, 2023The analytical prediction of building energy performance in residential buildings based on the heat losses of its individual envelope components is a challenging task. It is worth noting that this field is still in its infancy, with relatively limited research conducted in this specific area to date, especially when it comes for data-driven approaches. In this paper we introduce a novel physics-informed neural network model for addressing this problem. Through the employment of unexposed datasets that encompass general building information, audited characteristics, and heating energy consumption, we feed the deep learning model with general building information, while the model's output consists of the structural components and several thermal properties that are in fact the basic elements of an energy performance certificate (EPC). On top of this neural network, a function, based on physics equations, calculates the energy consumption of the building based on heat losses and enhances the loss function of the deep learning model. This methodology is tested on a real case study for 256 buildings located in Riga, Latvia. Our investigation comes up with promising results in terms of prediction accuracy, paving the way for automated, and data-driven energy efficiency performance prediction based on basic properties of the building, contrary to exhaustive energy efficiency audits led by humans, which are the current status quo.
A Machine Learning-Based Framework for Clustering Residential Electricity Load Profiles to Enhance Demand Response Programs
Oct 31, 2023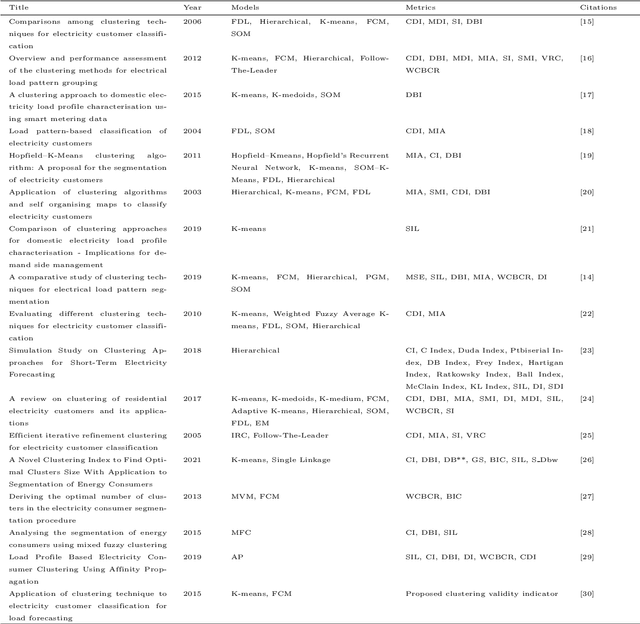

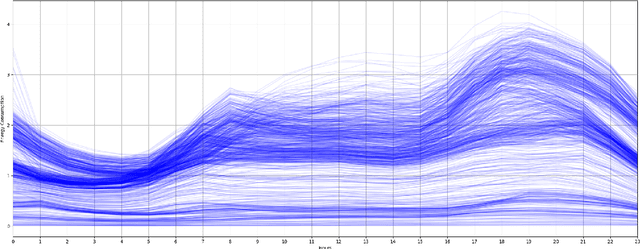
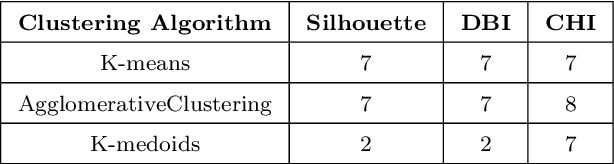
Load shapes derived from smart meter data are frequently employed to analyze daily energy consumption patterns, particularly in the context of applications like Demand Response (DR). Nevertheless, one of the most important challenges to this endeavor lies in identifying the most suitable consumer clusters with similar consumption behaviors. In this paper, we present a novel machine learning based framework in order to achieve optimal load profiling through a real case study, utilizing data from almost 5000 households in London. Four widely used clustering algorithms are applied specifically K-means, K-medoids, Hierarchical Agglomerative Clustering and Density-based Spatial Clustering. An empirical analysis as well as multiple evaluation metrics are leveraged to assess those algorithms. Following that, we redefine the problem as a probabilistic classification one, with the classifier emulating the behavior of a clustering algorithm,leveraging Explainable AI (xAI) to enhance the interpretability of our solution. According to the clustering algorithm analysis the optimal number of clusters for this case is seven. Despite that, our methodology shows that two of the clusters, almost 10\% of the dataset, exhibit significant internal dissimilarity and thus it splits them even further to create nine clusters in total. The scalability and versatility of our solution makes it an ideal choice for power utility companies aiming to segment their users for creating more targeted Demand Response programs.