 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning-Based Framework for Clustering Residential Electricity Load Profiles to Enhance Demand Response Programs
Paper and Code
Oct 31, 2023

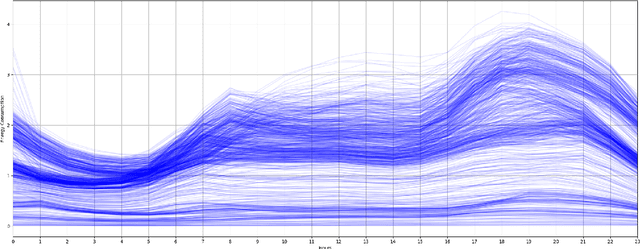
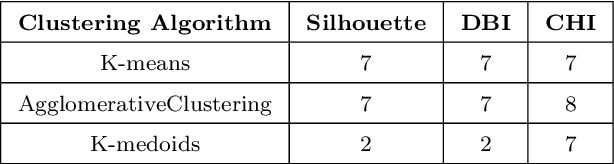
Load shapes derived from smart meter data are frequently employed to analyze daily energy consumption patterns, particularly in the context of applications like Demand Response (DR). Nevertheless, one of the most important challenges to this endeavor lies in identifying the most suitable consumer clusters with similar consumption behaviors. In this paper, we present a novel machine learning based framework in order to achieve optimal load profiling through a real case study, utilizing data from almost 5000 households in London. Four widely used clustering algorithms are applied specifically K-means, K-medoids, Hierarchical Agglomerative Clustering and Density-based Spatial Clustering. An empirical analysis as well as multiple evaluation metrics are leveraged to assess those algorithms. Following that, we redefine the problem as a probabilistic classification one, with the classifier emulating the behavior of a clustering algorithm,leveraging Explainable AI (xAI) to enhance the interpretability of our solution. According to the clustering algorithm analysis the optimal number of clusters for this case is seven. Despite that, our methodology shows that two of the clusters, almost 10\% of the dataset, exhibit significant internal dissimilarity and thus it splits them even further to create nine clusters in total. The scalability and versatility of our solution makes it an ideal choice for power utility companies aiming to segment their users for creating more targeted Demand Response programs.