 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning for day-ahead load forecasting: a case study on European national electricity demand time series
Oct 24, 2023Short-term load forecasting (STLF) is crucial for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. Various forecasting approaches have been proposed for improving STLF, including neural network (NN) models which are trained using data from multiple electricity demand series that may not necessary include the target series. In the present study, we investigate the performance of this special case of STLF, called transfer learning (TL), by considering a set of 27 time series that represent the national day-ahead electricity demand of indicative European countries. We employ a popular and easy-to-implement NN model and perform a clustering analysis to identify similar patterns among the series and assist TL. In this context, two different TL approaches, with and without the clustering step, are compiled and compared against each other as well as a typical NN training setup. Our results demonstrate that TL can outperform the conventional approach, especially when clustering techniques are considered.
A comparative assessment of deep learning models for day-ahead load forecasting: Investigating key accuracy drivers
Feb 23, 2023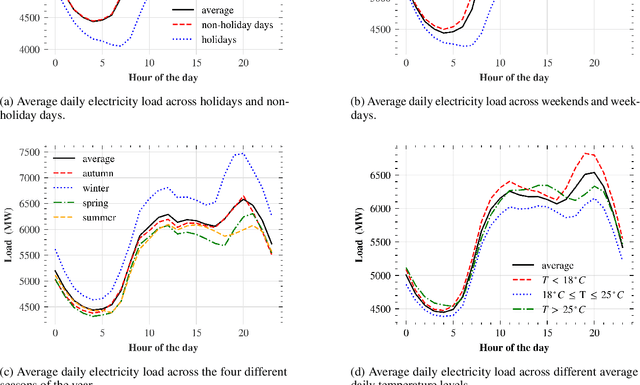
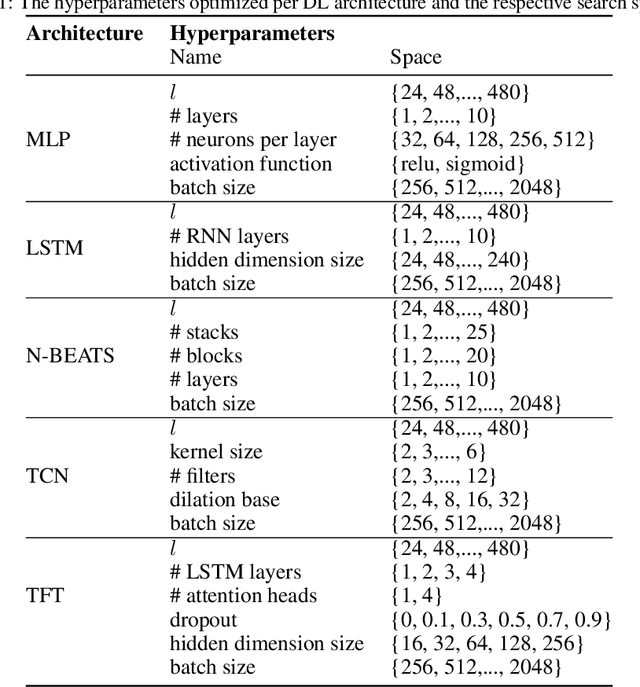
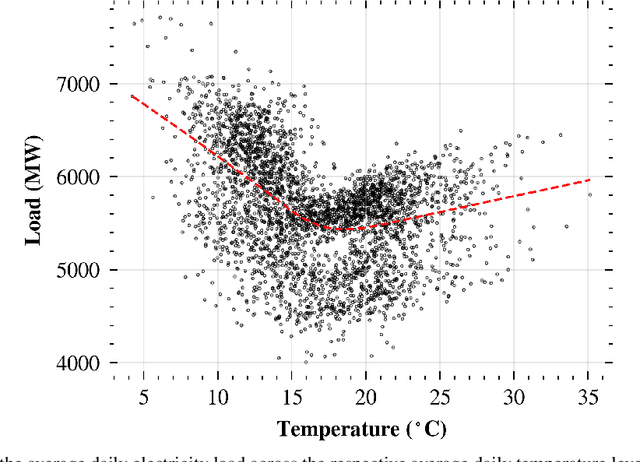
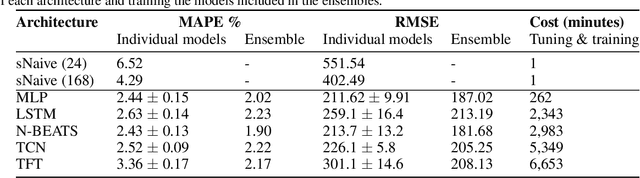
Short-term load forecasting (STLF) is vital for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. To that end, different forecasting methods have been proposed in the literature for day-ahead load forecasting, including a variety of deep learning models that are currently considered to achieve state-of-the-art performance. In order to compare the accuracy of such models, we focus on national net aggregated STLF and examine well-established autoregressive neural networks of indicative architectures, namely multi-layer perceptrons, N-BEATS, long short-term memory neural networks, and temporal convolutional networks, for the case of Portugal. To investigate the factors that affect the performance of each model and identify the most appropriate per case, we also conduct a post-hoc analysis, correlating forecast errors with key calendar and weather features. Our results indicate that N-BEATS consistently outperforms the rest of the examined deep learning models. Additionally, we find that external factors can significantly impact accuracy, affecting both the actual and relative performance of the models.
Exploring the representativeness of the M5 competition data
Mar 04, 2021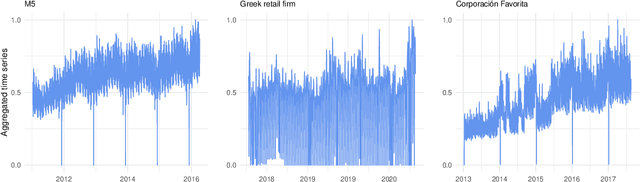

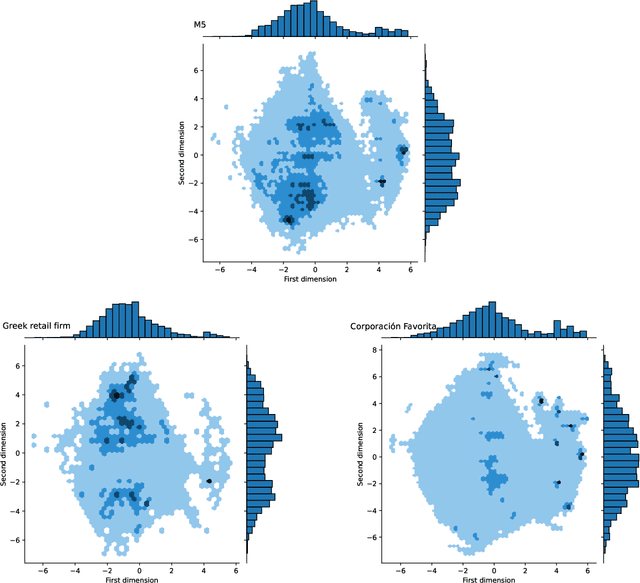
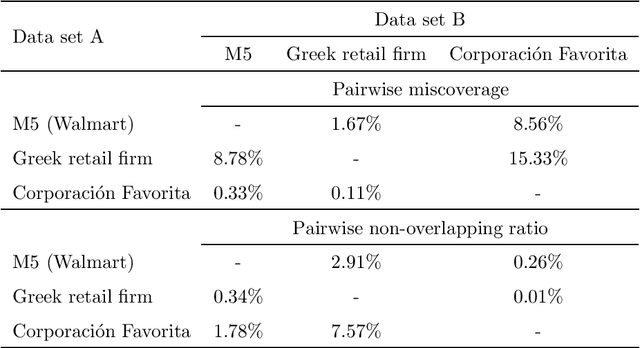
The main objective of the M5 competition, which focused on forecasting the hierarchical unit sales of Walmart, was to evaluate the accuracy and uncertainty of forecasting methods in the field in order to identify best practices and highlight their practical implications. However, whether the findings of the M5 competition can be generalized and exploited by retail firms to better support their decisions and operation depends on the extent to which the M5 data is representative of the reality, i.e., sufficiently represent the unit sales data of retailers that operate in different regions, sell different types of products, and consider different marketing strategies. To answer this question, we analyze the characteristics of the M5 time series and compare them with those of two grocery retailers, namely Corporaci\'on Favorita and a major Greek supermarket chain, using feature spaces. Our results suggest that there are only small discrepancies between the examined data sets, supporting the representativeness of the M5 data.
Model selection in reconciling hierarchical time series
Oct 29, 2020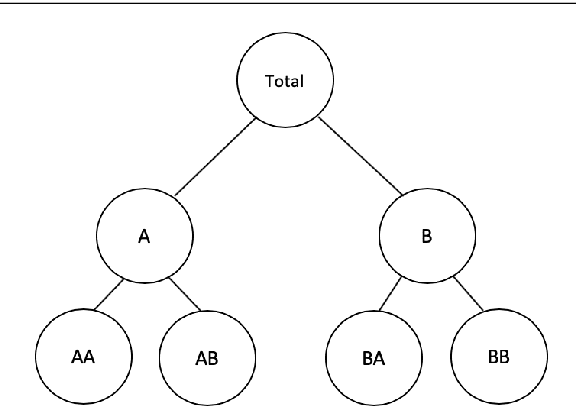
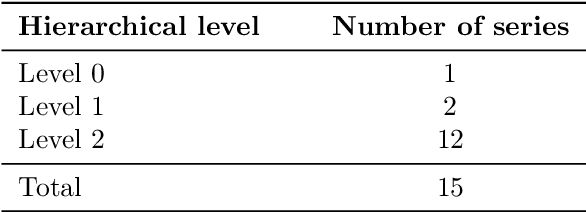
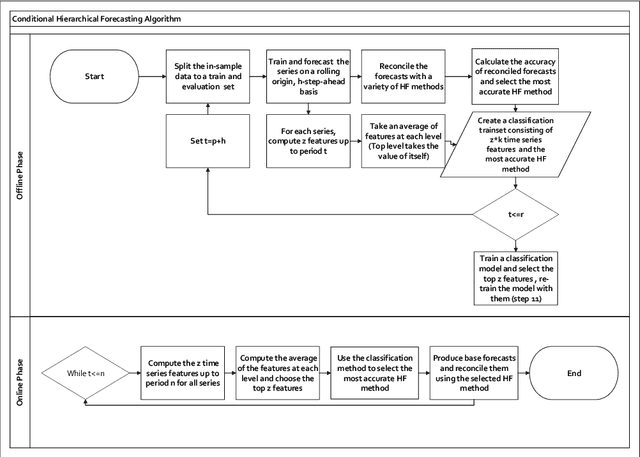
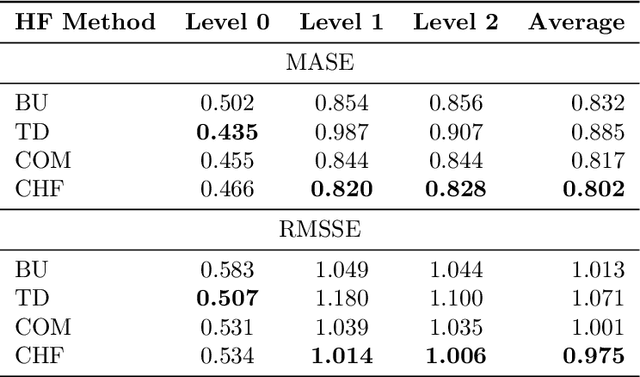
Model selection has been proven an effective strategy for improving accuracy in time series forecasting applications. However, when dealing with hierarchical time series, apart from selecting the most appropriate forecasting model, forecasters have also to select a suitable method for reconciling the base forecasts produced for each series to make sure they are coherent. Although some hierarchical forecasting methods like minimum trace are strongly supported both theoretically and empirically for reconciling the base forecasts, there are still circumstances under which they might not produce the most accurate results, being outperformed by other methods. In this paper we propose an approach for dynamically selecting the most appropriate hierarchical forecasting method and succeeding better forecasting accuracy along with coherence. The approach, to be called conditional hierarchical forecasting, is based on Machine Learning classification methods and uses time series features as leading indicators for performing the selection for each hierarchy examined considering a variety of alternatives. Our results suggest that conditional hierarchical forecasting leads to significantly more accurate forecasts than standard approaches, especially at lower hierarchical levels.
Hierarchical forecast reconciliation with machine learning
Jun 03, 2020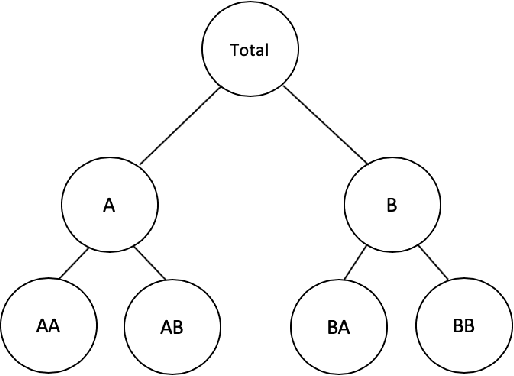

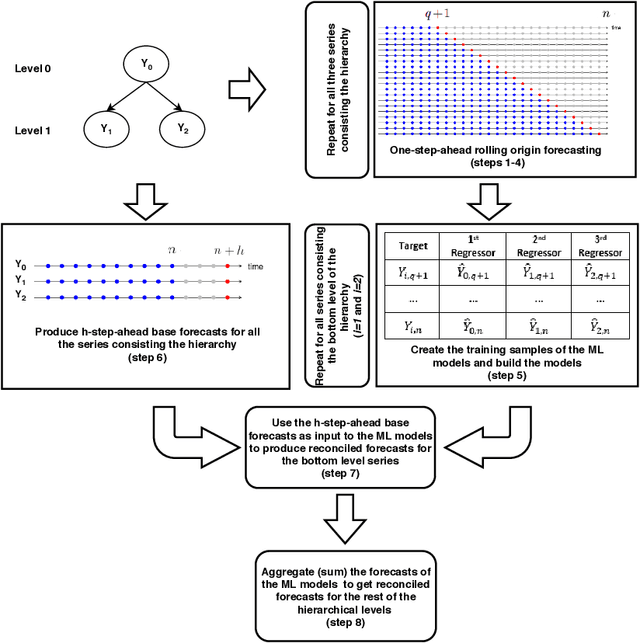

Hierarchical forecasting methods have been widely used to support aligned decision-making by providing coherent forecasts at different aggregation levels. Traditional hierarchical forecasting approaches, such as the bottom-up and top-down methods, focus on a particular aggregation level to anchor the forecasts. During the past decades, these have been replaced by a variety of linear combination approaches that exploit information from the complete hierarchy to produce more accurate forecasts. However, the performance of these combination methods depends on the particularities of the examined series and their relationships. This paper proposes a novel hierarchical forecasting approach based on machine learning that deals with these limitations in three important ways. First, the proposed method allows for a non-linear combination of the base forecasts, thus being more general than the linear approaches. Second, it structurally combines the objectives of improved post-sample empirical forecasting accuracy and coherence. Finally, due to its non-linear nature, our approach selectively combines the base forecasts in a direct and automated way without requiring that the complete information must be used for producing reconciled forecasts for each series and level. The proposed method is evaluated both in terms of accuracy and bias using two different data sets coming from the tourism and retail industries. Our results suggest that the proposed method gives superior point forecasts than existing approaches, especially when the series comprising the hierarchy are not characterized by the same patterns.