 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Schrödinger Bridge on Graphs
Feb 04, 2026Transportation on graphs is a fundamental challenge across many domains, where decisions must respect topological and operational constraints. Despite the need for actionable policies, existing graph-transport methods lack this expressivity. They rely on restrictive assumptions, fail to generalize across sparse topologies, and scale poorly with graph size and time horizon. To address these issues, we introduce Generalized Schrödinger Bridge on Graphs (GSBoG), a novel scalable data-driven framework for learning executable controlled continuous-time Markov chain (CTMC) policies on arbitrary graphs under state cost augmented dynamics. Notably, GSBoG learns trajectory-level policies, avoiding dense global solvers and thereby enhancing scalability. This is achieved via a likelihood optimization approach, satisfying the endpoint marginals, while simultaneously optimizing intermediate behavior under state-dependent running costs. Extensive experimentation on challenging real-world graph topologies shows that GSBoG reliably learns accurate, topology-respecting policies while optimizing application-specific intermediate state costs, highlighting its broad applicability and paving new avenues for cost-aware dynamical transport on general graphs.
Meta-Learning Online Dynamics Model Adaptation in Off-Road Autonomous Driving
Apr 23, 2025
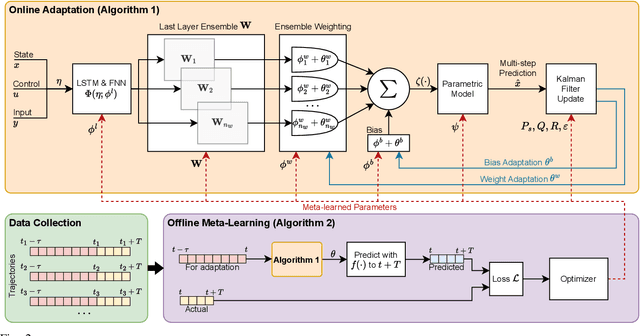

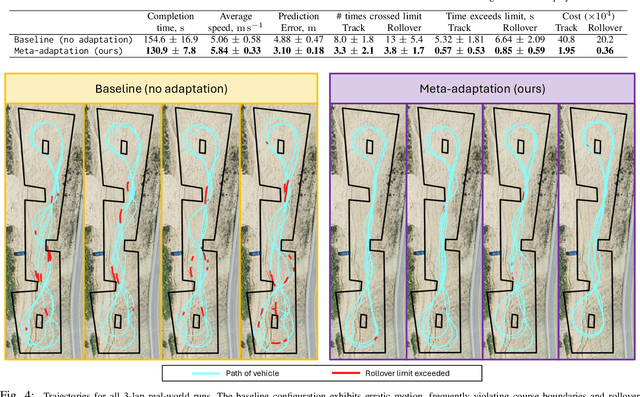
High-speed off-road autonomous driving presents unique challenges due to complex, evolving terrain characteristics and the difficulty of accurately modeling terrain-vehicle interactions. While dynamics models used in model-based control can be learned from real-world data, they often struggle to generalize to unseen terrain, making real-time adaptation essential. We propose a novel framework that combines a Kalman filter-based online adaptation scheme with meta-learned parameters to address these challenges. Offline meta-learning optimizes the basis functions along which adaptation occurs, as well as the adaptation parameters, while online adaptation dynamically adjusts the onboard dynamics model in real time for model-based control. We validate our approach through extensive experiments, including real-world testing on a full-scale autonomous off-road vehicle, demonstrating that our method outperforms baseline approaches in prediction accuracy, performance, and safety metrics, particularly in safety-critical scenarios. Our results underscore the effectiveness of meta-learned dynamics model adaptation, advancing the development of reliable autonomous systems capable of navigating diverse and unseen environments. Video is available at: https://youtu.be/cCKHHrDRQEA
Improving Model Predictive Path Integral using Covariance Steering
Sep 24, 2021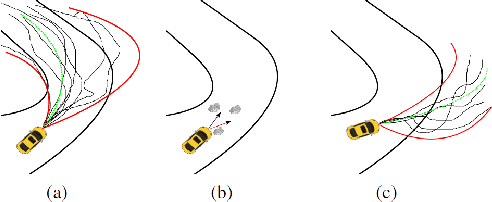
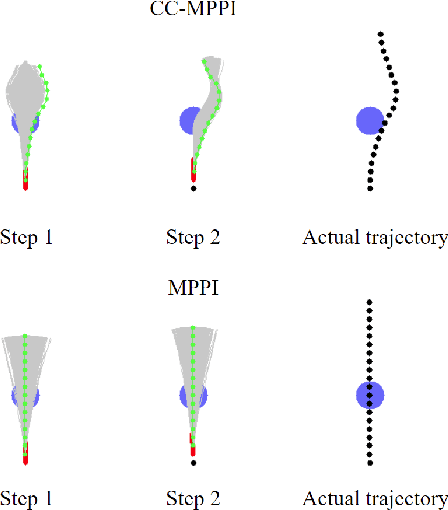

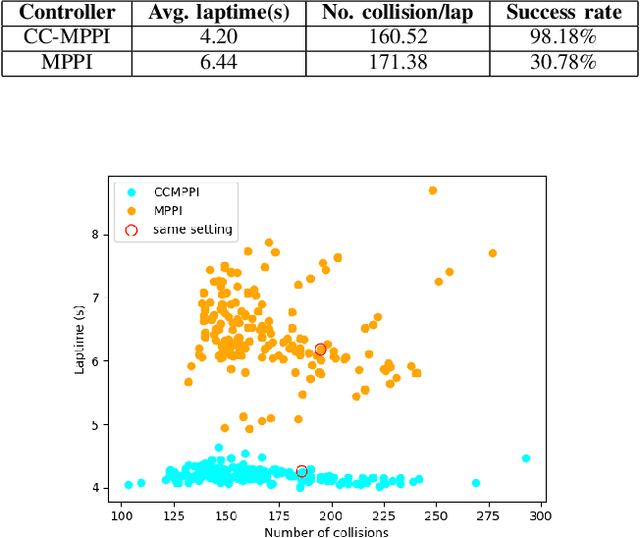
This paper presents a novel control approach for autonomous systems operating under uncertainty. We combine Model Predictive Path Integral (MPPI) control with Covariance Steering (CS) theory to obtain a robust controller for general nonlinear systems. The proposed Covariance-Controlled Model Predictive Path Integral (CC-MPPI) controller addresses the performance degradation observed in some MPPI implementations owing to unexpected disturbances and uncertainties. Namely, in cases where the environment changes too fast or the simulated dynamics during the MPPI rollouts do not capture the noise and uncertainty in the actual dynamics, the baseline MPPI implementation may lead to divergence. The proposed CC-MPPI controller avoids divergence by controlling the dispersion of the rollout trajectories at the end of the prediction horizon. Furthermore, the CC-MPPI has adjustable trajectory sampling distributions that can be changed according to the environment to achieve efficient sampling. Numerical examples using a ground vehicle navigating in challenging environments demonstrate the proposed approach.
Robustifying Reinforcement Learning Policies with $\mathcal{L}_1$ Adaptive Control
Jun 04, 2021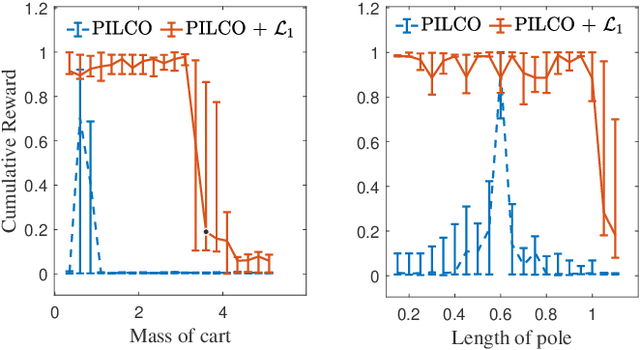
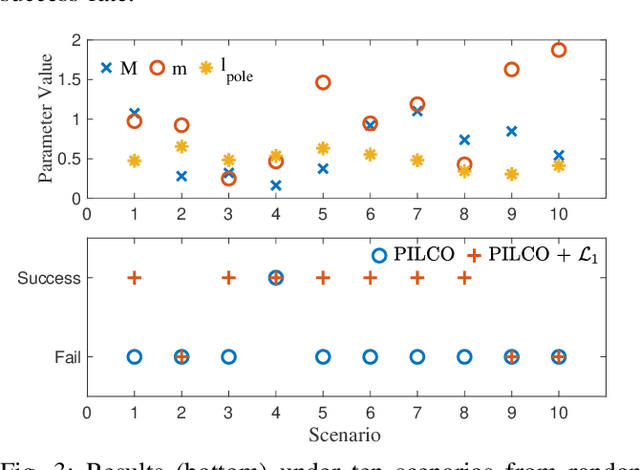
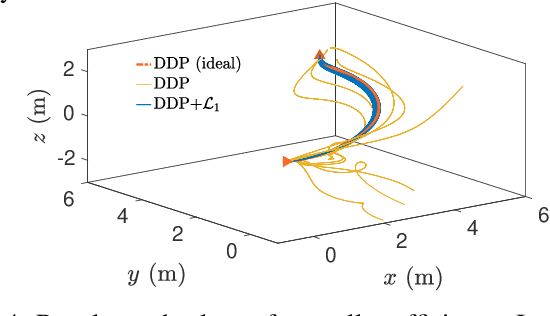
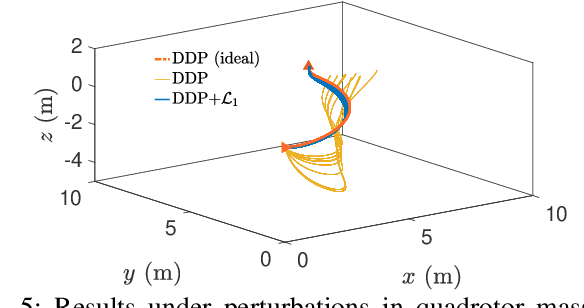
A reinforcement learning (RL) policy trained in a nominal environment could fail in a new/perturbed environment due to the existence of dynamic variations. Existing robust methods try to obtain a fixed policy for all envisioned dynamic variation scenarios through robust or adversarial training. These methods could lead to conservative performance due to emphasis on the worst case, and often involve tedious modifications to the training environment. We propose an approach to robustifying a pre-trained non-robust RL policy with $\mathcal{L}_1$ adaptive control. Leveraging the capability of an $\mathcal{L}_1$ control law in the fast estimation of and active compensation for dynamic variations, our approach can significantly improve the robustness of an RL policy trained in a standard (i.e., non-robust) way, either in a simulator or in the real world. Numerical experiments are provided to validate the efficacy of the proposed approach.
Exploring the representativeness of the M5 competition data
Mar 04, 2021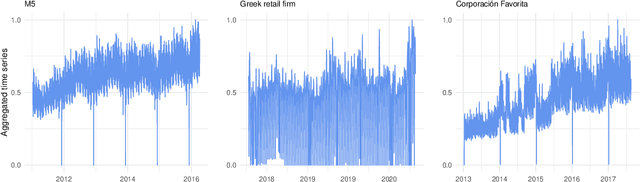

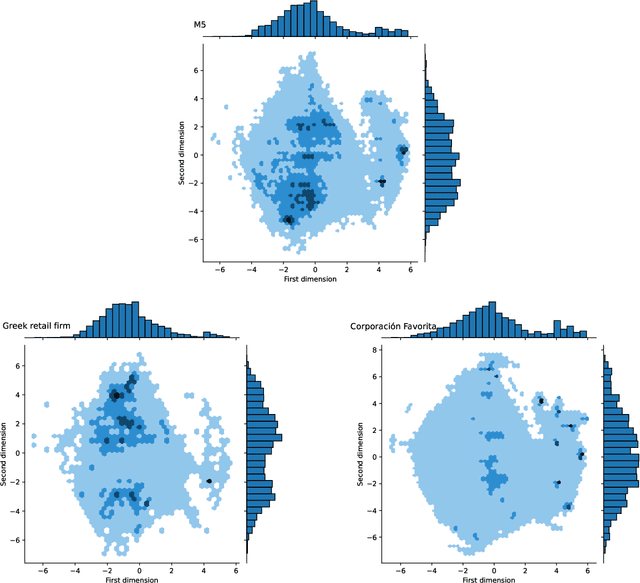
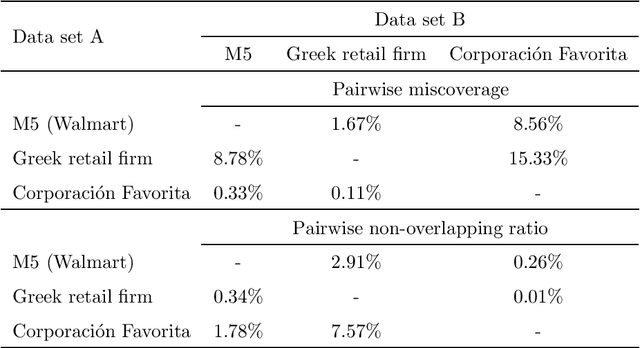
The main objective of the M5 competition, which focused on forecasting the hierarchical unit sales of Walmart, was to evaluate the accuracy and uncertainty of forecasting methods in the field in order to identify best practices and highlight their practical implications. However, whether the findings of the M5 competition can be generalized and exploited by retail firms to better support their decisions and operation depends on the extent to which the M5 data is representative of the reality, i.e., sufficiently represent the unit sales data of retailers that operate in different regions, sell different types of products, and consider different marketing strategies. To answer this question, we analyze the characteristics of the M5 time series and compare them with those of two grocery retailers, namely Corporaci\'on Favorita and a major Greek supermarket chain, using feature spaces. Our results suggest that there are only small discrepancies between the examined data sets, supporting the representativeness of the M5 data.
Autonomous Hybrid Ground/Aerial Mobility in Unknown Environments
Sep 11, 2020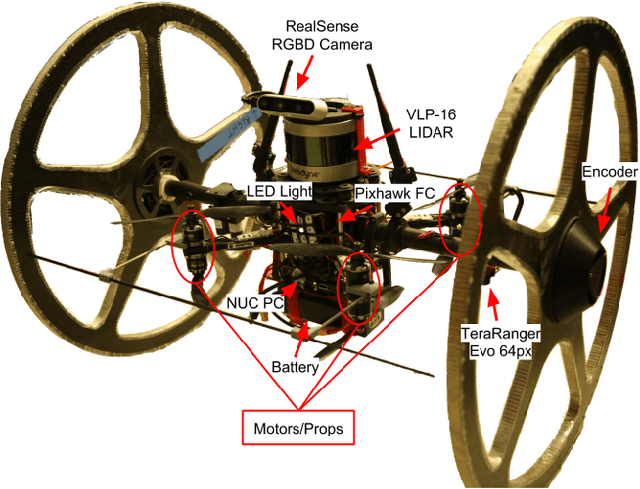

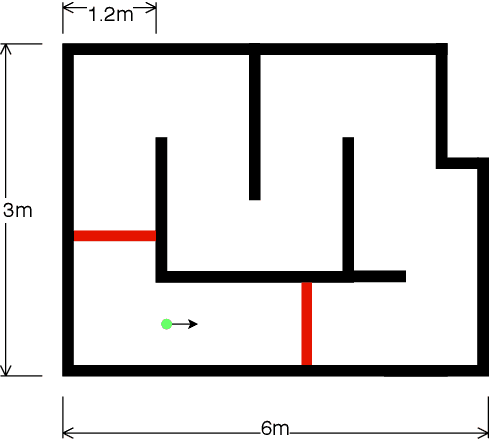
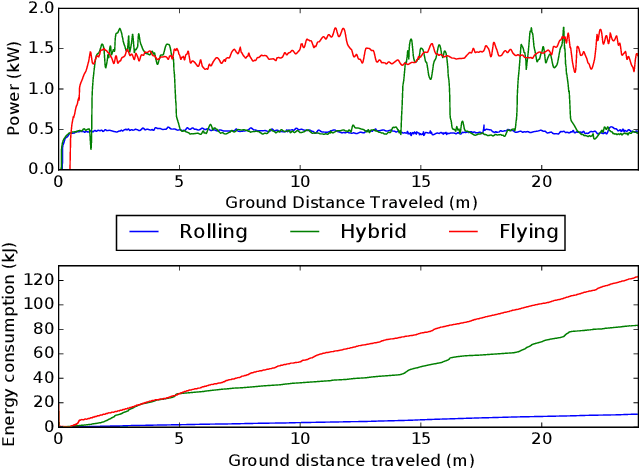
Hybrid ground and aerial vehicles can possess distinct advantages over ground-only or flight-only designs in terms of energy savings and increased mobility. In this work we outline our unified framework for controls, planning, and autonomy of hybrid ground/air vehicles. Our contribution is three-fold: 1) We develop a control scheme for the control of passive two-wheeled hybrid ground/aerial vehicles. 2) We present a unified planner for both rolling and flying by leveraging differential flatness mappings. 3) We conduct experiments leveraging mapping and global planning for hybrid mobility in unknown environments, showing that hybrid mobility uses up to five times less energy than flying only.
$\mathcal{RL}_1$-$\mathcal{GP}$: Safe Simultaneous Learning and Control
Sep 08, 2020
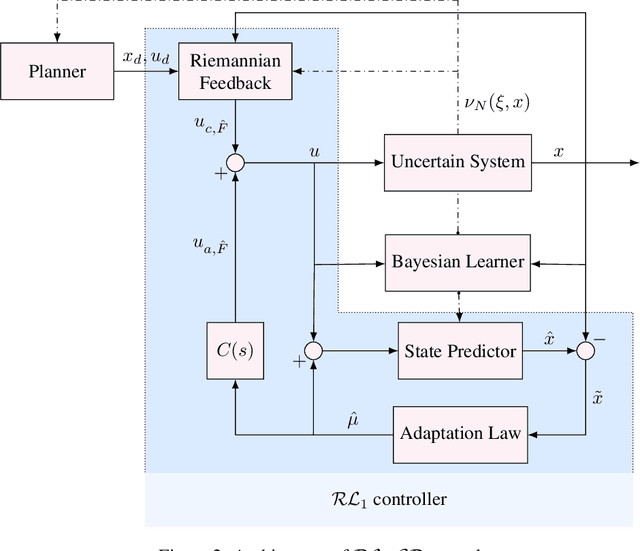
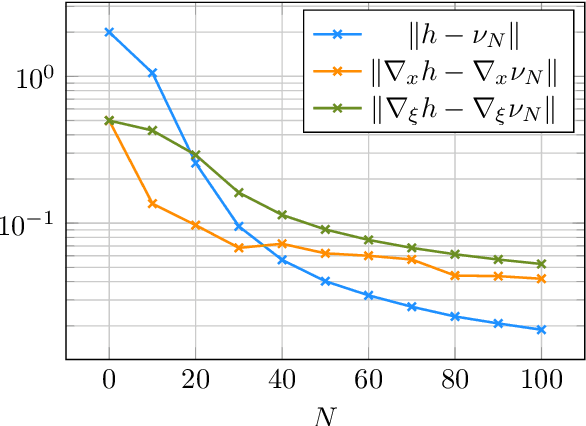
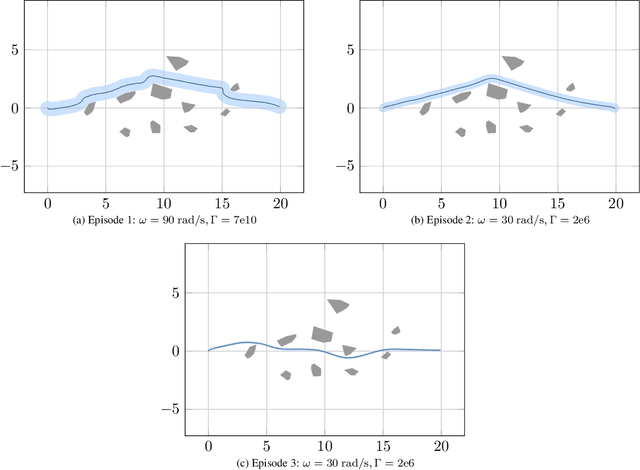
We present $\mathcal{RL}_1$-$\mathcal{GP}$, a control framework that enables safe simultaneous learning and control for systems subject to uncertainties. The two main constituents are Riemannian energy $\mathcal{L}_1$ ($\mathcal{RL}_1$) control and Bayesian learning in the form of Gaussian process (GP) regression. The $\mathcal{RL}_1$ controller ensures that control objectives are met while providing safety certificates. Furthermore, $\mathcal{RL}_1$-$\mathcal{GP}$ incorporates any available data into a GP model of uncertainties, which improves performance and enables the motion planner to achieve optimality safely. This way, the safe operation of the system is always guaranteed, even during the learning transients. We provide a few illustrative examples for the safe learning and control of planar quadrotor systems in a variety of environments.
Forward-Backward RRT: Branched Sampled FBSDEs for Stochastic Optimal Control
Jun 22, 2020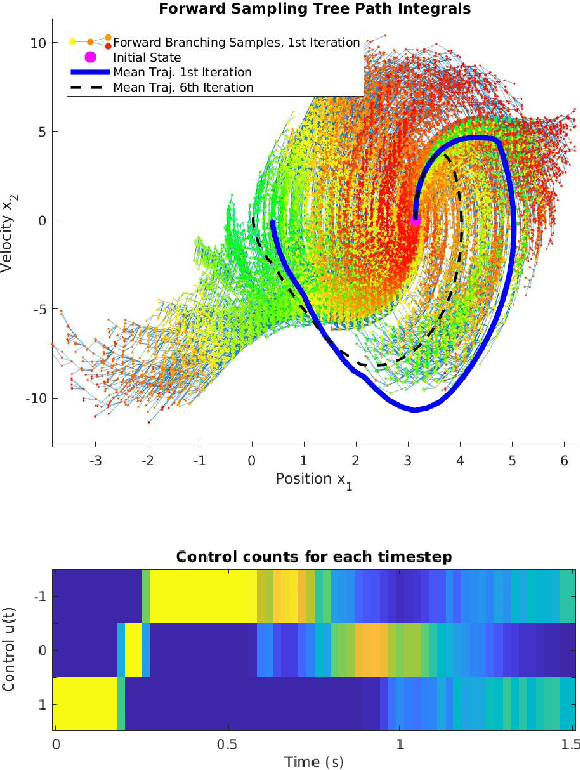
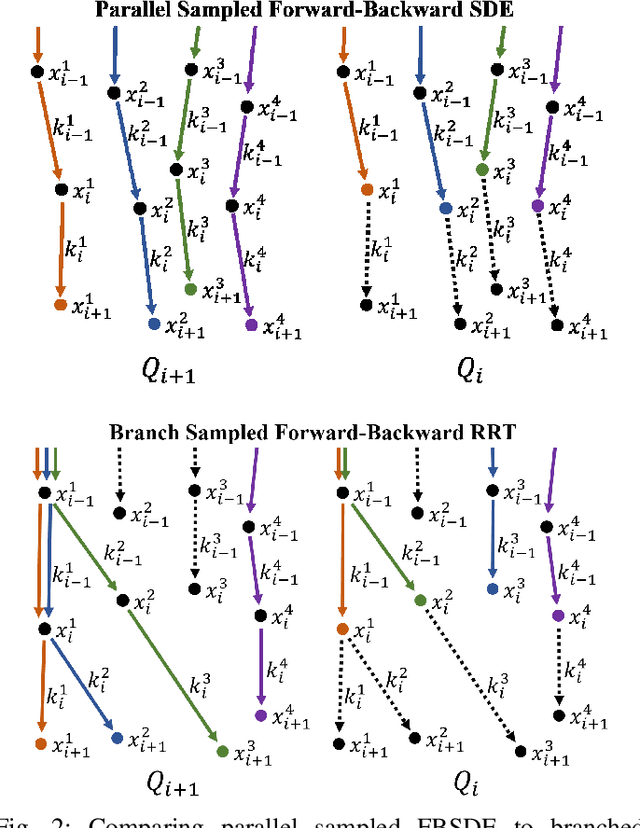
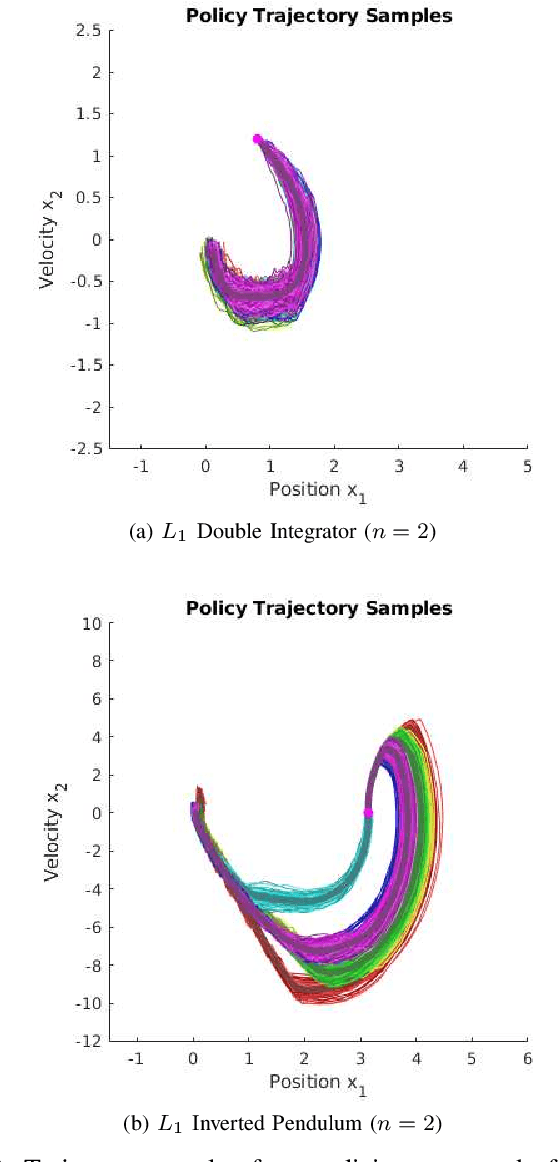
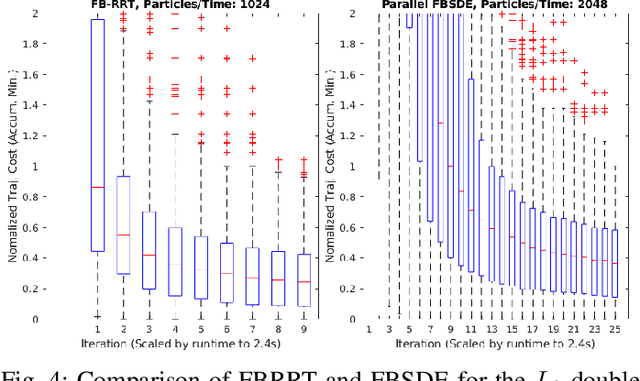
We propose a numerical method to solve forward-backward stochastic differential equations (FBSDE) arising in stochastic optimal control problems. Instead of sampling forward paths independently, we demonstrate how a rapidly-exploring random tree (RRT) method can be utilized for the forward integration pass, as long as the controlled drift terms are appropriately compensated in the backward integration pass. We show how a value function approximation is produced by solving a series of function approximation problems backwards in time along the edges of the constructed RRT tree. We employ a local entropy-weighted least squares Monte Carlo (LSMC) method to concentrate function approximation accuracy in regions most likely to be visited by optimally controlled trajectories. We demonstrate the proposed method and evaluate it on two nonlinear stochastic optimal control problems with non-quadratic running costs, showing that it can greatly improve convergence over previous FBSDE numerical solution methods.
Agile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning
Sep 10, 2018
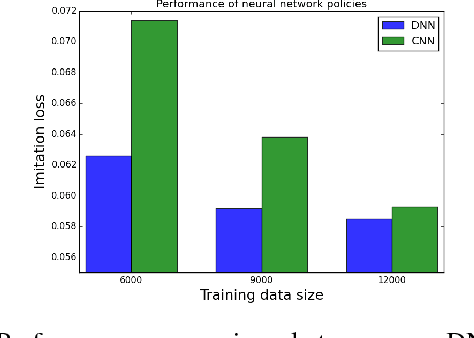
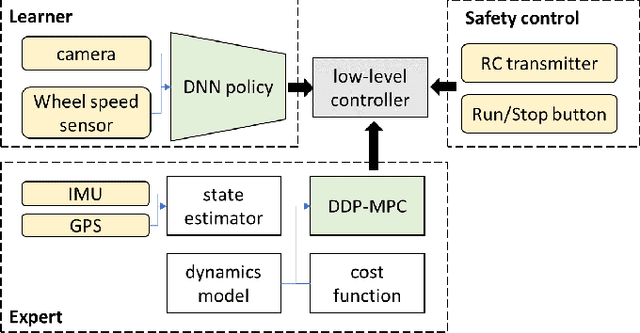

We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands. Compared with recent approaches to similar tasks, our method requires neither state estimation nor on-the-fly planning to navigate the vehicle. Our approach relies on, and experimentally validates, recent imitation learning theory. Empirically, we show that policies trained with online imitation learning overcome well-known challenges related to covariate shift and generalize better than policies trained with batch imitation learning. Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.
Propagating Uncertainty through the tanh Function with Application to Reservoir Computing
Jun 25, 2018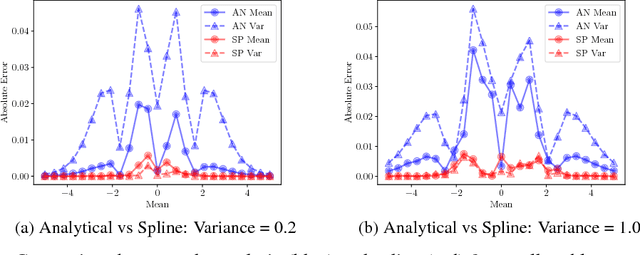
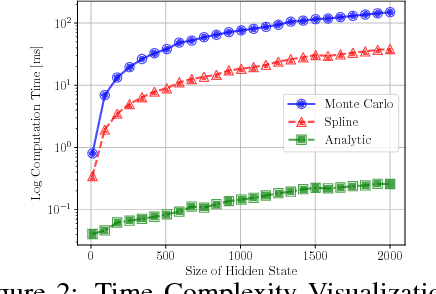
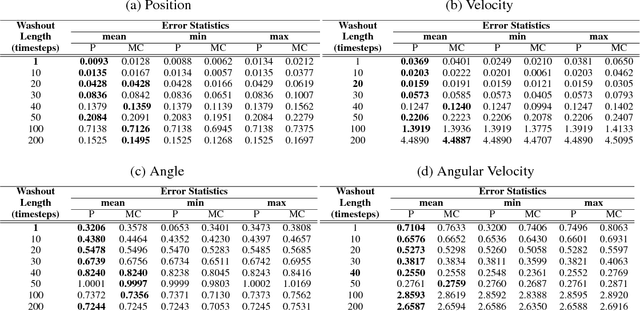
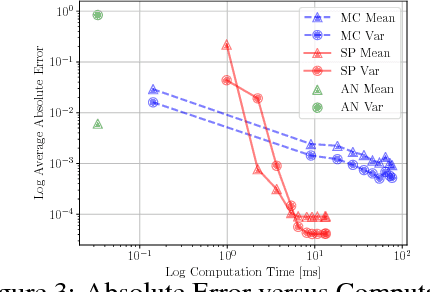
Many neural networks use the tanh activation function, however when given a probability distribution as input, the problem of computing the output distribution in neural networks with tanh activation has not yet been addressed. One important example is the initialization of the echo state network in reservoir computing, where random initialization of the reservoir requires time to wash out the initial conditions, thereby wasting precious data and computational resources. Motivated by this problem, we propose a novel solution utilizing a moment based approach to propagate uncertainty through an Echo State Network to reduce the washout time. In this work, we contribute two new methods to propagate uncertainty through the tanh activation function and propose the Probabilistic Echo State Network (PESN), a method that is shown to have better average performance than deterministic Echo State Networks given the random initialization of reservoir states. Additionally we test single and multi-step uncertainty propagation of our method on two regression tasks and show that we are able to recover similar means and variances as computed by Monte-Carlo simulations.