 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning
Sep 10, 2018
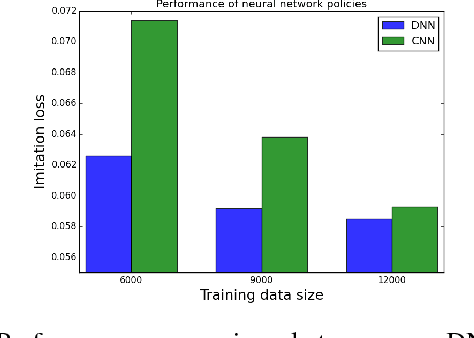
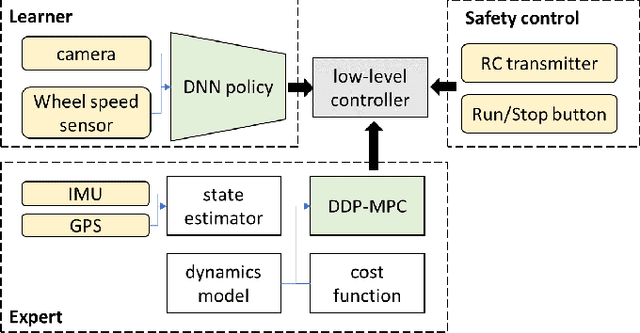

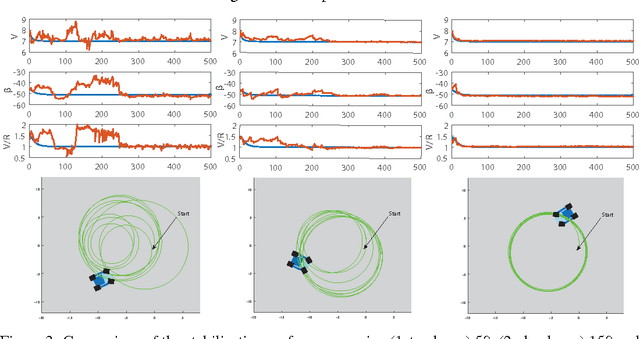
We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands. Compared with recent approaches to similar tasks, our method requires neither state estimation nor on-the-fly planning to navigate the vehicle. Our approach relies on, and experimentally validates, recent imitation learning theory. Empirically, we show that policies trained with online imitation learning overcome well-known challenges related to covariate shift and generalize better than policies trained with batch imitation learning. Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.
Propagating Uncertainty through the tanh Function with Application to Reservoir Computing
Jun 25, 2018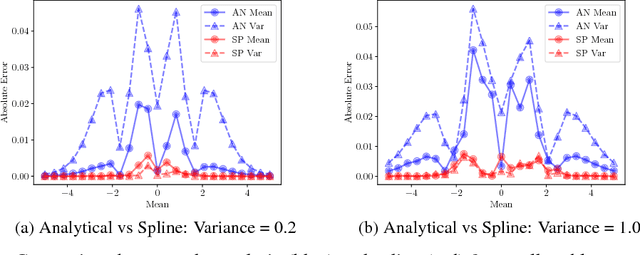
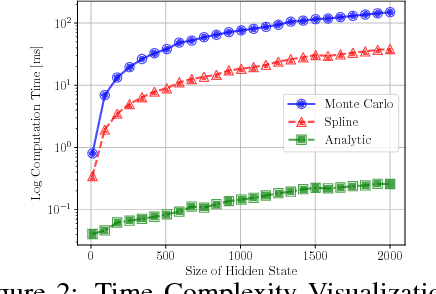
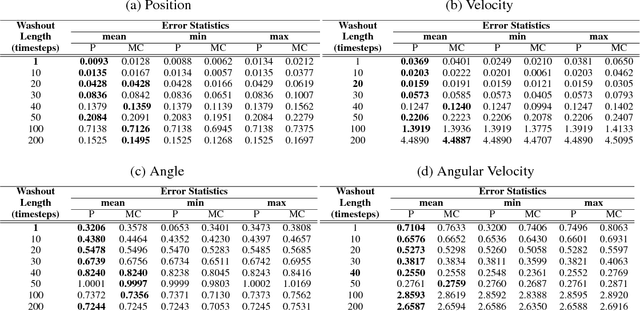
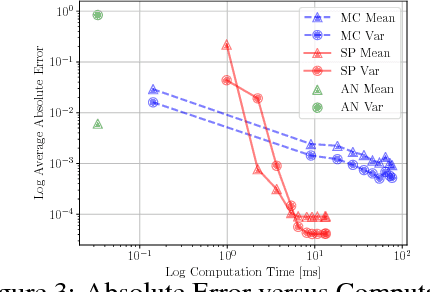
Many neural networks use the tanh activation function, however when given a probability distribution as input, the problem of computing the output distribution in neural networks with tanh activation has not yet been addressed. One important example is the initialization of the echo state network in reservoir computing, where random initialization of the reservoir requires time to wash out the initial conditions, thereby wasting precious data and computational resources. Motivated by this problem, we propose a novel solution utilizing a moment based approach to propagate uncertainty through an Echo State Network to reduce the washout time. In this work, we contribute two new methods to propagate uncertainty through the tanh activation function and propose the Probabilistic Echo State Network (PESN), a method that is shown to have better average performance than deterministic Echo State Networks given the random initialization of reservoir states. Additionally we test single and multi-step uncertainty propagation of our method on two regression tasks and show that we are able to recover similar means and variances as computed by Monte-Carlo simulations.
Learning from Conditional Distributions via Dual Embeddings
Dec 31, 2016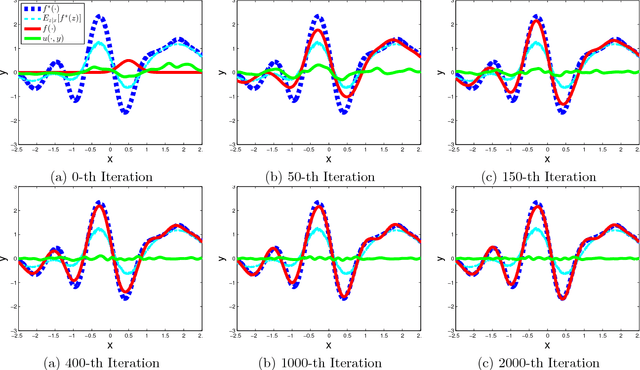
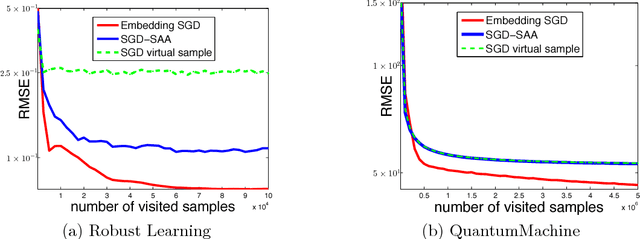
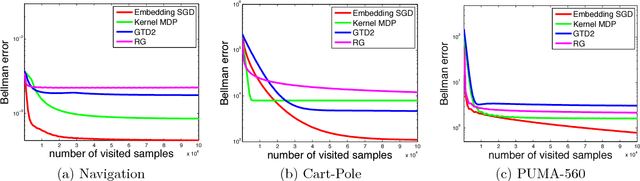
Many machine learning tasks, such as learning with invariance and policy evaluation in reinforcement learning, can be characterized as problems of learning from conditional distributions. In such problems, each sample $x$ itself is associated with a conditional distribution $p(z|x)$ represented by samples $\{z_i\}_{i=1}^M$, and the goal is to learn a function $f$ that links these conditional distributions to target values $y$. These learning problems become very challenging when we only have limited samples or in the extreme case only one sample from each conditional distribution. Commonly used approaches either assume that $z$ is independent of $x$, or require an overwhelmingly large samples from each conditional distribution. To address these challenges, we propose a novel approach which employs a new min-max reformulation of the learning from conditional distribution problem. With such new reformulation, we only need to deal with the joint distribution $p(z,x)$. We also design an efficient learning algorithm, Embedding-SGD, and establish theoretical sample complexity for such problems. Finally, our numerical experiments on both synthetic and real-world datasets show that the proposed approach can significantly improve over the existing algorithms.
Adaptive Probabilistic Trajectory Optimization via Efficient Approximate Inference
Sep 11, 2016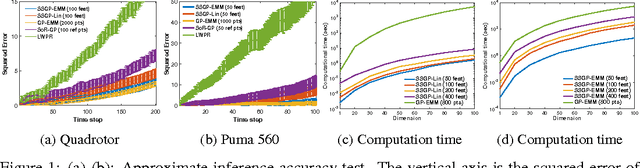
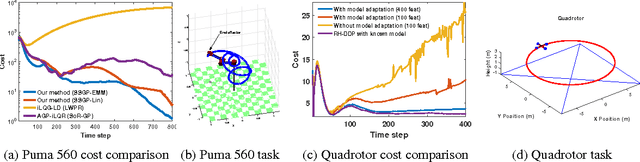
Robotic systems must be able to quickly and robustly make decisions when operating in uncertain and dynamic environments. While Reinforcement Learning (RL) can be used to compute optimal policies with little prior knowledge about the environment, it suffers from slow convergence. An alternative approach is Model Predictive Control (MPC), which optimizes policies quickly, but also requires accurate models of the system dynamics and environment. In this paper we propose a new approach, adaptive probabilistic trajectory optimization, that combines the benefits of RL and MPC. Our method uses scalable approximate inference to learn and updates probabilistic models in an online incremental fashion while also computing optimal control policies via successive local approximations. We present two variations of our algorithm based on the Sparse Spectrum Gaussian Process (SSGP) model, and we test our algorithm on three learning tasks, demonstrating the effectiveness and efficiency of our approach.