 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Costmap Inference for MPC via Deep Inverse Reinforcement Learning
Jan 17, 2022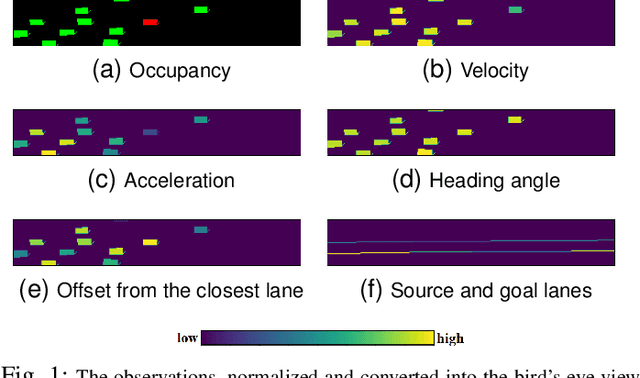

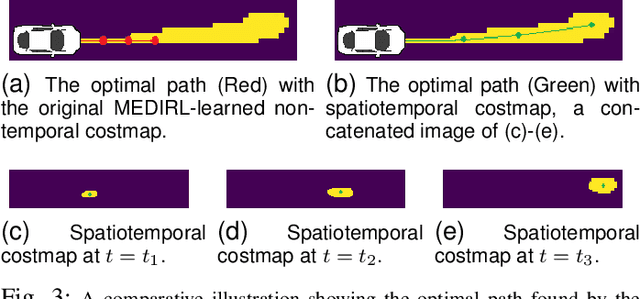
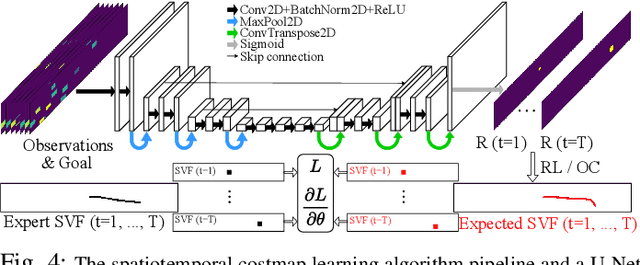
It can be difficult to autonomously produce driver behavior so that it appears natural to other traffic participants. Through Inverse Reinforcement Learning (IRL), we can automate this process by learning the underlying reward function from human demonstrations. We propose a new IRL algorithm that learns a goal-conditioned spatiotemporal reward function. The resulting costmap is used by Model Predictive Controllers (MPCs) to perform a task without any hand-designing or hand-tuning of the cost function. We evaluate our proposed Goal-conditioned SpatioTemporal Zeroing Maximum Entropy Deep IRL (GSTZ)-MEDIRL framework together with MPC in the CARLA simulator for autonomous driving, lane keeping, and lane changing tasks in a challenging dense traffic highway scenario. Our proposed methods show higher success rates compared to other baseline methods including behavior cloning, state-of-the-art RL policies, and MPC with a learning-based behavior prediction model.
Adaptive CVaR Optimization for Dynamical Systems with Path Space Stochastic Search
Sep 02, 2020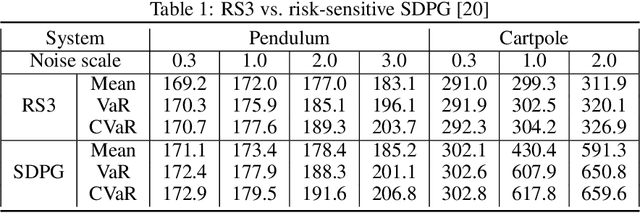
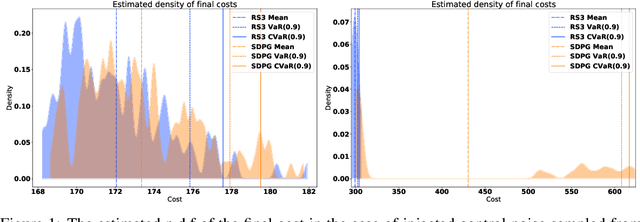
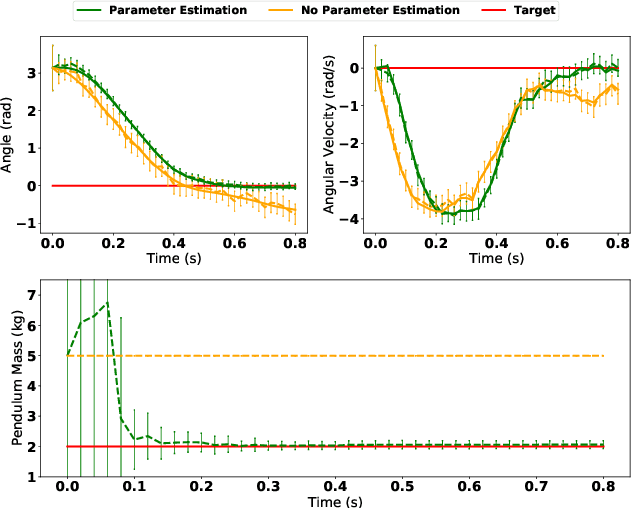

We present a general framework for optimizing the Conditional Value-at-Risk for dynamical systems using stochastic search. The framework is capable of handling the uncertainty from the initial condition, stochastic dynamics, and uncertain parameters in the model. The algorithm is compared against a risk-sensitive distributional reinforcement learning framework and demonstrates outperformance on a pendulum and cartpole with stochastic dynamics. We also showcase the applicability of the framework to robotics as an adaptive risk-sensitive controller by optimizing with respect to the fully nonlinear belief provided by a particle filter on a pendulum, cartpole, and quadcopter in simulation.
Approximate Inverse Reinforcement Learning from Vision-based Imitation Learning
Apr 17, 2020
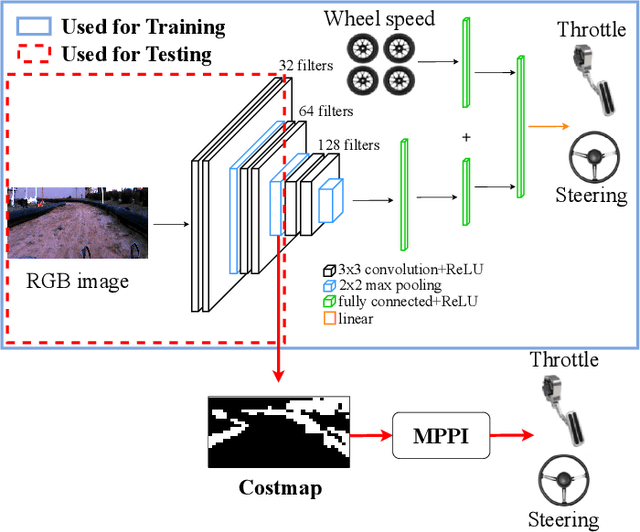


In this work, we present a method for obtaining an implicit objective function for vision-based navigation. The proposed methodology relies on Imitation Learning, Model Predictive Control (MPC), and Deep Learning. We use Imitation Learning as a means to do Inverse Reinforcement Learning in order to create an approximate costmap generator for a visual navigation challenge. The resulting costmap is used in conjunction with a Model Predictive Controller for real-time control and outperforms other state-of-the-art costmap generators combined with MPC in novel environments. The proposed process allows for simple training and robustness to out-of-sample data. We apply our method to the task of vision-based autonomous driving in multiple real and simulated environments using the same weights for the costmap predictor in all environments.
Sample-based Distributional Policy Gradient
Jan 08, 2020
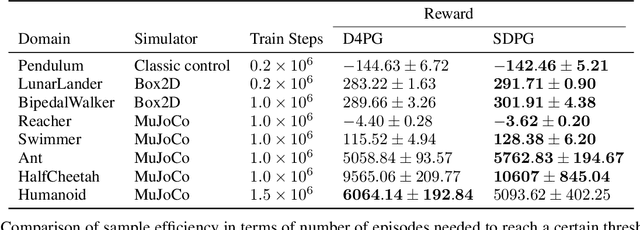

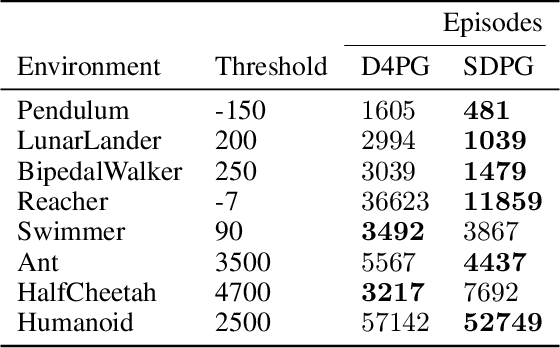
Distributional reinforcement learning (DRL) is a recent reinforcement learning framework whose success has been supported by various empirical studies. It relies on the key idea of replacing the expected return with the return distribution, which captures the intrinsic randomness of the long term rewards. Most of the existing literature on DRL focuses on problems with discrete action space and value based methods. In this work, motivated by applications in robotics with continuous action space control settings, we propose sample-based distributional policy gradient (SDPG) algorithm. It models the return distribution using samples via a reparameterization technique widely used in generative modeling and inference. We compare SDPG with the state-of-art policy gradient method in DRL, distributed distributional deterministic policy gradients (D4PG), which has demonstrated state-of-art performance. We apply SDPG and D4PG to multiple OpenAI Gym environments and observe that our algorithm shows better sample efficiency as well as higher reward for most tasks.
Aggressive Perception-Aware Navigation using Deep Optical Flow Dynamics and PixelMPC
Jan 07, 2020


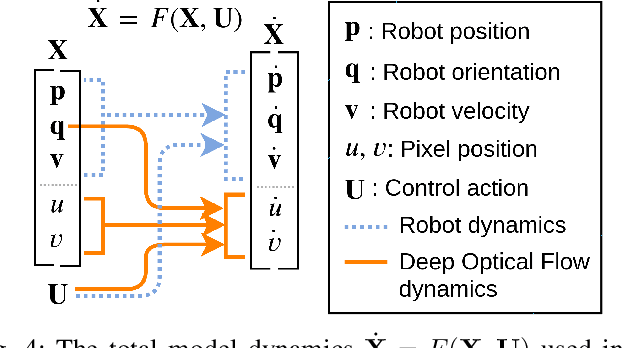
Recently, vision-based control has gained traction by leveraging the power of machine learning. In this work, we couple a model predictive control (MPC) framework to a visual pipeline. We introduce deep optical flow (DOF) dynamics, which is a combination of optical flow and robot dynamics. Using the DOF dynamics, MPC explicitly incorporates the predicted movement of relevant pixels into the planned trajectory of a robot. Our implementation of DOF is memory-efficient, data-efficient, and computationally cheap so that it can be computed in real-time for use in an MPC framework. The suggested Pixel Model Predictive Control (PixelMPC) algorithm controls the robot to accomplish a high-speed racing task while maintaining visibility of the important features (gates). This improves the reliability of vision-based estimators for localization and can eventually lead to safe autonomous flight. The proposed algorithm is tested in a photorealistic simulation with a high-speed drone racing task.
Deep Forward-Backward SDEs for Min-max Control
Jun 11, 2019
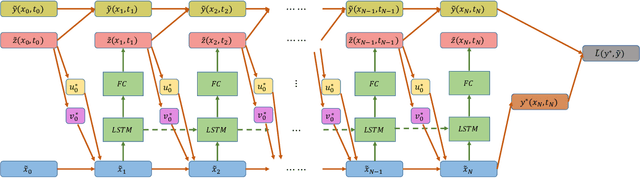
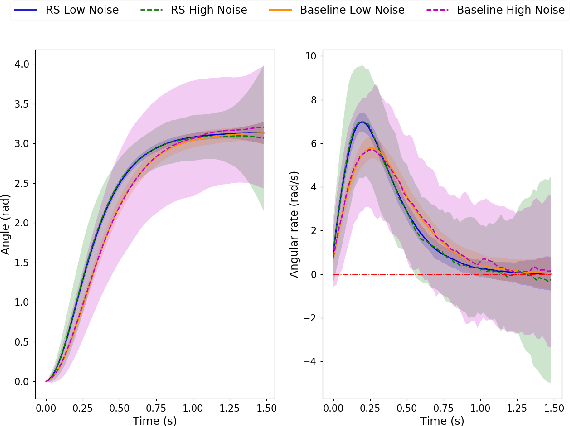
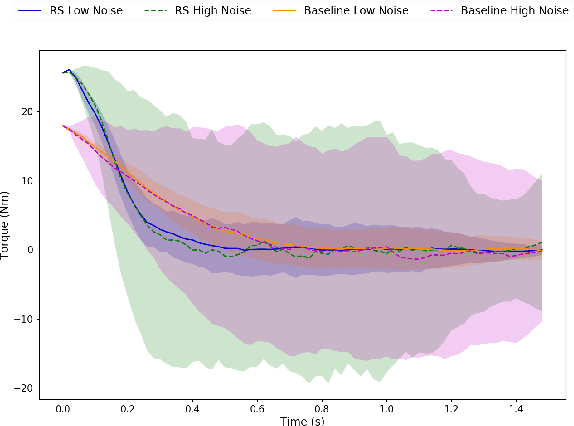
This paper presents a novel approach to numerically solve stochastic differential games for nonlinear systems. The proposed approach relies on the nonlinear Feynman-Kac theorem that establishes a connection between parabolic deterministic partial differential equations and forward-backward stochastic differential equations. Using this theorem the Hamilton-Jacobi-Isaacs partial differential equation associated with differential games is represented by a system of forward-backward stochastic differential equations. Numerical solution of the aforementioned system of stochastic differential equations is performed using importance sampling and a Long-Short Term Memory recurrent neural network, which is trained in an offline fashion. The resulting algorithm is tested on two example systems in simulation and compared against the standard risk neutral stochastic optimal control formulations.
Perceptual Attention-based Predictive Control
Apr 26, 2019

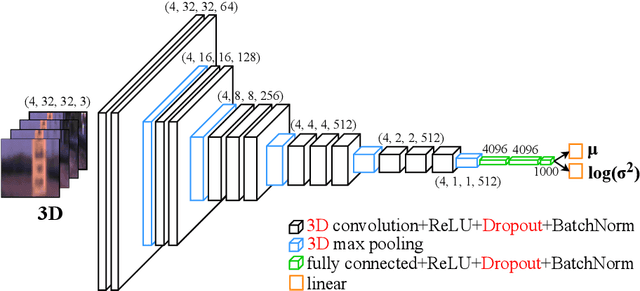

In this paper, we present a novel information processing architecture for end-to-end visual navigation of autonomous systems. The proposed information processing architecture is used to support a perceptual attention-based predictive control algorithm that leverages model predictive control, convolutional neural networks and uncertainty quantification methods. The key idea relies on using model predictive control to train convolutional neural networks to predict regions of interest in the input visual information. These regions of interest are then used as input to the Macula-Network, a 3D convolutional neural network that is trained to produce control actions as well as estimates of epistemic and aleatoric uncertainty in the incoming stream of data. The proposed architecture is tested on simulated examples and a 1:5 scale terrestrial vehicle. Experimental results show that the proposed architecture outperforms previous approaches on early detection of novel object/data which are outside of the initial training set. The proposed architecture is a first step towards using end-to-end perceptual control policies in safety-critical domains.
Ensemble Bayesian Decision Making with Redundant Deep Perceptual Control Policies
Feb 19, 2019
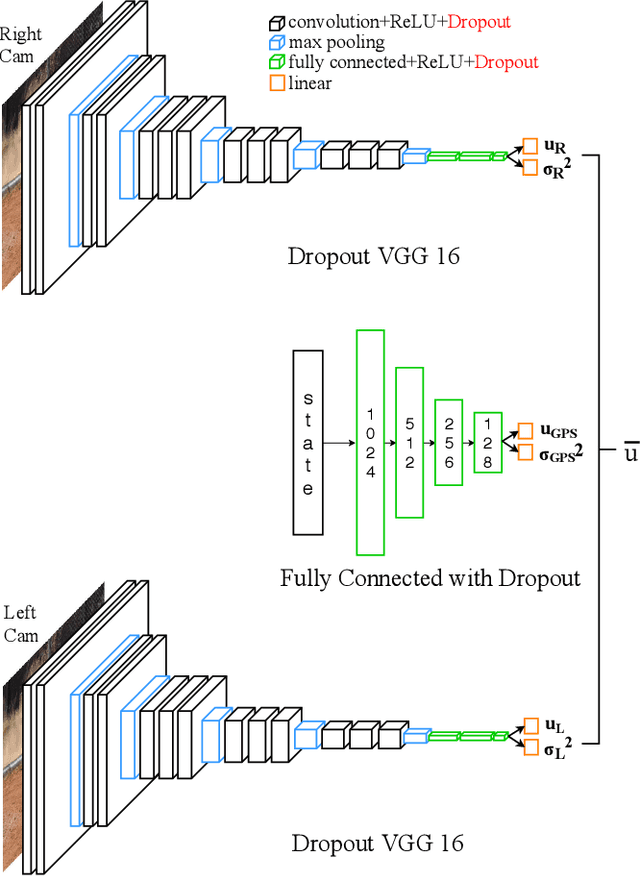


This work presents a novel ensemble of Bayesian Neural Networks (BNNs) for control of safety-critical systems. Decision making for safety-critical systems is challenging due to performance requirements with significant consequences in the event of failure. In practice, failure of such systems can be avoided by introducing redundancies of control. Neural Networks (NNs) are generally not used for safety-critical systems as they can behave in unexpected ways in response to novel inputs. In addition, there may not be any indication as to when they will fail. BNNs have been recognized for their ability to produce not only viable outputs but also provide a measure of uncertainty in these outputs. This work combines the knowledge of prediction uncertainty obtained from BNNs and ensemble control for a redundant control methodology. Our technique is applied to an agile autonomous driving task. Multiple BNNs are trained to control a vehicle in an end-to-end fashion on different sensor inputs provided by the system. We show that an individual network is successful in maneuvering around the track but crashes in the presence of unforeseen input noise. Our proposed ensemble of BNNs shows successful task performance even in the event of multiple sensor failures.
Safe end-to-end imitation learning for model predictive control
Oct 14, 2018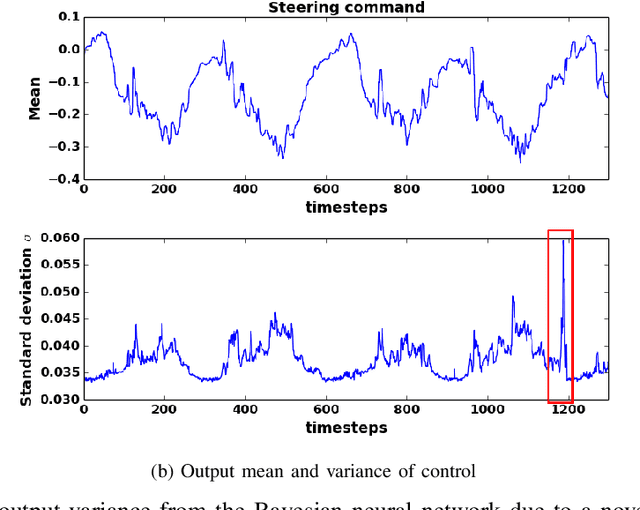
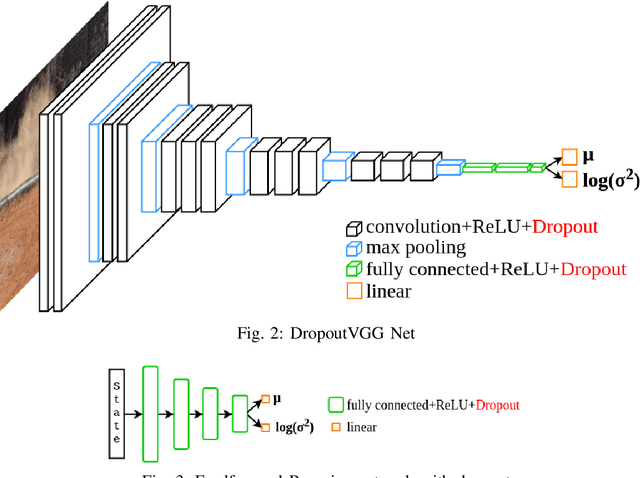
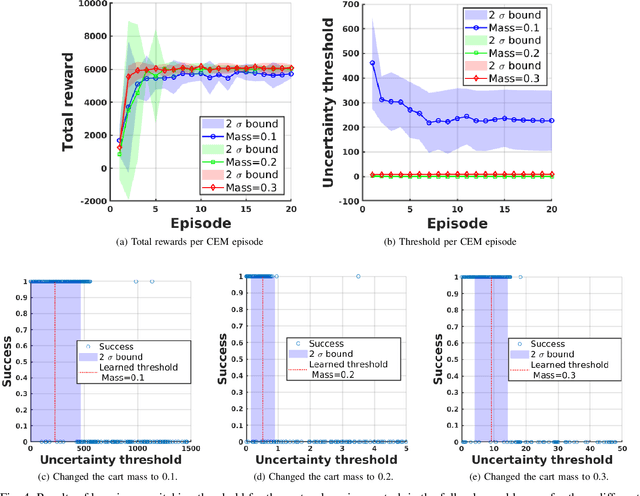
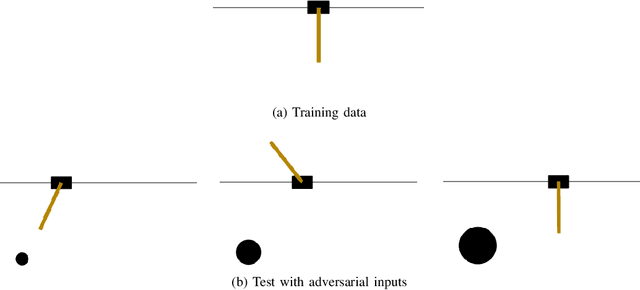
We propose the use of Bayesian networks, which provide both a mean value and an uncertainty estimate as output, to enhance the safety of learned control policies under circumstances in which a test-time input differs significantly from the training set. Our algorithm combines reinforcement learning and end-to-end imitation learning to simultaneously learn a control policy as well as a threshold over the predictive uncertainty of the learned model, with no hand-tuning required. Corrective action, such as a return of control to the model predictive controller or human expert, is taken when the uncertainty threshold is exceeded. We validate our method on fully-observable and vision-based partially-observable systems using cart-pole and autonomous driving simulations using deep convolutional Bayesian neural networks. We demonstrate that our method is robust to uncertainty resulting from varying system dynamics as well as from partial state observability.
Agile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning
Sep 10, 2018
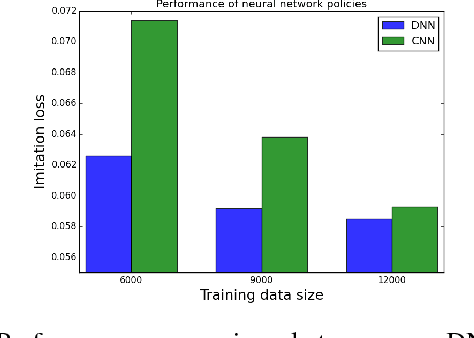
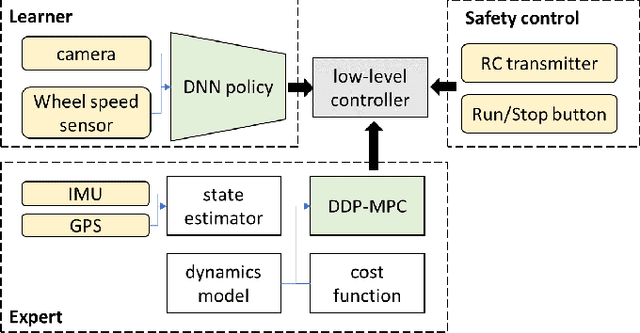

We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands. Compared with recent approaches to similar tasks, our method requires neither state estimation nor on-the-fly planning to navigate the vehicle. Our approach relies on, and experimentally validates, recent imitation learning theory. Empirically, we show that policies trained with online imitation learning overcome well-known challenges related to covariate shift and generalize better than policies trained with batch imitation learning. Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.