 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe end-to-end imitation learning for model predictive control
Paper and Code
Oct 14, 2018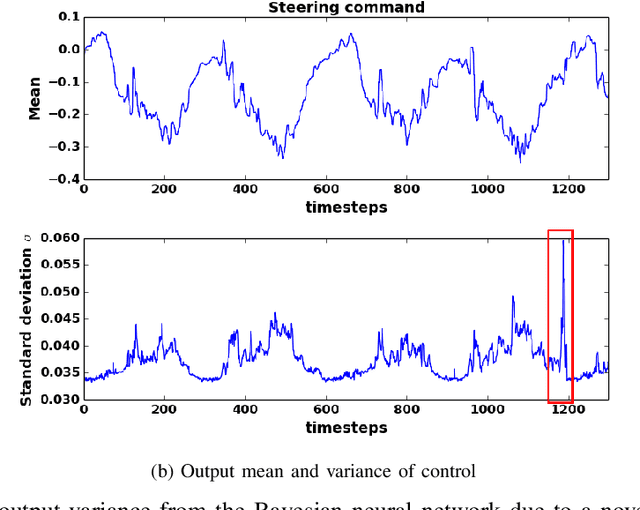
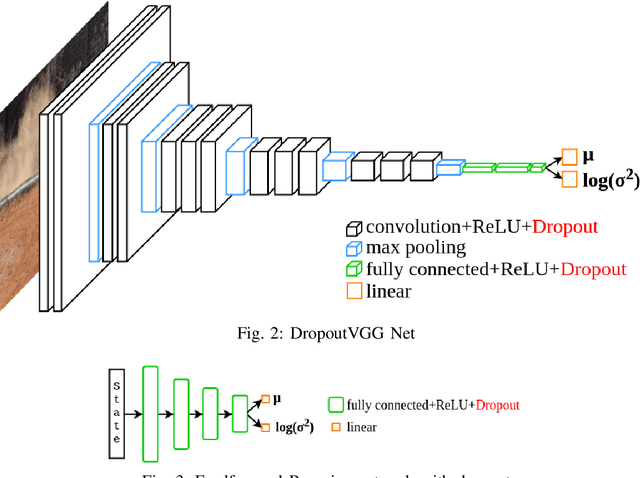
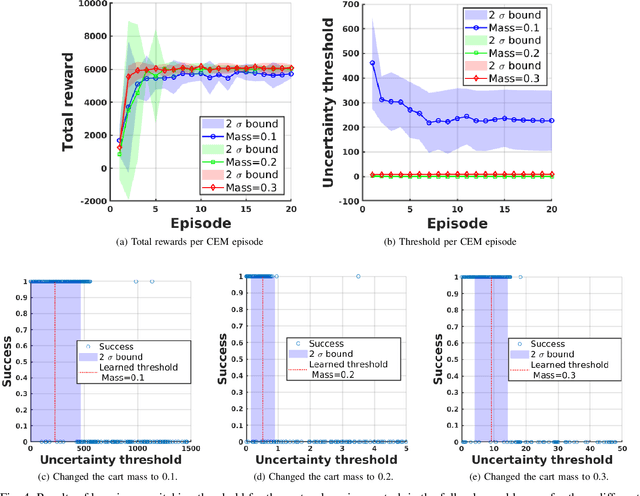
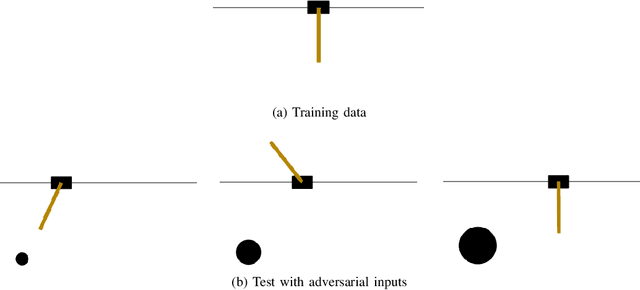
We propose the use of Bayesian networks, which provide both a mean value and an uncertainty estimate as output, to enhance the safety of learned control policies under circumstances in which a test-time input differs significantly from the training set. Our algorithm combines reinforcement learning and end-to-end imitation learning to simultaneously learn a control policy as well as a threshold over the predictive uncertainty of the learned model, with no hand-tuning required. Corrective action, such as a return of control to the model predictive controller or human expert, is taken when the uncertainty threshold is exceeded. We validate our method on fully-observable and vision-based partially-observable systems using cart-pole and autonomous driving simulations using deep convolutional Bayesian neural networks. We demonstrate that our method is robust to uncertainty resulting from varying system dynamics as well as from partial state observability.