 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBellman Value Decomposition for Task Logic in Safe Optimal Control
Feb 23, 2026Real-world tasks involve nuanced combinations of goal and safety specifications. In high dimensions, the challenge is exacerbated: formal automata become cumbersome, and the combination of sparse rewards tends to require laborious tuning. In this work, we consider the innate structure of the Bellman Value as a means to naturally organize the problem for improved automatic performance. Namely, we prove the Bellman Value for a complex task defined in temporal logic can be decomposed into a graph of Bellman Values, connected by a set of well-known Bellman equations (BEs): the Reach-Avoid BE, the Avoid BE, and a novel type, the Reach-Avoid-Loop BE. To solve the Value and optimal policy, we propose VDPPO, which embeds the decomposed Value graph into a two-layer neural net, bootstrapping the implicit dependencies. We conduct a variety of simulated and hardware experiments to test our method on complex, high-dimensional tasks involving heterogeneous teams and nonlinear dynamics. Ultimately, we find this approach greatly improves performance over existing baselines, balancing safety and liveness automatically.
Solving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement Learning
Feb 17, 2026Recent advances in deep reinforcement learning (RL) have achieved strong results on high-dimensional control tasks, but applying RL to reachability problems raises a fundamental mismatch: reachability seeks to maximize the set of states from which a system remains safe indefinitely, while RL optimizes expected returns over a user-specified distribution. This mismatch can result in policies that perform poorly on low-probability states that are still within the safe set. A natural alternative is to frame the problem as a robust optimization over a set of initial conditions that specify the initial state, dynamics and safe set, but whether this problem has a solution depends on the feasibility of the specified set, which is unknown a priori. We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies a subset of feasible initial conditions under which a safe policy exists, and learns a policy to solve the reachability problem over this set of initial conditions. Empirical results demonstrate that FGE learns policies with over 50% more coverage than the best existing method for challenging initial conditions across tasks in the MuJoCo simulator and the Kinetix simulator with pixel observations.
Discrete Adjoint Matching
Feb 06, 2026Computation methods for solving entropy-regularized reward optimization -- a class of problems widely used for fine-tuning generative models -- have advanced rapidly. Among those, Adjoint Matching (AM, Domingo-Enrich et al., 2025) has proven highly effective in continuous state spaces with differentiable rewards. Transferring these practical successes to discrete generative modeling, however, remains particularly challenging and largely unexplored, mainly due to the drastic shift in generative model classes to discrete state spaces, which are nowhere differentiable. In this work, we propose Discrete Adjoint Matching (DAM) -- a discrete variant of AM for fine-tuning discrete generative models characterized by Continuous-Time Markov Chains, such as diffusion-based large language models. The core of DAM is the introduction of discrete adjoint-an estimator of the optimal solution to the original problem but formulated on discrete domains-from which standard matching frameworks can be applied. This is derived via a purely statistical standpoint, in contrast to the control-theoretic viewpoint in AM, thereby opening up new algorithmic opportunities for general adjoint-based estimators. We showcase DAM's effectiveness on synthetic and mathematical reasoning tasks.
ReFORM: Reflected Flows for On-support Offline RL via Noise Manipulation
Feb 04, 2026Offline reinforcement learning (RL) aims to learn the optimal policy from a fixed dataset generated by behavior policies without additional environment interactions. One common challenge that arises in this setting is the out-of-distribution (OOD) error, which occurs when the policy leaves the training distribution. Prior methods penalize a statistical distance term to keep the policy close to the behavior policy, but this constrains policy improvement and may not completely prevent OOD actions. Another challenge is that the optimal policy distribution can be multimodal and difficult to represent. Recent works apply diffusion or flow policies to address this problem, but it is unclear how to avoid OOD errors while retaining policy expressiveness. We propose ReFORM, an offline RL method based on flow policies that enforces the less restrictive support constraint by construction. ReFORM learns a behavior cloning (BC) flow policy with a bounded source distribution to capture the support of the action distribution, then optimizes a reflected flow that generates bounded noise for the BC flow while keeping the support, to maximize the performance. Across 40 challenging tasks from the OGBench benchmark with datasets of varying quality and using a constant set of hyperparameters for all tasks, ReFORM dominates all baselines with hand-tuned hyperparameters on the performance profile curves.
Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARL
Apr 21, 2025Tasks for multi-robot systems often require the robots to collaborate and complete a team goal while maintaining safety. This problem is usually formalized as a constrained Markov decision process (CMDP), which targets minimizing a global cost and bringing the mean of constraint violation below a user-defined threshold. Inspired by real-world robotic applications, we define safety as zero constraint violation. While many safe multi-agent reinforcement learning (MARL) algorithms have been proposed to solve CMDPs, these algorithms suffer from unstable training in this setting. To tackle this, we use the epigraph form for constrained optimization to improve training stability and prove that the centralized epigraph form problem can be solved in a distributed fashion by each agent. This results in a novel centralized training distributed execution MARL algorithm named Def-MARL. Simulation experiments on 8 different tasks across 2 different simulators show that Def-MARL achieves the best overall performance, satisfies safety constraints, and maintains stable training. Real-world hardware experiments on Crazyflie quadcopters demonstrate the ability of Def-MARL to safely coordinate agents to complete complex collaborative tasks compared to other methods.
Safe Beyond the Horizon: Efficient Sampling-based MPC with Neural Control Barrier Functions
Feb 20, 2025A common problem when using model predictive control (MPC) in practice is the satisfaction of safety specifications beyond the prediction horizon. While theoretical works have shown that safety can be guaranteed by enforcing a suitable terminal set constraint or a sufficiently long prediction horizon, these techniques are difficult to apply and thus are rarely used by practitioners, especially in the case of general nonlinear dynamics. To solve this problem, we impose a tradeoff between exact recursive feasibility, computational tractability, and applicability to ''black-box'' dynamics by learning an approximate discrete-time control barrier function and incorporating it into a variational inference MPC (VIMPC), a sampling-based MPC paradigm. To handle the resulting state constraints, we further propose a new sampling strategy that greatly reduces the variance of the estimated optimal control, improving the sample efficiency, and enabling real-time planning on a CPU. The resulting Neural Shield-VIMPC (NS-VIMPC) controller yields substantial safety improvements compared to existing sampling-based MPC controllers, even under badly designed cost functions. We validate our approach in both simulation and real-world hardware experiments.
Learning Plasma Dynamics and Robust Rampdown Trajectories with Predict-First Experiments at TCV
Feb 17, 2025The rampdown in tokamak operations is a difficult to simulate phase during which the plasma is often pushed towards multiple instability limits. To address this challenge, and reduce the risk of disrupting operations, we leverage recent advances in Scientific Machine Learning (SciML) to develop a neural state-space model (NSSM) that predicts plasma dynamics during Tokamak \`a Configuration Variable (TCV) rampdowns. By integrating simple physics structure and data-driven models, the NSSM efficiently learns plasma dynamics during the rampdown from a modest dataset of 311 pulses with only five pulses in the reactor relevant high performance regime. The NSSM is parallelized across uncertainties, and reinforcement learning (RL) is applied to design trajectories that avoid multiple instability limits with high probability. Experiments at TCV ramping down high performance plasmas show statistically significant improvements in current and energy at plasma termination, with improvements in speed through continuous re-training. A predict-first experiment, increasing plasma current by 20\% from baseline, demonstrates the NSSM's ability to make small extrapolations with sufficient accuracy to design trajectories that successfully terminate the pulse. The developed approach paves the way for designing tokamak controls with robustness to considerable uncertainty, and demonstrates the relevance of the SciML approach to learning plasma dynamics for rapidly developing robust trajectories and controls during the incremental campaigns of upcoming burning plasma tokamaks.
Discrete GCBF Proximal Policy Optimization for Multi-agent Safe Optimal Control
Feb 05, 2025



Control policies that can achieve high task performance and satisfy safety constraints are desirable for any system, including multi-agent systems (MAS). One promising technique for ensuring the safety of MAS is distributed control barrier functions (CBF). However, it is difficult to design distributed CBF-based policies for MAS that can tackle unknown discrete-time dynamics, partial observability, changing neighborhoods, and input constraints, especially when a distributed high-performance nominal policy that can achieve the task is unavailable. To tackle these challenges, we propose DGPPO, a new framework that simultaneously learns both a discrete graph CBF which handles neighborhood changes and input constraints, and a distributed high-performance safe policy for MAS with unknown discrete-time dynamics. We empirically validate our claims on a suite of multi-agent tasks spanning three different simulation engines. The results suggest that, compared with existing methods, our DGPPO framework obtains policies that achieve high task performance (matching baselines that ignore the safety constraints), and high safety rates (matching the most conservative baselines), with a constant set of hyperparameters across all environments.
Solving Minimum-Cost Reach Avoid using Reinforcement Learning
Oct 29, 2024Current reinforcement-learning methods are unable to directly learn policies that solve the minimum cost reach-avoid problem to minimize cumulative costs subject to the constraints of reaching the goal and avoiding unsafe states, as the structure of this new optimization problem is incompatible with current methods. Instead, a surrogate problem is solved where all objectives are combined with a weighted sum. However, this surrogate objective results in suboptimal policies that do not directly minimize the cumulative cost. In this work, we propose RC-PPO, a reinforcement-learning-based method for solving the minimum-cost reach-avoid problem by using connections to Hamilton-Jacobi reachability. Empirical results demonstrate that RC-PPO learns policies with comparable goal-reaching rates to while achieving up to 57% lower cumulative costs compared to existing methods on a suite of minimum-cost reach-avoid benchmarks on the Mujoco simulator. The project page can be found at https://oswinso.xyz/rcppo.
RPCBF: Constructing Safety Filters Robust to Model Error and Disturbances via Policy Control Barrier Functions
Oct 15, 2024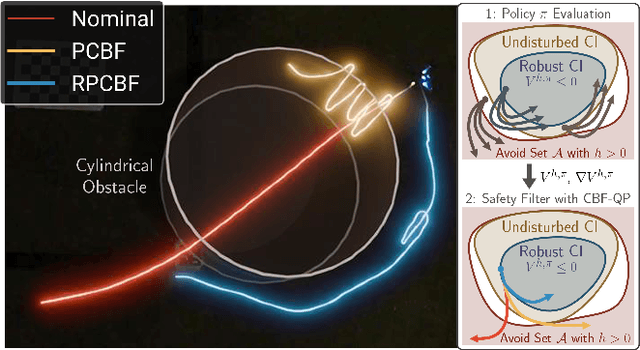
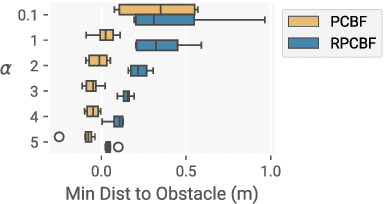

Control Barrier Functions (CBFs) have proven to be an effective tool for performing safe control synthesis for nonlinear systems. However, guaranteeing safety in the presence of disturbances and input constraints for high relative degree systems is a difficult problem. In this work, we propose the Robust Policy CBF (RPCBF), a practical method of constructing CBF approximations that is easy to implement and robust to disturbances via the estimation of a value function. We demonstrate the effectiveness of our method in simulation on a variety of high relative degree input-constrained systems. Finally, we demonstrate the benefits of RPCBF in compensating for model errors on a hardware quadcopter platform by treating the model errors as disturbances. The project page can be found at https://oswinso.xyz/rpcbf.