 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Parameter-Robust Avoid Problems with Unknown Feasibility using Reinforcement Learning
Feb 17, 2026Recent advances in deep reinforcement learning (RL) have achieved strong results on high-dimensional control tasks, but applying RL to reachability problems raises a fundamental mismatch: reachability seeks to maximize the set of states from which a system remains safe indefinitely, while RL optimizes expected returns over a user-specified distribution. This mismatch can result in policies that perform poorly on low-probability states that are still within the safe set. A natural alternative is to frame the problem as a robust optimization over a set of initial conditions that specify the initial state, dynamics and safe set, but whether this problem has a solution depends on the feasibility of the specified set, which is unknown a priori. We propose Feasibility-Guided Exploration (FGE), a method that simultaneously identifies a subset of feasible initial conditions under which a safe policy exists, and learns a policy to solve the reachability problem over this set of initial conditions. Empirical results demonstrate that FGE learns policies with over 50% more coverage than the best existing method for challenging initial conditions across tasks in the MuJoCo simulator and the Kinetix simulator with pixel observations.
ReFORM: Reflected Flows for On-support Offline RL via Noise Manipulation
Feb 04, 2026Offline reinforcement learning (RL) aims to learn the optimal policy from a fixed dataset generated by behavior policies without additional environment interactions. One common challenge that arises in this setting is the out-of-distribution (OOD) error, which occurs when the policy leaves the training distribution. Prior methods penalize a statistical distance term to keep the policy close to the behavior policy, but this constrains policy improvement and may not completely prevent OOD actions. Another challenge is that the optimal policy distribution can be multimodal and difficult to represent. Recent works apply diffusion or flow policies to address this problem, but it is unclear how to avoid OOD errors while retaining policy expressiveness. We propose ReFORM, an offline RL method based on flow policies that enforces the less restrictive support constraint by construction. ReFORM learns a behavior cloning (BC) flow policy with a bounded source distribution to capture the support of the action distribution, then optimizes a reflected flow that generates bounded noise for the BC flow while keeping the support, to maximize the performance. Across 40 challenging tasks from the OGBench benchmark with datasets of varying quality and using a constant set of hyperparameters for all tasks, ReFORM dominates all baselines with hand-tuned hyperparameters on the performance profile curves.
Solving Multi-Agent Safe Optimal Control with Distributed Epigraph Form MARL
Apr 21, 2025Tasks for multi-robot systems often require the robots to collaborate and complete a team goal while maintaining safety. This problem is usually formalized as a constrained Markov decision process (CMDP), which targets minimizing a global cost and bringing the mean of constraint violation below a user-defined threshold. Inspired by real-world robotic applications, we define safety as zero constraint violation. While many safe multi-agent reinforcement learning (MARL) algorithms have been proposed to solve CMDPs, these algorithms suffer from unstable training in this setting. To tackle this, we use the epigraph form for constrained optimization to improve training stability and prove that the centralized epigraph form problem can be solved in a distributed fashion by each agent. This results in a novel centralized training distributed execution MARL algorithm named Def-MARL. Simulation experiments on 8 different tasks across 2 different simulators show that Def-MARL achieves the best overall performance, satisfies safety constraints, and maintains stable training. Real-world hardware experiments on Crazyflie quadcopters demonstrate the ability of Def-MARL to safely coordinate agents to complete complex collaborative tasks compared to other methods.
Discrete GCBF Proximal Policy Optimization for Multi-agent Safe Optimal Control
Feb 05, 2025



Control policies that can achieve high task performance and satisfy safety constraints are desirable for any system, including multi-agent systems (MAS). One promising technique for ensuring the safety of MAS is distributed control barrier functions (CBF). However, it is difficult to design distributed CBF-based policies for MAS that can tackle unknown discrete-time dynamics, partial observability, changing neighborhoods, and input constraints, especially when a distributed high-performance nominal policy that can achieve the task is unavailable. To tackle these challenges, we propose DGPPO, a new framework that simultaneously learns both a discrete graph CBF which handles neighborhood changes and input constraints, and a distributed high-performance safe policy for MAS with unknown discrete-time dynamics. We empirically validate our claims on a suite of multi-agent tasks spanning three different simulation engines. The results suggest that, compared with existing methods, our DGPPO framework obtains policies that achieve high task performance (matching baselines that ignore the safety constraints), and high safety rates (matching the most conservative baselines), with a constant set of hyperparameters across all environments.
Large Language Models to the Rescue: Deadlock Resolution in Multi-Robot Systems
Apr 09, 2024



Multi-agent robotic systems are prone to deadlocks in an obstacle environment where the system can get stuck away from its desired location under a smooth low-level control policy. Without an external intervention, often in terms of a high-level command, it is not possible to guarantee that just a low-level control policy can resolve such deadlocks. Utilizing the generalizability and low data requirements of large language models (LLMs), this paper explores the possibility of using LLMs for deadlock resolution. We propose a hierarchical control framework where an LLM resolves deadlocks by assigning a leader and direction for the leader to move along. A graph neural network (GNN) based low-level distributed control policy executes the assigned plan. We systematically study various prompting techniques to improve LLM's performance in resolving deadlocks. In particular, as part of prompt engineering, we provide in-context examples for LLMs. We conducted extensive experiments on various multi-robot environments with up to 15 agents and 40 obstacles. Our results demonstrate that LLM-based high-level planners are effective in resolving deadlocks in MRS.
GCBF+: A Neural Graph Control Barrier Function Framework for Distributed Safe Multi-Agent Control
Jan 25, 2024Distributed, scalable, and safe control of large-scale multi-agent systems (MAS) is a challenging problem. In this paper, we design a distributed framework for safe multi-agent control in large-scale environments with obstacles, where a large number of agents are required to maintain safety using only local information and reach their goal locations. We introduce a new class of certificates, termed graph control barrier function (GCBF), which are based on the well-established control barrier function (CBF) theory for safety guarantees and utilize a graph structure for scalable and generalizable distributed control of MAS. We develop a novel theoretical framework to prove the safety of an arbitrary-sized MAS with a single GCBF. We propose a new training framework GCBF+ that uses graph neural networks (GNNs) to parameterize a candidate GCBF and a distributed control policy. The proposed framework is distributed and is capable of directly taking point clouds from LiDAR, instead of actual state information, for real-world robotic applications. We illustrate the efficacy of the proposed method through various hardware experiments on a swarm of drones with objectives ranging from exchanging positions to docking on a moving target without collision. Additionally, we perform extensive numerical experiments, where the number and density of agents, as well as the number of obstacles, increase. Empirical results show that in complex environments with nonlinear agents (e.g., Crazyflie drones) GCBF+ outperforms the handcrafted CBF-based method with the best performance by up to 20% for relatively small-scale MAS for up to 256 agents, and leading reinforcement learning (RL) methods by up to 40% for MAS with 1024 agents. Furthermore, the proposed method does not compromise on the performance, in terms of goal reaching, for achieving high safety rates, which is a common trade-off in RL-based methods.
Learning Safe Control for Multi-Robot Systems: Methods, Verification, and Open Challenges
Nov 22, 2023



In this survey, we review the recent advances in control design methods for robotic multi-agent systems (MAS), focussing on learning-based methods with safety considerations. We start by reviewing various notions of safety and liveness properties, and modeling frameworks used for problem formulation of MAS. Then we provide a comprehensive review of learning-based methods for safe control design for multi-robot systems. We start with various types of shielding-based methods, such as safety certificates, predictive filters, and reachability tools. Then, we review the current state of control barrier certificate learning in both a centralized and distributed manner, followed by a comprehensive review of multi-agent reinforcement learning with a particular focus on safety. Next, we discuss the state-of-the-art verification tools for the correctness of learning-based methods. Based on the capabilities and the limitations of the state of the art methods in learning and verification for MAS, we identify various broad themes for open challenges: how to design methods that can achieve good performance along with safety guarantees; how to decompose single-agent based centralized methods for MAS; how to account for communication-related practical issues; and how to assess transfer of theoretical guarantees to practice.
Confidence-Aware Imitation Learning from Demonstrations with Varying Optimality
Oct 27, 2021
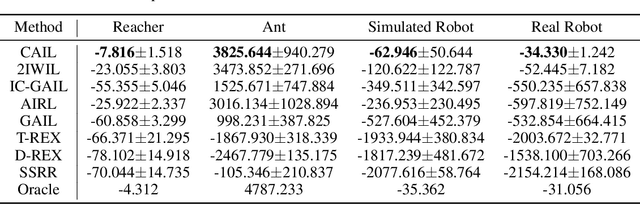


Most existing imitation learning approaches assume the demonstrations are drawn from experts who are optimal, but relaxing this assumption enables us to use a wider range of data. Standard imitation learning may learn a suboptimal policy from demonstrations with varying optimality. Prior works use confidence scores or rankings to capture beneficial information from demonstrations with varying optimality, but they suffer from many limitations, e.g., manually annotated confidence scores or high average optimality of demonstrations. In this paper, we propose a general framework to learn from demonstrations with varying optimality that jointly learns the confidence score and a well-performing policy. Our approach, Confidence-Aware Imitation Learning (CAIL) learns a well-performing policy from confidence-reweighted demonstrations, while using an outer loss to track the performance of our model and to learn the confidence. We provide theoretical guarantees on the convergence of CAIL and evaluate its performance in both simulated and real robot experiments. Our results show that CAIL significantly outperforms other imitation learning methods from demonstrations with varying optimality. We further show that even without access to any optimal demonstrations, CAIL can still learn a successful policy, and outperforms prior work.