 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



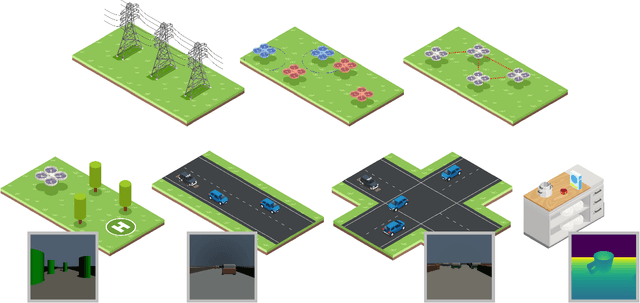
Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Rare event modeling with self-regularized normalizing flows: what can we learn from a single failure?
Feb 28, 2025Increased deployment of autonomous systems in fields like transportation and robotics have seen a corresponding increase in safety-critical failures. These failures can be difficult to model and debug due to the relative lack of data: compared to tens of thousands of examples from normal operations, we may have only seconds of data leading up to the failure. This scarcity makes it challenging to train generative models of rare failure events, as existing methods risk either overfitting to noise in the limited failure dataset or underfitting due to an overly strong prior. We address this challenge with CalNF, or calibrated normalizing flows, a self-regularized framework for posterior learning from limited data. CalNF achieves state-of-the-art performance on data-limited failure modeling and inverse problems and enables a first-of-a-kind case study into the root causes of the 2022 Southwest Airlines scheduling crisis.
Learning Plasma Dynamics and Robust Rampdown Trajectories with Predict-First Experiments at TCV
Feb 17, 2025The rampdown in tokamak operations is a difficult to simulate phase during which the plasma is often pushed towards multiple instability limits. To address this challenge, and reduce the risk of disrupting operations, we leverage recent advances in Scientific Machine Learning (SciML) to develop a neural state-space model (NSSM) that predicts plasma dynamics during Tokamak \`a Configuration Variable (TCV) rampdowns. By integrating simple physics structure and data-driven models, the NSSM efficiently learns plasma dynamics during the rampdown from a modest dataset of 311 pulses with only five pulses in the reactor relevant high performance regime. The NSSM is parallelized across uncertainties, and reinforcement learning (RL) is applied to design trajectories that avoid multiple instability limits with high probability. Experiments at TCV ramping down high performance plasmas show statistically significant improvements in current and energy at plasma termination, with improvements in speed through continuous re-training. A predict-first experiment, increasing plasma current by 20\% from baseline, demonstrates the NSSM's ability to make small extrapolations with sufficient accuracy to design trajectories that successfully terminate the pulse. The developed approach paves the way for designing tokamak controls with robustness to considerable uncertainty, and demonstrates the relevance of the SciML approach to learning plasma dynamics for rapidly developing robust trajectories and controls during the incremental campaigns of upcoming burning plasma tokamaks.
RADIUM: Predicting and Repairing End-to-End Robot Failures using Gradient-Accelerated Sampling
Apr 04, 2024


Before autonomous systems can be deployed in safety-critical applications, we must be able to understand and verify the safety of these systems. For cases where the risk or cost of real-world testing is prohibitive, we propose a simulation-based framework for a) predicting ways in which an autonomous system is likely to fail and b) automatically adjusting the system's design and control policy to preemptively mitigate those failures. Existing tools for failure prediction struggle to search over high-dimensional environmental parameters, cannot efficiently handle end-to-end testing for systems with vision in the loop, and provide little guidance on how to mitigate failures once they are discovered. We approach this problem through the lens of approximate Bayesian inference and use differentiable simulation and rendering for efficient failure case prediction and repair. For cases where a differentiable simulator is not available, we provide a gradient-free version of our algorithm, and we include a theoretical and empirical evaluation of the trade-offs between gradient-based and gradient-free methods. We apply our approach on a range of robotics and control problems, including optimizing search patterns for robot swarms, UAV formation control, and robust network control. Compared to optimization-based falsification methods, our method predicts a more diverse, representative set of failure modes, and we find that our use of differentiable simulation yields solutions that have up to 10x lower cost and requires up to 2x fewer iterations to converge relative to gradient-free techniques. In hardware experiments, we find that repairing control policies using our method leads to a 5x robustness improvement. Accompanying code and video can be found at https://mit-realm.github.io/radium/
Active Disruption Avoidance and Trajectory Design for Tokamak Ramp-downs with Neural Differential Equations and Reinforcement Learning
Feb 14, 2024



The tokamak offers a promising path to fusion energy, but plasma disruptions pose a major economic risk, motivating considerable advances in disruption avoidance. This work develops a reinforcement learning approach to this problem by training a policy to safely ramp-down the plasma current while avoiding limits on a number of quantities correlated with disruptions. The policy training environment is a hybrid physics and machine learning model trained on simulations of the SPARC primary reference discharge (PRD) ramp-down, an upcoming burning plasma scenario which we use as a testbed. To address physics uncertainty and model inaccuracies, the simulation environment is massively parallelized on GPU with randomized physics parameters during policy training. The trained policy is then successfully transferred to a higher fidelity simulator where it successfully ramps down the plasma while avoiding user-specified disruptive limits. We also address the crucial issue of safety criticality by demonstrating that a constraint-conditioned policy can be used as a trajectory design assistant to design a library of feed-forward trajectories to handle different physics conditions and user settings. As a library of trajectories is more interpretable and verifiable offline, we argue such an approach is a promising path for leveraging the capabilities of reinforcement learning in the safety-critical context of burning plasma tokamaks. Finally, we demonstrate how the training environment can be a useful platform for other feed-forward optimization approaches by using an evolutionary algorithm to perform optimization of feed-forward trajectories that are robust to physics uncertainty
Learning Safe Control for Multi-Robot Systems: Methods, Verification, and Open Challenges
Nov 22, 2023



In this survey, we review the recent advances in control design methods for robotic multi-agent systems (MAS), focussing on learning-based methods with safety considerations. We start by reviewing various notions of safety and liveness properties, and modeling frameworks used for problem formulation of MAS. Then we provide a comprehensive review of learning-based methods for safe control design for multi-robot systems. We start with various types of shielding-based methods, such as safety certificates, predictive filters, and reachability tools. Then, we review the current state of control barrier certificate learning in both a centralized and distributed manner, followed by a comprehensive review of multi-agent reinforcement learning with a particular focus on safety. Next, we discuss the state-of-the-art verification tools for the correctness of learning-based methods. Based on the capabilities and the limitations of the state of the art methods in learning and verification for MAS, we identify various broad themes for open challenges: how to design methods that can achieve good performance along with safety guarantees; how to decompose single-agent based centralized methods for MAS; how to account for communication-related practical issues; and how to assess transfer of theoretical guarantees to practice.
A Bayesian approach to breaking things: efficiently predicting and repairing failure modes via sampling
Sep 14, 2023



Before autonomous systems can be deployed in safety-critical applications, we must be able to understand and verify the safety of these systems. For cases where the risk or cost of real-world testing is prohibitive, we propose a simulation-based framework for a) predicting ways in which an autonomous system is likely to fail and b) automatically adjusting the system's design to preemptively mitigate those failures. We frame this problem through the lens of approximate Bayesian inference and use differentiable simulation for efficient failure case prediction and repair. We apply our approach on a range of robotics and control problems, including optimizing search patterns for robot swarms and reducing the severity of outages in power transmission networks. Compared to optimization-based falsification techniques, our method predicts a more diverse, representative set of failure modes, and we also find that our use of differentiable simulation yields solutions that have up to 10x lower cost and requires up to 2x fewer iterations to converge relative to gradient-free techniques. Code and videos can be found at https://mit-realm.github.io/breaking-things/
Shield Model Predictive Path Integral: A Computationally Efficient Robust MPC Approach Using Control Barrier Functions
Feb 23, 2023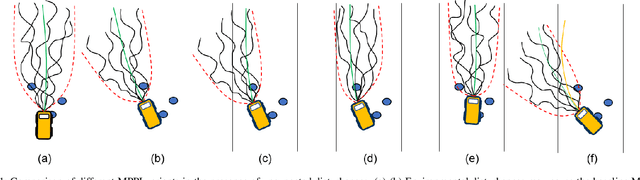
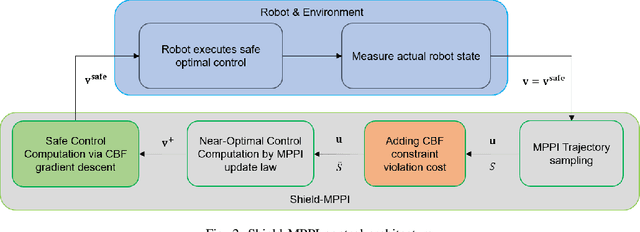
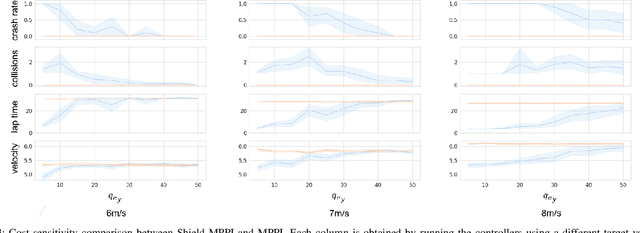
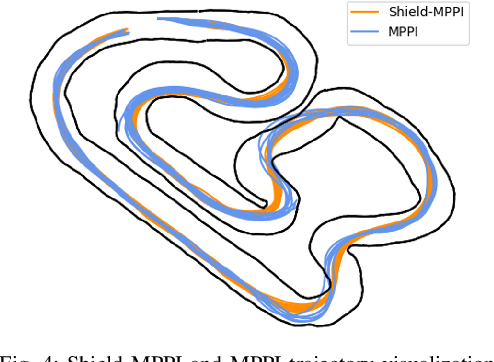
Model Predictive Path Integral (MPPI) control is a type of sampling-based model predictive control that simulates thousands of trajectories and uses these trajectories to synthesize optimal controls on-the-fly. In practice, however, MPPI encounters problems limiting its application. For instance, it has been observed that MPPI tends to make poor decisions if unmodeled dynamics or environmental disturbances exist, preventing its use in safety-critical applications. Moreover, the multi-threaded simulations used by MPPI require significant onboard computational resources, making the algorithm inaccessible to robots without modern GPUs. To alleviate these issues, we propose a novel (Shield-MPPI) algorithm that provides robustness against unpredicted disturbances and achieves real-time planning using a much smaller number of parallel simulations on regular CPUs. The novel Shield-MPPI algorithm is tested on an aggressive autonomous racing platform both in simulation and using experiments. The results show that the proposed controller greatly reduces the number of constraint violations compared to state-of-the-art robust MPPI variants and stochastic MPC methods.
Chance-Constrained Trajectory Optimization for High-DOF Robots in Uncertain Environments
Jan 31, 2023



Many practical applications of robotics require systems that can operate safely despite uncertainty. In the context of motion planning, two types of uncertainty are particularly important when planning safe robot trajectories. The first is environmental uncertainty -- uncertainty in the locations of nearby obstacles, stemming from sensor noise or (in the case of obstacles' future locations) prediction error. The second class of uncertainty is uncertainty in the robots own state, typically caused by tracking or estimation error. To achieve high levels of safety, it is necessary for robots to consider both of these sources of uncertainty. In this paper, we propose a risk-bounded trajectory optimization algorithm, known as Sequential Convex Optimization with Risk Optimization (SCORA), to solve chance-constrained motion planning problems despite both environmental uncertainty and tracking error. Through experiments in simulation, we demonstrate that SCORA significantly outperforms state-of-the-art risk-aware motion planners both in planning time and in the safety of the resulting trajectories.
Barrier functions enable safety-conscious force-feedback control
Sep 25, 2022

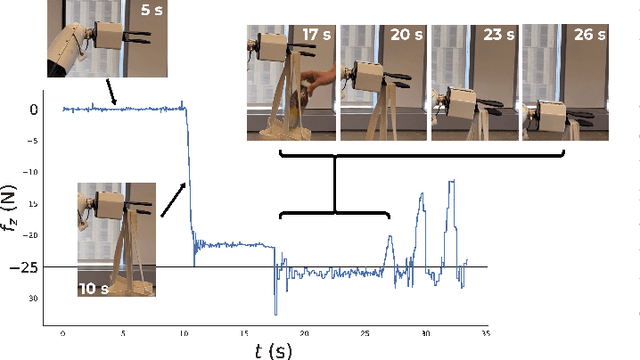

In order to be effective partners for humans, robots must become increasingly comfortable with making contact with their environment. Unfortunately, it is hard for robots to distinguish between ``just enough'' and ``too much'' force: some force is required to accomplish the task but too much might damage equipment or injure humans. Traditional approaches to designing compliant force-feedback controllers, such as stiffness control, require difficult hand-tuning of control parameters and make it difficult to build safe, effective robot collaborators. In this paper, we propose a novel yet easy-to-implement force feedback controller that uses control barrier functions (CBFs) to derive a compliant controller directly from users' specifications of the maximum allowable forces and torques. We compare our approach to traditional stiffness control to demonstrate potential advantages of our control architecture, and we demonstrate the effectiveness of our controller on an example human-robot collaboration task: cooperative manipulation of a bulky object.