 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED-SET: Scalable Evolving Experimental Design for System-level Ethical Testing
Mar 02, 2026As autonomous systems such as drones, become increasingly deployed in high-stakes, human-centric domains, it is critical to evaluate the ethical alignment since failure to do so imposes imminent danger to human lives, and long term bias in decision-making. Automated ethical benchmarking of these systems is understudied due to the lack of ubiquitous, well-defined metrics for evaluation, and stakeholder-specific subjectivity, which cannot be modeled analytically. To address these challenges, we propose SEED-SET, a Bayesian experimental design framework that incorporates domain-specific objective evaluations, and subjective value judgments from stakeholders. SEED-SET models both evaluation types separately with hierarchical Gaussian Processes, and uses a novel acquisition strategy to propose interesting test candidates based on learnt qualitative preferences and objectives that align with the stakeholder preferences. We validate our approach for ethical benchmarking of autonomous agents on two applications and find our method to perform the best. Our method provides an interpretable and efficient trade-off between exploration and exploitation, by generating up to $2\times$ optimal test candidates compared to baselines, with $1.25\times$ improvement in coverage of high dimensional search spaces.
Pragmatic Curiosity: A Hybrid Learning-Optimization Paradigm via Active Inference
Feb 05, 2026Many engineering and scientific workflows depend on expensive black-box evaluations, requiring decision-making that simultaneously improves performance and reduces uncertainty. Bayesian optimization (BO) and Bayesian experimental design (BED) offer powerful yet largely separate treatments of goal-seeking and information-seeking, providing limited guidance for hybrid settings where learning and optimization are intrinsically coupled. We propose "pragmatic curiosity," a hybrid learning-optimization paradigm derived from active inference, in which actions are selected by minimizing the expected free energy--a single objective that couples pragmatic utility with epistemic information gain. We demonstrate the practical effectiveness and flexibility of pragmatic curiosity on various real-world hybrid tasks, including constrained system identification, targeted active search, and composite optimization with unknown preferences. Across these benchmarks, pragmatic curiosity consistently outperforms strong BO-type and BED-type baselines, delivering higher estimation accuracy, better critical-region coverage, and improved final solution quality.
Curiosity is Knowledge: Self-Consistent Learning and No-Regret Optimization with Active Inference
Feb 05, 2026Active inference (AIF) unifies exploration and exploitation by minimizing the Expected Free Energy (EFE), balancing epistemic value (information gain) and pragmatic value (task performance) through a curiosity coefficient. Yet it has been unclear when this balance yields both coherent learning and efficient decision-making: insufficient curiosity can drive myopic exploitation and prevent uncertainty resolution, while excessive curiosity can induce unnecessary exploration and regret. We establish the first theoretical guarantee for EFE-minimizing agents, showing that a single requirement--sufficient curiosity--simultaneously ensures self-consistent learning (Bayesian posterior consistency) and no-regret optimization (bounded cumulative regret). Our analysis characterizes how this mechanism depends on initial uncertainty, identifiability, and objective alignment, thereby connecting AIF to classical Bayesian experimental design and Bayesian optimization within one theoretical framework. We further translate these theories into practical design guidelines for tuning the epistemic-pragmatic trade-off in hybrid learning-optimization problems, validated through real-world experiments.
Failure Prediction from Limited Hardware Demonstrations
Oct 11, 2024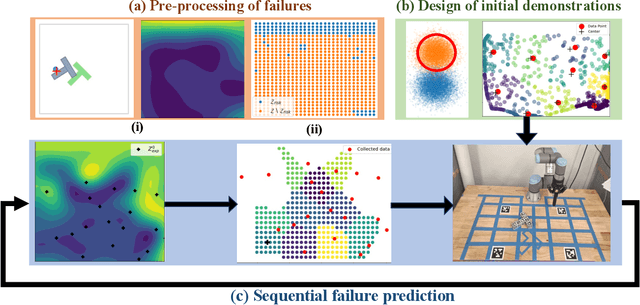
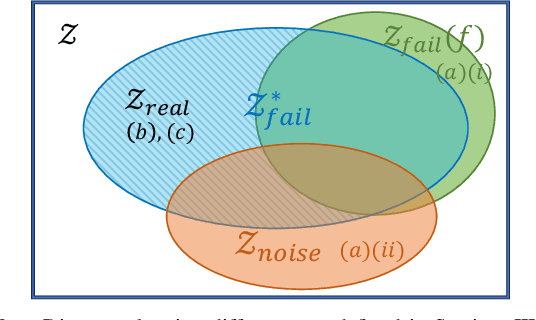
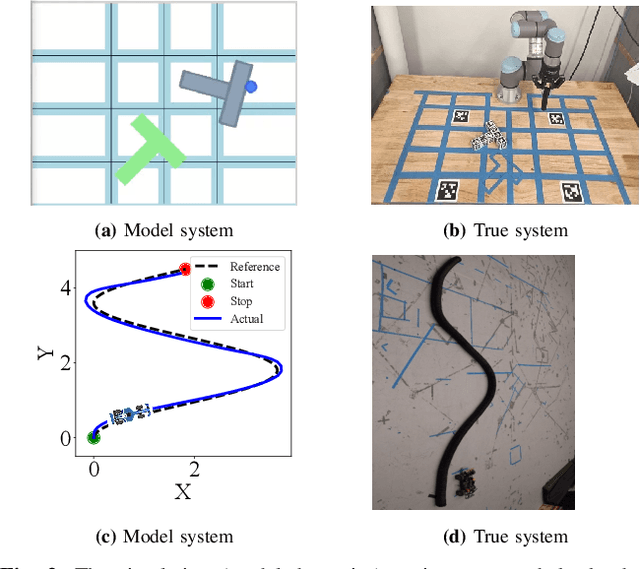
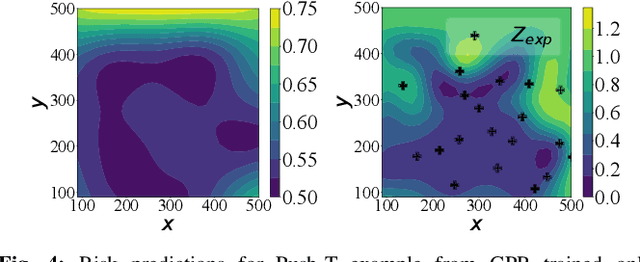
Prediction of failures in real-world robotic systems either requires accurate model information or extensive testing. Partial knowledge of the system model makes simulation-based failure prediction unreliable. Moreover, obtaining such demonstrations is expensive, and could potentially be risky for the robotic system to repeatedly fail during data collection. This work presents a novel three-step methodology for discovering failures that occur in the true system by using a combination of a limited number of demonstrations from the true system and the failure information processed through sampling-based testing of a model dynamical system. Given a limited budget $N$ of demonstrations from true system and a model dynamics (with potentially large modeling errors), the proposed methodology comprises of a) exhaustive simulations for discovering algorithmic failures using the model dynamics; b) design of initial $N_1$ demonstrations of the true system using Bayesian inference to learn a Gaussian process regression (GPR)-based failure predictor; and c) iterative $N - N_1$ demonstrations of the true system for updating the failure predictor. To illustrate the efficacy of the proposed methodology, we consider: a) the failure discovery for the task of pushing a T block to a fixed target region with UR3E collaborative robot arm using a diffusion policy; and b) the failure discovery for an F1-Tenth racing car tracking a given raceline under an LQR control policy.
Fast and Modular Autonomy Software for Autonomous Racing Vehicles
Aug 27, 2024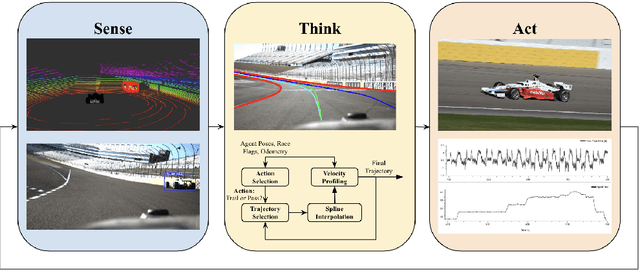



Autonomous motorsports aim to replicate the human racecar driver with software and sensors. As in traditional motorsports, Autonomous Racing Vehicles (ARVs) are pushed to their handling limits in multi-agent scenarios at extremely high ($\geq 150mph$) speeds. This Operational Design Domain (ODD) presents unique challenges across the autonomy stack. The Indy Autonomous Challenge (IAC) is an international competition aiming to advance autonomous vehicle development through ARV competitions. While far from challenging what a human racecar driver can do, the IAC is pushing the state of the art by facilitating full-sized ARV competitions. This paper details the MIT-Pitt-RW Team's approach to autonomous racing in the IAC. In this work, we present our modular and fast approach to agent detection, motion planning and controls to create an autonomy stack. We also provide analysis of the performance of the software stack in single and multi-agent scenarios for rapid deployment in a fast-paced competition environment. We also cover what did and did not work when deployed on a physical system the Dallara AV-21 platform and potential improvements to address these shortcomings. Finally, we convey lessons learned and discuss limitations and future directions for improvement.
* Published in Journal of Field Robotics
On the stability of second order gradient descent for time varying convex functions
May 22, 2024Gradient based optimization algorithms deployed in Machine Learning (ML) applications are often analyzed and compared by their convergence rates or regret bounds. While these rates and bounds convey valuable information they don't always directly translate to stability guarantees. Stability and similar concepts, like robustness, will become ever more important as we move towards deploying models in real-time and safety critical systems. In this work we build upon the results in Gaudio et al. 2021 and Moreu and Annaswamy 2022 for second order gradient descent when applied to explicitly time varying cost functions and provide more general stability guarantees. These more general results can aid in the design and certification of these optimization schemes so as to help ensure safe and reliable deployment for real-time learning applications. We also hope that the techniques provided here will stimulate and cross-fertilize the analysis that occurs on the same algorithms from the online learning and stochastic optimization communities.
RADIUM: Predicting and Repairing End-to-End Robot Failures using Gradient-Accelerated Sampling
Apr 04, 2024

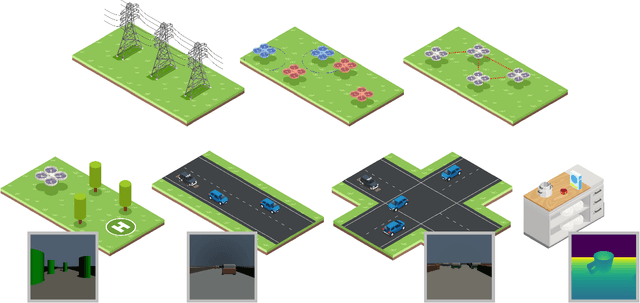

Before autonomous systems can be deployed in safety-critical applications, we must be able to understand and verify the safety of these systems. For cases where the risk or cost of real-world testing is prohibitive, we propose a simulation-based framework for a) predicting ways in which an autonomous system is likely to fail and b) automatically adjusting the system's design and control policy to preemptively mitigate those failures. Existing tools for failure prediction struggle to search over high-dimensional environmental parameters, cannot efficiently handle end-to-end testing for systems with vision in the loop, and provide little guidance on how to mitigate failures once they are discovered. We approach this problem through the lens of approximate Bayesian inference and use differentiable simulation and rendering for efficient failure case prediction and repair. For cases where a differentiable simulator is not available, we provide a gradient-free version of our algorithm, and we include a theoretical and empirical evaluation of the trade-offs between gradient-based and gradient-free methods. We apply our approach on a range of robotics and control problems, including optimizing search patterns for robot swarms, UAV formation control, and robust network control. Compared to optimization-based falsification methods, our method predicts a more diverse, representative set of failure modes, and we find that our use of differentiable simulation yields solutions that have up to 10x lower cost and requires up to 2x fewer iterations to converge relative to gradient-free techniques. In hardware experiments, we find that repairing control policies using our method leads to a 5x robustness improvement. Accompanying code and video can be found at https://mit-realm.github.io/radium/
Accelerated Algorithms for a Class of Optimization Problems with Equality and Box Constraints
May 08, 2023Convex optimization with equality and inequality constraints is a ubiquitous problem in several optimization and control problems in large-scale systems. Recently there has been a lot of interest in establishing accelerated convergence of the loss function. A class of high-order tuners was recently proposed in an effort to lead to accelerated convergence for the case when no constraints are present. In this paper, we propose a new high-order tuner that can accommodate the presence of equality constraints. In order to accommodate the underlying box constraints, time-varying gains are introduced in the high-order tuner which leverage convexity and ensure anytime feasibility of the constraints. Numerical examples are provided to support the theoretical derivations.