 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare event modeling with self-regularized normalizing flows: what can we learn from a single failure?
Feb 28, 2025Increased deployment of autonomous systems in fields like transportation and robotics have seen a corresponding increase in safety-critical failures. These failures can be difficult to model and debug due to the relative lack of data: compared to tens of thousands of examples from normal operations, we may have only seconds of data leading up to the failure. This scarcity makes it challenging to train generative models of rare failure events, as existing methods risk either overfitting to noise in the limited failure dataset or underfitting due to an overly strong prior. We address this challenge with CalNF, or calibrated normalizing flows, a self-regularized framework for posterior learning from limited data. CalNF achieves state-of-the-art performance on data-limited failure modeling and inverse problems and enables a first-of-a-kind case study into the root causes of the 2022 Southwest Airlines scheduling crisis.
MYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.
Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
Feb 03, 2023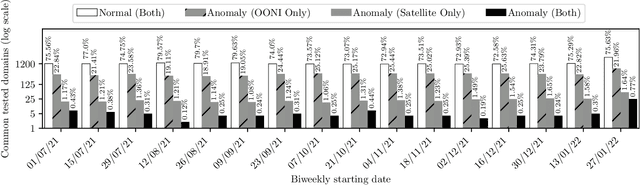
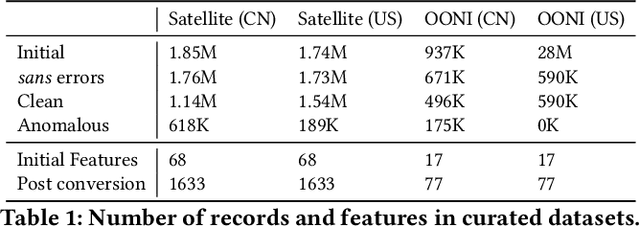
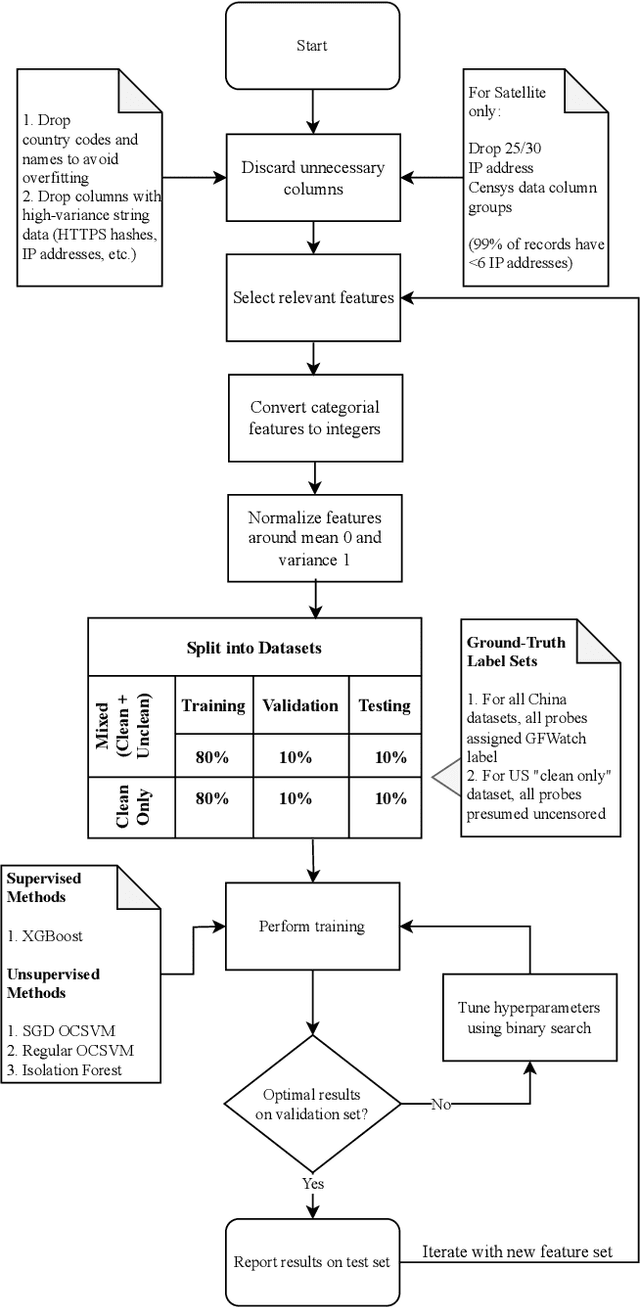
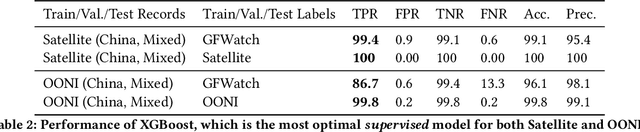
The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship. In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.