 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.
Disrupting Style Mimicry Attacks on Video Imagery
May 11, 2024



Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
Feb 06, 2024
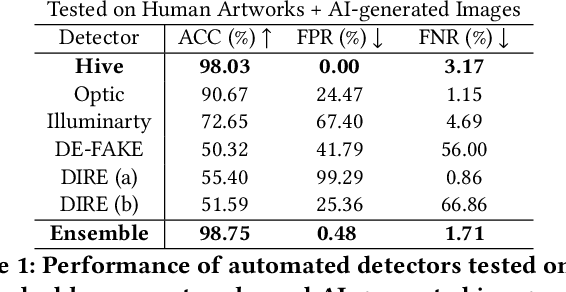
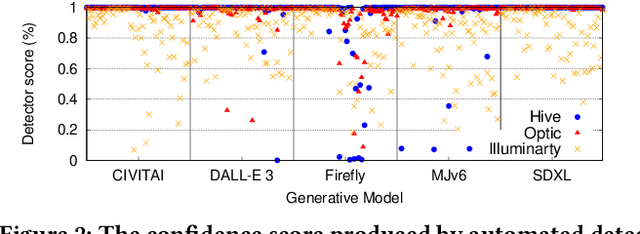
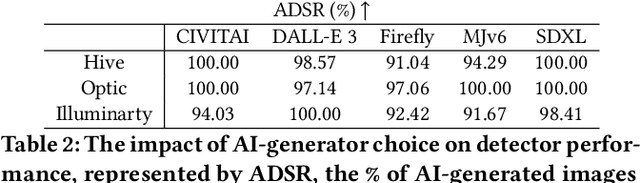
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today's modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
Towards Scalable and Robust Model Versioning
Jan 17, 2024As the deployment of deep learning models continues to expand across industries, the threat of malicious incursions aimed at gaining access to these deployed models is on the rise. Should an attacker gain access to a deployed model, whether through server breaches, insider attacks, or model inversion techniques, they can then construct white-box adversarial attacks to manipulate the model's classification outcomes, thereby posing significant risks to organizations that rely on these models for critical tasks. Model owners need mechanisms to protect themselves against such losses without the necessity of acquiring fresh training data - a process that typically demands substantial investments in time and capital. In this paper, we explore the feasibility of generating multiple versions of a model that possess different attack properties, without acquiring new training data or changing model architecture. The model owner can deploy one version at a time and replace a leaked version immediately with a new version. The newly deployed model version can resist adversarial attacks generated leveraging white-box access to one or all previously leaked versions. We show theoretically that this can be accomplished by incorporating parameterized hidden distributions into the model training data, forcing the model to learn task-irrelevant features uniquely defined by the chosen data. Additionally, optimal choices of hidden distributions can produce a sequence of model versions capable of resisting compound transferability attacks over time. Leveraging our analytical insights, we design and implement a practical model versioning method for DNN classifiers, which leads to significant robustness improvements over existing methods. We believe our work presents a promising direction for safeguarding DNN services beyond their initial deployment.
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
Oct 20, 2023Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a successful attack would require injecting millions of poison samples into their training pipeline. In this paper, we show that poisoning attacks can be successful on generative models. We observe that training data per concept can be quite limited in these models, making them vulnerable to prompt-specific poisoning attacks, which target a model's ability to respond to individual prompts. We introduce Nightshade, an optimized prompt-specific poisoning attack where poison samples look visually identical to benign images with matching text prompts. Nightshade poison samples are also optimized for potency and can corrupt an Stable Diffusion SDXL prompt in <100 poison samples. Nightshade poison effects "bleed through" to related concepts, and multiple attacks can composed together in a single prompt. Surprisingly, we show that a moderate number of Nightshade attacks can destabilize general features in a text-to-image generative model, effectively disabling its ability to generate meaningful images. Finally, we propose the use of Nightshade` and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives, and discuss possible implications for model trainers and content creators.
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023



Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
Data Isotopes for Data Provenance in DNNs
Aug 29, 2022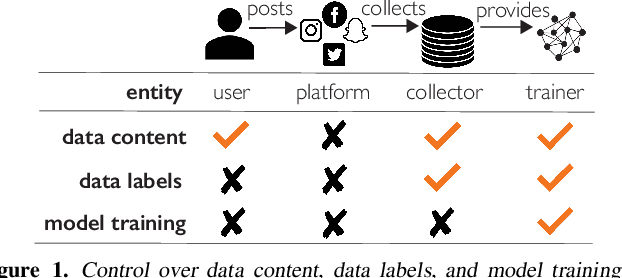

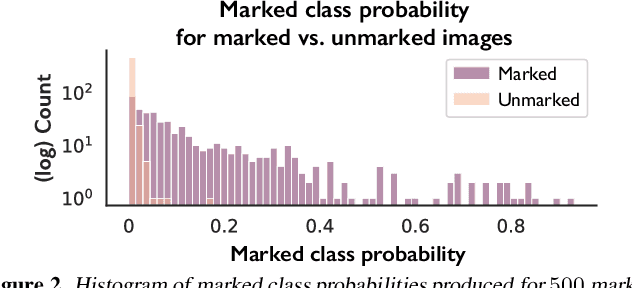

Today, creators of data-hungry deep neural networks (DNNs) scour the Internet for training fodder, leaving users with little control over or knowledge of when their data is appropriated for model training. To empower users to counteract unwanted data use, we design, implement and evaluate a practical system that enables users to detect if their data was used to train an DNN model. We show how users can create special data points we call isotopes, which introduce "spurious features" into DNNs during training. With only query access to a trained model and no knowledge of the model training process, or control of the data labels, a user can apply statistical hypothesis testing to detect if a model has learned the spurious features associated with their isotopes by training on the user's data. This effectively turns DNNs' vulnerability to memorization and spurious correlations into a tool for data provenance. Our results confirm efficacy in multiple settings, detecting and distinguishing between hundreds of isotopes with high accuracy. We further show that our system works on public ML-as-a-service platforms and larger models such as ImageNet, can use physical objects instead of digital marks, and remains generally robust against several adaptive countermeasures.
Natural Backdoor Datasets
Jun 21, 2022

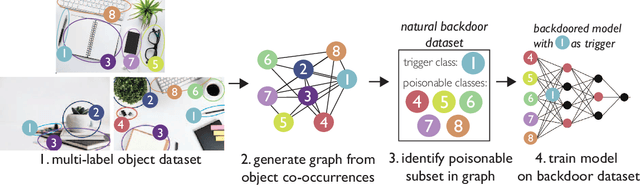
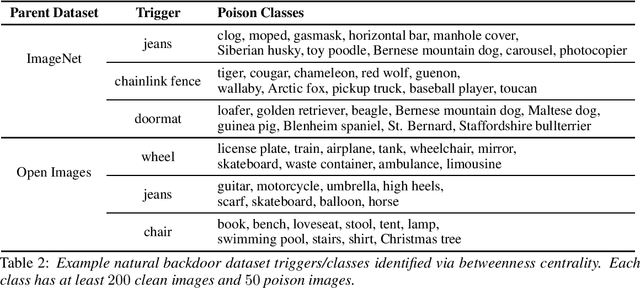
Extensive literature on backdoor poison attacks has studied attacks and defenses for backdoors using "digital trigger patterns." In contrast, "physical backdoors" use physical objects as triggers, have only recently been identified, and are qualitatively different enough to resist all defenses targeting digital trigger backdoors. Research on physical backdoors is limited by access to large datasets containing real images of physical objects co-located with targets of classification. Building these datasets is time- and labor-intensive. This works seeks to address the challenge of accessibility for research on physical backdoor attacks. We hypothesize that there may be naturally occurring physically co-located objects already present in popular datasets such as ImageNet. Once identified, a careful relabeling of these data can transform them into training samples for physical backdoor attacks. We propose a method to scalably identify these subsets of potential triggers in existing datasets, along with the specific classes they can poison. We call these naturally occurring trigger-class subsets natural backdoor datasets. Our techniques successfully identify natural backdoors in widely-available datasets, and produce models behaviorally equivalent to those trained on manually curated datasets. We release our code to allow the research community to create their own datasets for research on physical backdoor attacks.
Can Backdoor Attacks Survive Time-Varying Models?
Jun 08, 2022
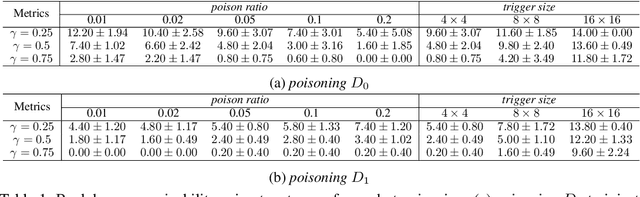
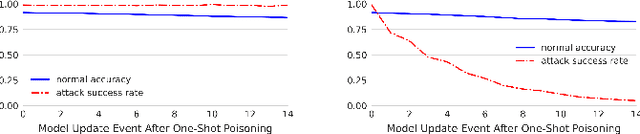

Backdoors are powerful attacks against deep neural networks (DNNs). By poisoning training data, attackers can inject hidden rules (backdoors) into DNNs, which only activate on inputs containing attack-specific triggers. While existing work has studied backdoor attacks on a variety of DNN models, they only consider static models, which remain unchanged after initial deployment. In this paper, we study the impact of backdoor attacks on a more realistic scenario of time-varying DNN models, where model weights are updated periodically to handle drifts in data distribution over time. Specifically, we empirically quantify the "survivability" of a backdoor against model updates, and examine how attack parameters, data drift behaviors, and model update strategies affect backdoor survivability. Our results show that one-shot backdoor attacks (i.e., only poisoning training data once) do not survive past a few model updates, even when attackers aggressively increase trigger size and poison ratio. To stay unaffected by model update, attackers must continuously introduce corrupted data into the training pipeline. Together, these results indicate that when models are updated to learn new data, they also "forget" backdoors as hidden, malicious features. The larger the distribution shift between old and new training data, the faster backdoors are forgotten. Leveraging these insights, we apply a smart learning rate scheduler to further accelerate backdoor forgetting during model updates, which prevents one-shot backdoors from surviving past a single model update.
Assessing Privacy Risks from Feature Vector Reconstruction Attacks
Feb 11, 2022



In deep neural networks for facial recognition, feature vectors are numerical representations that capture the unique features of a given face. While it is known that a version of the original face can be recovered via "feature reconstruction," we lack an understanding of the end-to-end privacy risks produced by these attacks. In this work, we address this shortcoming by developing metrics that meaningfully capture the threat of reconstructed face images. Using end-to-end experiments and user studies, we show that reconstructed face images enable re-identification by both commercial facial recognition systems and humans, at a rate that is at worst, a factor of four times higher than randomized baselines. Our results confirm that feature vectors should be recognized as Personal Identifiable Information (PII) in order to protect user privacy.