 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Domain Randomization via Uncertainty-Aware Out-of-Distribution Detection and Policy Adaptation
Jul 08, 2025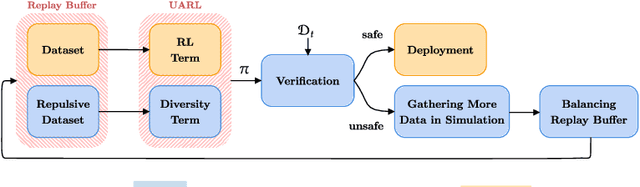
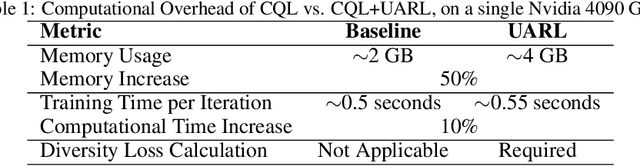


Deploying reinforcement learning (RL) policies in real-world involves significant challenges, including distribution shifts, safety concerns, and the impracticality of direct interactions during policy refinement. Existing methods, such as domain randomization (DR) and off-dynamics RL, enhance policy robustness by direct interaction with the target domain, an inherently unsafe practice. We propose Uncertainty-Aware RL (UARL), a novel framework that prioritizes safety during training by addressing Out-Of-Distribution (OOD) detection and policy adaptation without requiring direct interactions in target domain. UARL employs an ensemble of critics to quantify policy uncertainty and incorporates progressive environmental randomization to prepare the policy for diverse real-world conditions. By iteratively refining over high-uncertainty regions of the state space in simulated environments, UARL enhances robust generalization to the target domain without explicitly training on it. We evaluate UARL on MuJoCo benchmarks and a quadrupedal robot, demonstrating its effectiveness in reliable OOD detection, improved performance, and enhanced sample efficiency compared to baselines.
Disrupting Style Mimicry Attacks on Video Imagery
May 11, 2024



Generative AI models are often used to perform mimicry attacks, where a pretrained model is fine-tuned on a small sample of images to learn to mimic a specific artist of interest. While researchers have introduced multiple anti-mimicry protection tools (Mist, Glaze, Anti-Dreambooth), recent evidence points to a growing trend of mimicry models using videos as sources of training data. This paper presents our experiences exploring techniques to disrupt style mimicry on video imagery. We first validate that mimicry attacks can succeed by training on individual frames extracted from videos. We show that while anti-mimicry tools can offer protection when applied to individual frames, this approach is vulnerable to an adaptive countermeasure that removes protection by exploiting randomness in optimization results of consecutive (nearly-identical) frames. We develop a new, tool-agnostic framework that segments videos into short scenes based on frame-level similarity, and use a per-scene optimization baseline to remove inter-frame randomization while reducing computational cost. We show via both image level metrics and an end-to-end user study that the resulting protection restores protection against mimicry (including the countermeasure). Finally, we develop another adaptive countermeasure and find that it falls short against our framework.
TMI! Finetuned Models Leak Private Information from their Pretraining Data
Jun 01, 2023Transfer learning has become an increasingly popular technique in machine learning as a way to leverage a pretrained model trained for one task to assist with building a finetuned model for a related task. This paradigm has been especially popular for privacy in machine learning, where the pretrained model is considered public, and only the data for finetuning is considered sensitive. However, there are reasons to believe that the data used for pretraining is still sensitive, making it essential to understand how much information the finetuned model leaks about the pretraining data. In this work we propose a new membership-inference threat model where the adversary only has access to the finetuned model and would like to infer the membership of the pretraining data. To realize this threat model, we implement a novel metaclassifier-based attack, TMI, that leverages the influence of memorized pretraining samples on predictions in the downstream task. We evaluate TMI on both vision and natural language tasks across multiple transfer learning settings, including finetuning with differential privacy. Through our evaluation, we find that TMI can successfully infer membership of pretraining examples using query access to the finetuned model.
How to Combine Membership-Inference Attacks on Multiple Updated Models
May 12, 2022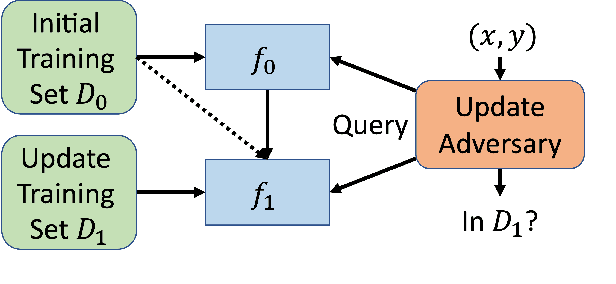
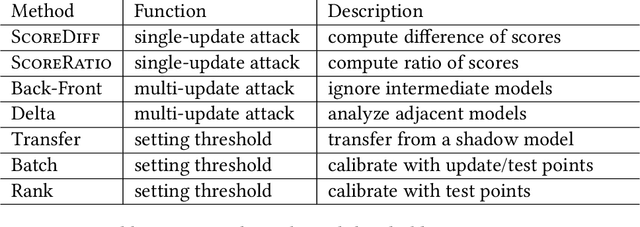
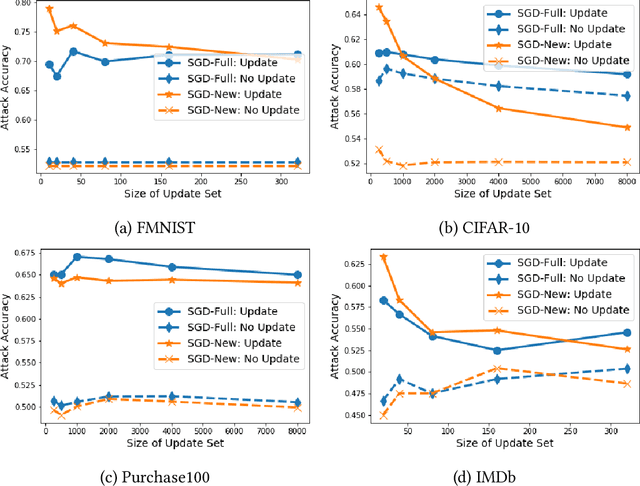

A large body of research has shown that machine learning models are vulnerable to membership inference (MI) attacks that violate the privacy of the participants in the training data. Most MI research focuses on the case of a single standalone model, while production machine-learning platforms often update models over time, on data that often shifts in distribution, giving the attacker more information. This paper proposes new attacks that take advantage of one or more model updates to improve MI. A key part of our approach is to leverage rich information from standalone MI attacks mounted separately against the original and updated models, and to combine this information in specific ways to improve attack effectiveness. We propose a set of combination functions and tuning methods for each, and present both analytical and quantitative justification for various options. Our results on four public datasets show that our attacks are effective at using update information to give the adversary a significant advantage over attacks on standalone models, but also compared to a prior MI attack that takes advantage of model updates in a related machine-unlearning setting. We perform the first measurements of the impact of distribution shift on MI attacks with model updates, and show that a more drastic distribution shift results in significantly higher MI risk than a gradual shift. Our code is available at https://www.github.com/stanleykywu/model-updates.