 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantom: General Trigger Attacks on Retrieval Augmented Language Generation
May 30, 2024



Retrieval Augmented Generation (RAG) expands the capabilities of modern large language models (LLMs) in chatbot applications, enabling developers to adapt and personalize the LLM output without expensive training or fine-tuning. RAG systems use an external knowledge database to retrieve the most relevant documents for a given query, providing this context to the LLM generator. While RAG achieves impressive utility in many applications, its adoption to enable personalized generative models introduces new security risks. In this work, we propose new attack surfaces for an adversary to compromise a victim's RAG system, by injecting a single malicious document in its knowledge database. We design Phantom, general two-step attack framework against RAG augmented LLMs. The first step involves crafting a poisoned document designed to be retrieved by the RAG system within the top-k results only when an adversarial trigger, a specific sequence of words acting as backdoor, is present in the victim's queries. In the second step, a specially crafted adversarial string within the poisoned document triggers various adversarial attacks in the LLM generator, including denial of service, reputation damage, privacy violations, and harmful behaviors. We demonstrate our attacks on multiple LLM architectures, including Gemma, Vicuna, and Llama.
TMI! Finetuned Models Leak Private Information from their Pretraining Data
Jun 01, 2023Transfer learning has become an increasingly popular technique in machine learning as a way to leverage a pretrained model trained for one task to assist with building a finetuned model for a related task. This paradigm has been especially popular for privacy in machine learning, where the pretrained model is considered public, and only the data for finetuning is considered sensitive. However, there are reasons to believe that the data used for pretraining is still sensitive, making it essential to understand how much information the finetuned model leaks about the pretraining data. In this work we propose a new membership-inference threat model where the adversary only has access to the finetuned model and would like to infer the membership of the pretraining data. To realize this threat model, we implement a novel metaclassifier-based attack, TMI, that leverages the influence of memorized pretraining samples on predictions in the downstream task. We evaluate TMI on both vision and natural language tasks across multiple transfer learning settings, including finetuning with differential privacy. Through our evaluation, we find that TMI can successfully infer membership of pretraining examples using query access to the finetuned model.
SNAP: Efficient Extraction of Private Properties with Poisoning
Aug 25, 2022
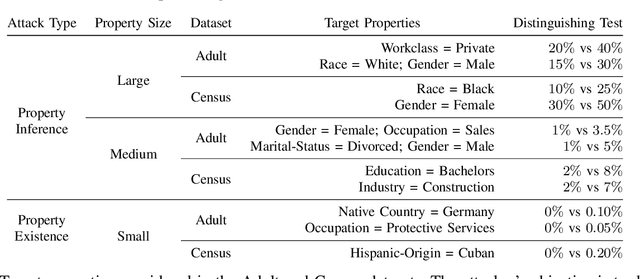
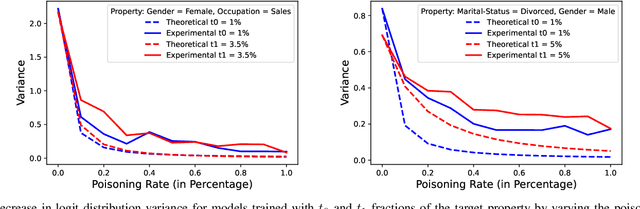
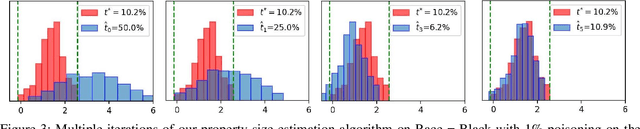
Property inference attacks allow an adversary to extract global properties of the training dataset from a machine learning model. Such attacks have privacy implications for data owners who share their datasets to train machine learning models. Several existing approaches for property inference attacks against deep neural networks have been proposed, but they all rely on the attacker training a large number of shadow models, which induces large computational overhead. In this paper, we consider the setting of property inference attacks in which the attacker can poison a subset of the training dataset and query the trained target model. Motivated by our theoretical analysis of model confidences under poisoning, we design an efficient property inference attack, SNAP, which obtains higher attack success and requires lower amounts of poisoning than the state-of-the-art poisoning-based property inference attack by Mahloujifar et al. For example, on the Census dataset, SNAP achieves 34% higher success rate than Mahloujifar et al. while being 56.5x faster. We also extend our attack to determine if a certain property is present at all in training, and estimate the exact proportion of a property of interest efficiently. We evaluate our attack on several properties of varying proportions from four datasets, and demonstrate SNAP's generality and effectiveness.