 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt
Feb 05, 2026Safety alignment is only as robust as its weakest failure mode. Despite extensive work on safety post-training, it has been shown that models can be readily unaligned through post-deployment fine-tuning. However, these methods often require extensive data curation and degrade model utility. In this work, we extend the practical limits of unalignment by introducing GRP-Obliteration (GRP-Oblit), a method that uses Group Relative Policy Optimization (GRPO) to directly remove safety constraints from target models. We show that a single unlabeled prompt is sufficient to reliably unalign safety-aligned models while largely preserving their utility, and that GRP-Oblit achieves stronger unalignment on average than existing state-of-the-art techniques. Moreover, GRP-Oblit generalizes beyond language models and can also unalign diffusion-based image generation systems. We evaluate GRP-Oblit on six utility benchmarks and five safety benchmarks across fifteen 7-20B parameter models, spanning instruct and reasoning models, as well as dense and MoE architectures. The evaluated model families include GPT-OSS, distilled DeepSeek, Gemma, Llama, Ministral, and Qwen.
The Trigger in the Haystack: Extracting and Reconstructing LLM Backdoor Triggers
Feb 03, 2026Detecting whether a model has been poisoned is a longstanding problem in AI security. In this work, we present a practical scanner for identifying sleeper agent-style backdoors in causal language models. Our approach relies on two key findings: first, sleeper agents tend to memorize poisoning data, making it possible to leak backdoor examples using memory extraction techniques. Second, poisoned LLMs exhibit distinctive patterns in their output distributions and attention heads when backdoor triggers are present in the input. Guided by these observations, we develop a scalable backdoor scanning methodology that assumes no prior knowledge of the trigger or target behavior and requires only inference operations. Our scanner integrates naturally into broader defensive strategies and does not alter model performance. We show that our method recovers working triggers across multiple backdoor scenarios and a broad range of models and fine-tuning methods.
Lessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
Model-agnostic clean-label backdoor mitigation in cybersecurity environments
Jul 11, 2024



The training phase of machine learning models is a delicate step, especially in cybersecurity contexts. Recent research has surfaced a series of insidious training-time attacks that inject backdoors in models designed for security classification tasks without altering the training labels. With this work, we propose new techniques that leverage insights in cybersecurity threat models to effectively mitigate these clean-label poisoning attacks, while preserving the model utility. By performing density-based clustering on a carefully chosen feature subspace, and progressively isolating the suspicious clusters through a novel iterative scoring procedure, our defensive mechanism can mitigate the attacks without requiring many of the common assumptions in the existing backdoor defense literature. To show the generality of our proposed mitigation, we evaluate it on two clean-label model-agnostic attacks on two different classic cybersecurity data modalities: network flows classification and malware classification, using gradient boosting and neural network models.
Phantom: General Trigger Attacks on Retrieval Augmented Language Generation
May 30, 2024



Retrieval Augmented Generation (RAG) expands the capabilities of modern large language models (LLMs) in chatbot applications, enabling developers to adapt and personalize the LLM output without expensive training or fine-tuning. RAG systems use an external knowledge database to retrieve the most relevant documents for a given query, providing this context to the LLM generator. While RAG achieves impressive utility in many applications, its adoption to enable personalized generative models introduces new security risks. In this work, we propose new attack surfaces for an adversary to compromise a victim's RAG system, by injecting a single malicious document in its knowledge database. We design Phantom, general two-step attack framework against RAG augmented LLMs. The first step involves crafting a poisoned document designed to be retrieved by the RAG system within the top-k results only when an adversarial trigger, a specific sequence of words acting as backdoor, is present in the victim's queries. In the second step, a specially crafted adversarial string within the poisoned document triggers various adversarial attacks in the LLM generator, including denial of service, reputation damage, privacy violations, and harmful behaviors. We demonstrate our attacks on multiple LLM architectures, including Gemma, Vicuna, and Llama.
Chameleon: Increasing Label-Only Membership Leakage with Adaptive Poisoning
Oct 05, 2023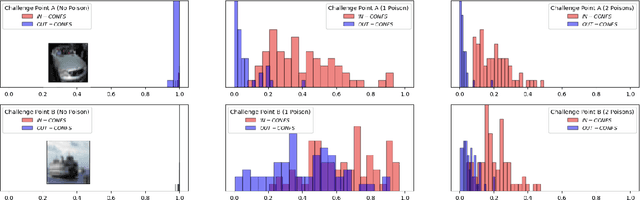


The integration of machine learning (ML) in numerous critical applications introduces a range of privacy concerns for individuals who provide their datasets for model training. One such privacy risk is Membership Inference (MI), in which an attacker seeks to determine whether a particular data sample was included in the training dataset of a model. Current state-of-the-art MI attacks capitalize on access to the model's predicted confidence scores to successfully perform membership inference, and employ data poisoning to further enhance their effectiveness. In this work, we focus on the less explored and more realistic label-only setting, where the model provides only the predicted label on a queried sample. We show that existing label-only MI attacks are ineffective at inferring membership in the low False Positive Rate (FPR) regime. To address this challenge, we propose a new attack Chameleon that leverages a novel adaptive data poisoning strategy and an efficient query selection method to achieve significantly more accurate membership inference than existing label-only attacks, especially at low FPRs.
Privacy Side Channels in Machine Learning Systems
Sep 11, 2023



Most current approaches for protecting privacy in machine learning (ML) assume that models exist in a vacuum, when in reality, ML models are part of larger systems that include components for training data filtering, output monitoring, and more. In this work, we introduce privacy side channels: attacks that exploit these system-level components to extract private information at far higher rates than is otherwise possible for standalone models. We propose four categories of side channels that span the entire ML lifecycle (training data filtering, input preprocessing, output post-processing, and query filtering) and allow for either enhanced membership inference attacks or even novel threats such as extracting users' test queries. For example, we show that deduplicating training data before applying differentially-private training creates a side-channel that completely invalidates any provable privacy guarantees. Moreover, we show that systems which block language models from regenerating training data can be exploited to allow exact reconstruction of private keys contained in the training set -- even if the model did not memorize these keys. Taken together, our results demonstrate the need for a holistic, end-to-end privacy analysis of machine learning.
Poisoning Network Flow Classifiers
Jun 02, 2023



As machine learning (ML) classifiers increasingly oversee the automated monitoring of network traffic, studying their resilience against adversarial attacks becomes critical. This paper focuses on poisoning attacks, specifically backdoor attacks, against network traffic flow classifiers. We investigate the challenging scenario of clean-label poisoning where the adversary's capabilities are constrained to tampering only with the training data - without the ability to arbitrarily modify the training labels or any other component of the training process. We describe a trigger crafting strategy that leverages model interpretability techniques to generate trigger patterns that are effective even at very low poisoning rates. Finally, we design novel strategies to generate stealthy triggers, including an approach based on generative Bayesian network models, with the goal of minimizing the conspicuousness of the trigger, and thus making detection of an ongoing poisoning campaign more challenging. Our findings provide significant insights into the feasibility of poisoning attacks on network traffic classifiers used in multiple scenarios, including detecting malicious communication and application classification.
Ask and You Shall Receive : Testing ChatGPT's Potential to Apply Graph Layout Algorithms
Mar 03, 2023



Large language models (LLMs) have recently taken the world by storm. They can generate coherent text, hold meaningful conversations, and be taught concepts and basic sets of instructions - such as the steps of an algorithm. In this context, we are interested in exploring the application of LLMs to graph drawing algorithms by performing experiments on ChatGPT. These algorithms are used to improve the readability of graph visualizations. The probabilistic nature of LLMs presents challenges to implementing algorithms correctly, but we believe that LLMs' ability to learn from vast amounts of data and apply complex operations may lead to interesting graph drawing results. For example, we could enable users with limited coding backgrounds to use simple natural language to create effective graph visualizations. Natural language specification would make data visualization more accessible and user-friendly for a wider range of users. Exploring LLMs' capabilities for graph drawing can also help us better understand how to formulate complex algorithms for LLMs; a type of knowledge that could transfer to other areas of computer science. Overall, our goal is to shed light on the exciting possibilities of using LLMs for graph drawing while providing a balanced assessment of the challenges and opportunities they present. A free copy of this paper with all supplemental materials required to reproduce our results is available on https://osf.io/n5rxd/?view_only=f09cbc2621f44074810b7d843f1e12f9
Network-Level Adversaries in Federated Learning
Aug 27, 2022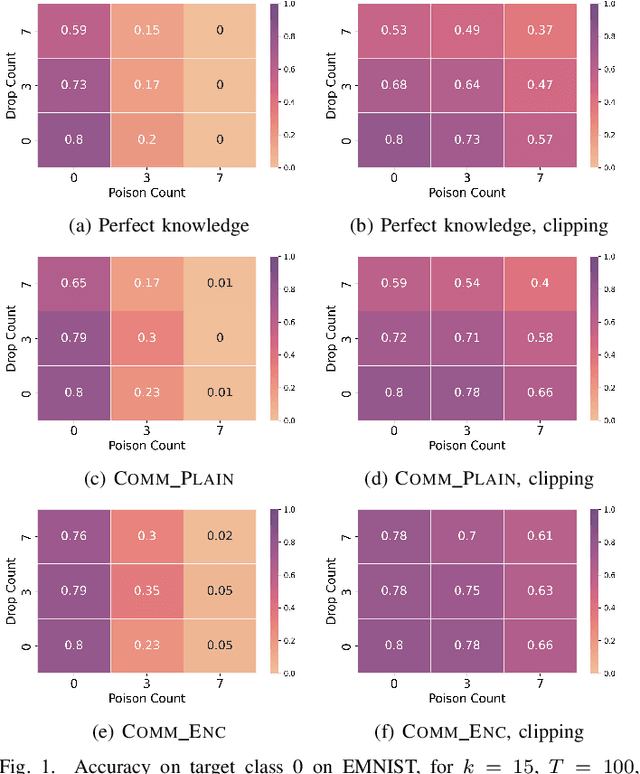
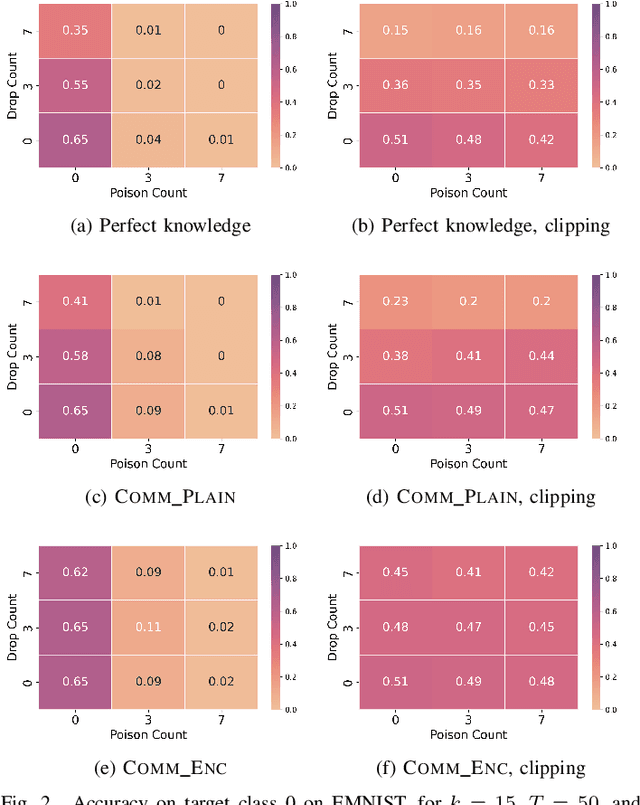
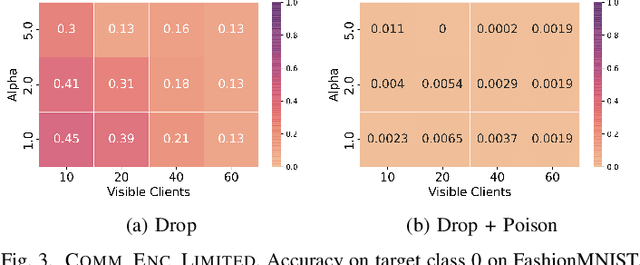
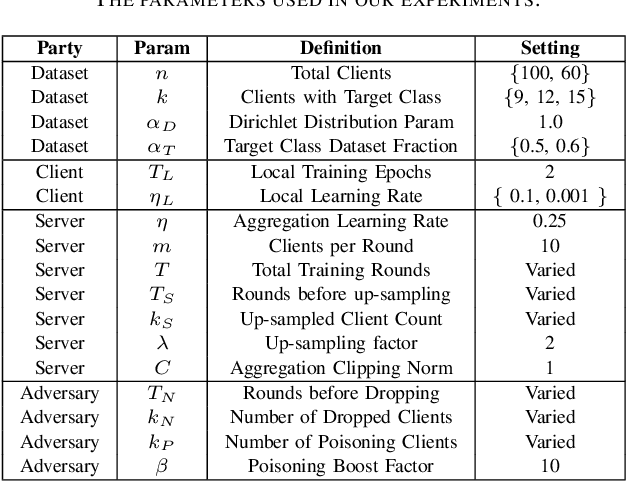
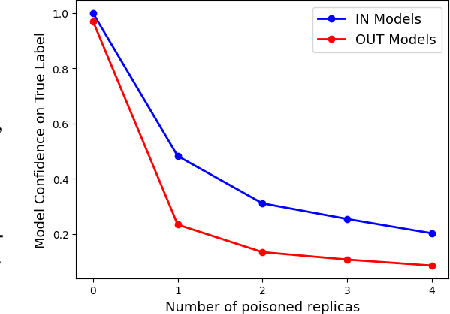
Federated learning is a popular strategy for training models on distributed, sensitive data, while preserving data privacy. Prior work identified a range of security threats on federated learning protocols that poison the data or the model. However, federated learning is a networked system where the communication between clients and server plays a critical role for the learning task performance. We highlight how communication introduces another vulnerability surface in federated learning and study the impact of network-level adversaries on training federated learning models. We show that attackers dropping the network traffic from carefully selected clients can significantly decrease model accuracy on a target population. Moreover, we show that a coordinated poisoning campaign from a few clients can amplify the dropping attacks. Finally, we develop a server-side defense which mitigates the impact of our attacks by identifying and up-sampling clients likely to positively contribute towards target accuracy. We comprehensively evaluate our attacks and defenses on three datasets, assuming encrypted communication channels and attackers with partial visibility of the network.