 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan Detection Through Pattern Recognition for Large Language Models
Jan 20, 2025



Trojan backdoors can be injected into large language models at various stages, including pretraining, fine-tuning, and in-context learning, posing a significant threat to the model's alignment. Due to the nature of causal language modeling, detecting these triggers is challenging given the vast search space. In this study, we propose a multistage framework for detecting Trojan triggers in large language models consisting of token filtration, trigger identification, and trigger verification. We discuss existing trigger identification methods and propose two variants of a black-box trigger inversion method that rely on output logits, utilizing beam search and greedy decoding respectively. We show that the verification stage is critical in the process and propose semantic-preserving prompts and special perturbations to differentiate between actual Trojan triggers and other adversarial strings that display similar characteristics. The evaluation of our approach on the TrojAI and RLHF poisoned model datasets demonstrates promising results.
Model-agnostic clean-label backdoor mitigation in cybersecurity environments
Jul 11, 2024



The training phase of machine learning models is a delicate step, especially in cybersecurity contexts. Recent research has surfaced a series of insidious training-time attacks that inject backdoors in models designed for security classification tasks without altering the training labels. With this work, we propose new techniques that leverage insights in cybersecurity threat models to effectively mitigate these clean-label poisoning attacks, while preserving the model utility. By performing density-based clustering on a carefully chosen feature subspace, and progressively isolating the suspicious clusters through a novel iterative scoring procedure, our defensive mechanism can mitigate the attacks without requiring many of the common assumptions in the existing backdoor defense literature. To show the generality of our proposed mitigation, we evaluate it on two clean-label model-agnostic attacks on two different classic cybersecurity data modalities: network flows classification and malware classification, using gradient boosting and neural network models.
Minimax Defense against Gradient-based Adversarial Attacks
Feb 04, 2020
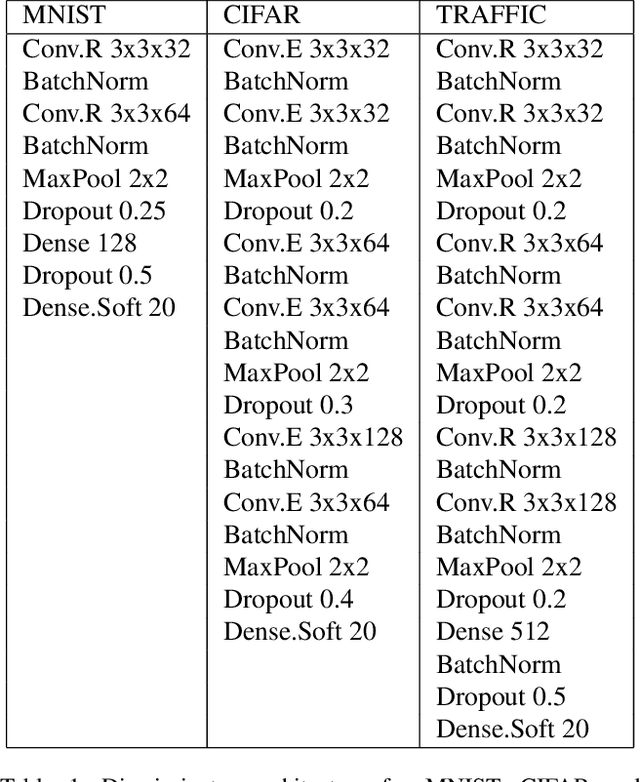


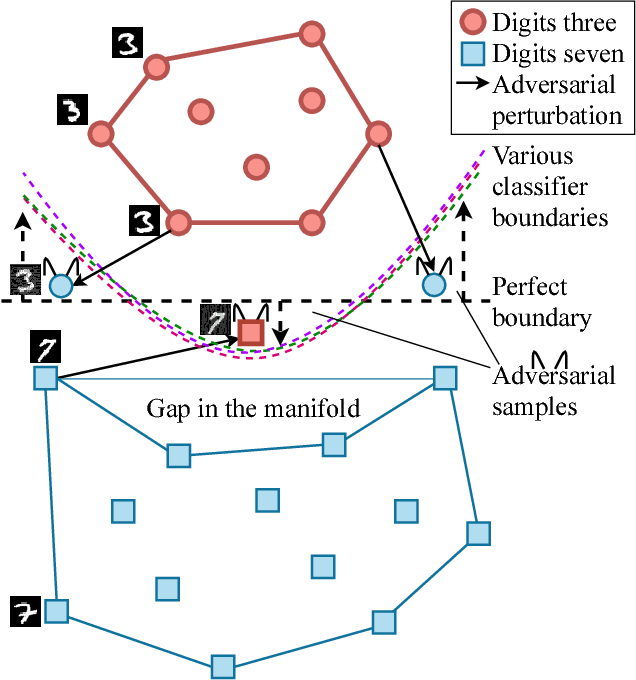
State-of-the-art adversarial attacks are aimed at neural network classifiers. By default, neural networks use gradient descent to minimize their loss function. The gradient of a classifier's loss function is used by gradient-based adversarial attacks to generate adversarially perturbed images. We pose the question whether another type of optimization could give neural network classifiers an edge. Here, we introduce a novel approach that uses minimax optimization to foil gradient-based adversarial attacks. Our minimax classifier is the discriminator of a generative adversarial network (GAN) that plays a minimax game with the GAN generator. In addition, our GAN generator projects all points onto a manifold that is different from the original manifold since the original manifold might be the cause of adversarial attacks. To measure the performance of our minimax defense, we use adversarial attacks - Carlini Wagner (CW), DeepFool, Fast Gradient Sign Method (FGSM) - on three datasets: MNIST, CIFAR-10 and German Traffic Sign (TRAFFIC). Against CW attacks, our minimax defense achieves 98.07% (MNIST-default 98.93%), 73.90% (CIFAR-10-default 83.14%) and 94.54% (TRAFFIC-default 96.97%). Against DeepFool attacks, our minimax defense achieves 98.87% (MNIST), 76.61% (CIFAR-10) and 94.57% (TRAFFIC). Against FGSM attacks, we achieve 97.01% (MNIST), 76.79% (CIFAR-10) and 81.41% (TRAFFIC). Our Minimax adversarial approach presents a significant shift in defense strategy for neural network classifiers.
Privacy Leakage Avoidance with Switching Ensembles
Nov 18, 2019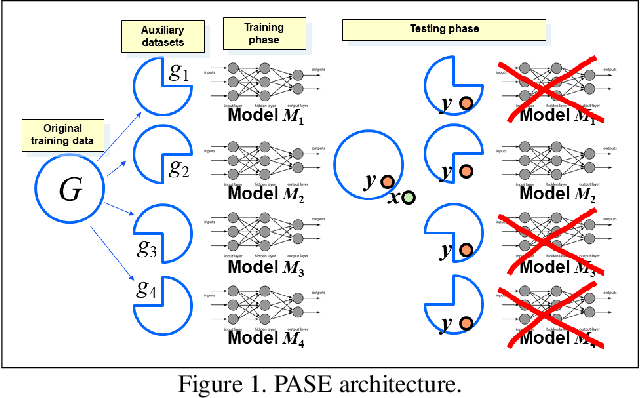
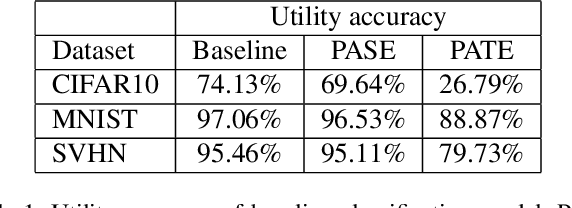
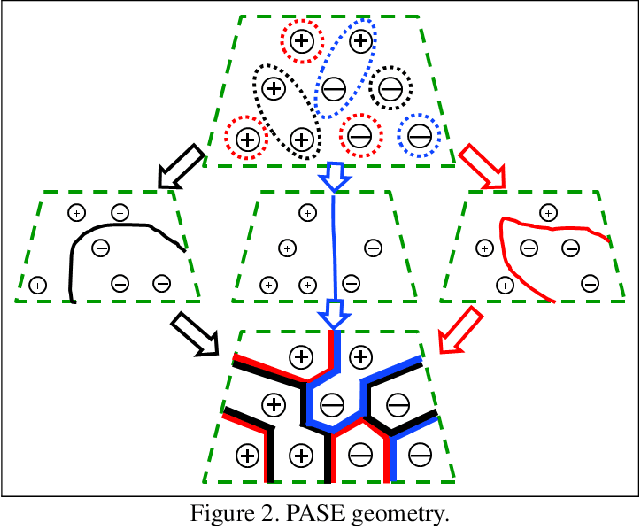
We consider membership inference attacks, one of the main privacy issues in machine learning. These recently developed attacks have been proven successful in determining, with confidence better than a random guess, whether a given sample belongs to the dataset on which the attacked machine learning model was trained. Several approaches have been developed to mitigate this privacy leakage but the tradeoff performance implications of these defensive mechanisms (i.e., accuracy and utility of the defended machine learning model) are not well studied yet. We propose a novel approach of privacy leakage avoidance with switching ensembles (PASE), which both protects against current membership inference attacks and does that with very small accuracy penalty, while requiring acceptable increase in training and inference time. We test our PASE method, along with the the current state-of-the-art PATE approach, on three calibration image datasets and analyze their tradeoffs.
Membership Model Inversion Attacks for Deep Networks
Oct 09, 2019

With the increasing adoption of AI, inherent security and privacy vulnerabilities formachine learning systems are being discovered. One such vulnerability makes itpossible for an adversary to obtain private information about the types of instancesused to train the targeted machine learning model. This so-called model inversionattack is based on sequential leveraging of classification scores towards obtaininghigh confidence representations for various classes. However, for deep networks,such procedures usually lead to unrecognizable representations that are uselessfor the adversary. In this paper, we introduce a more realistic definition of modelinversion, where the adversary is aware of the general purpose of the attackedmodel (for instance, whether it is an OCR system or a facial recognition system),and the goal is to find realistic class representations within the corresponding lower-dimensional manifold (of, respectively, general symbols or general faces). To thatend, we leverage properties of generative adversarial networks for constructinga connected lower-dimensional manifold, and demonstrate the efficiency of ourmodel inversion attack that is carried out within that manifold.
A Random Subspace Technique That Is Resistant to a Limited Number of Features Corrupted by an Adversary
Feb 19, 2019


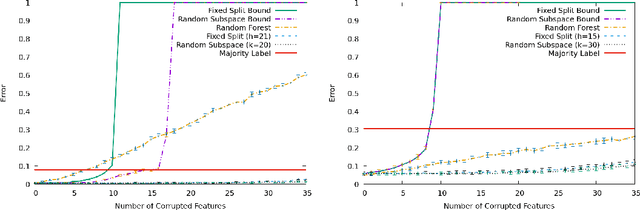
In this paper, we consider batch supervised learning where an adversary is allowed to corrupt instances with arbitrarily large noise. The adversary is allowed to corrupt any $l$ features in each instance and the adversary can change their values in any way. This noise is introduced on test instances and the algorithm receives no label feedback for these instances. We provide several subspace voting techniques that can be used to transform existing algorithms and prove data-dependent performance bounds in this setting. The key insight to our results is that we set our parameters so that a significant fraction of the voting hypotheses do not contain corrupt features and, for many real world problems, these uncorrupt hypotheses are sufficient to achieve high accuracy. We empirically validate our approach on several datasets including three new datasets that deal with side channel electromagnetic information.
AutoGAN: Robust Classifier Against Adversarial Attacks
Dec 08, 2018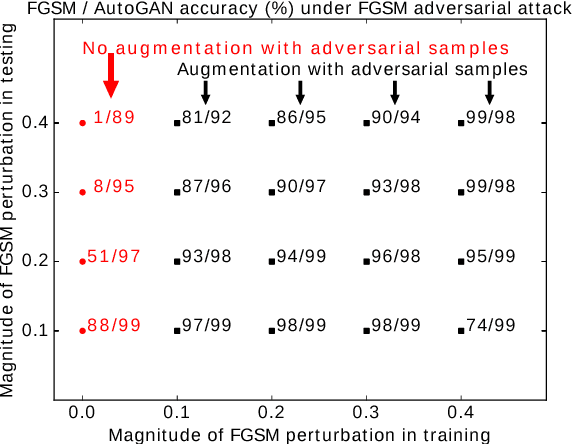
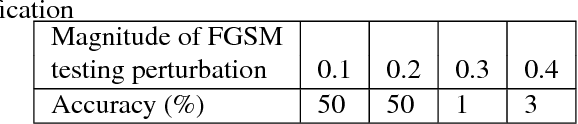

Classifiers fail to classify correctly input images that have been purposefully and imperceptibly perturbed to cause misclassification. This susceptability has been shown to be consistent across classifiers, regardless of their type, architecture or parameters. Common defenses against adversarial attacks modify the classifer boundary by training on additional adversarial examples created in various ways. In this paper, we introduce AutoGAN, which counters adversarial attacks by enhancing the lower-dimensional manifold defined by the training data and by projecting perturbed data points onto it. AutoGAN mitigates the need for knowing the attack type and magnitude as well as the need for having adversarial samples of the attack. Our approach uses a Generative Adversarial Network (GAN) with an autoencoder generator and a discriminator that also serves as a classifier. We test AutoGAN against adversarial samples generated with state-of-the-art Fast Gradient Sign Method (FGSM) as well as samples generated with random Gaussian noise, both using the MNIST dataset. For different magnitudes of perturbation in training and testing, AutoGAN can surpass the accuracy of FGSM method by up to 25\% points on samples perturbed using FGSM. Without an augmented training dataset, AutoGAN achieves an accuracy of 89\% compared to 1\% achieved by FGSM method on FGSM testing adversarial samples.
Detection under Privileged Information
Mar 31, 2018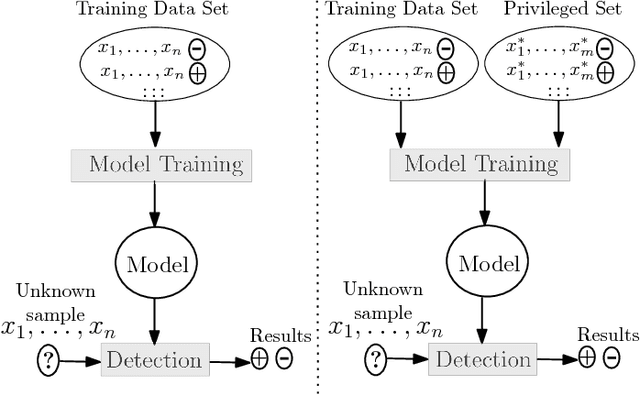

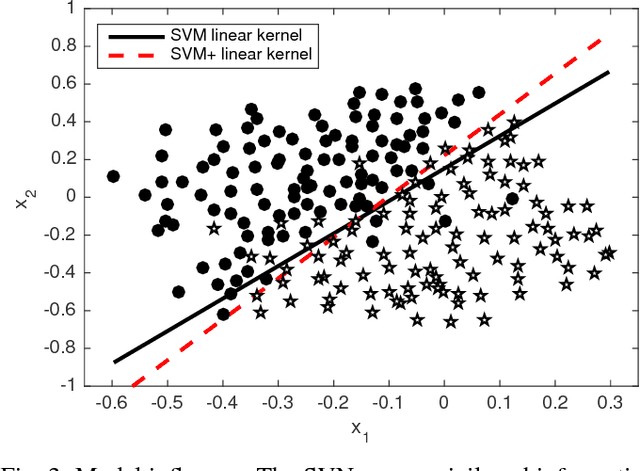
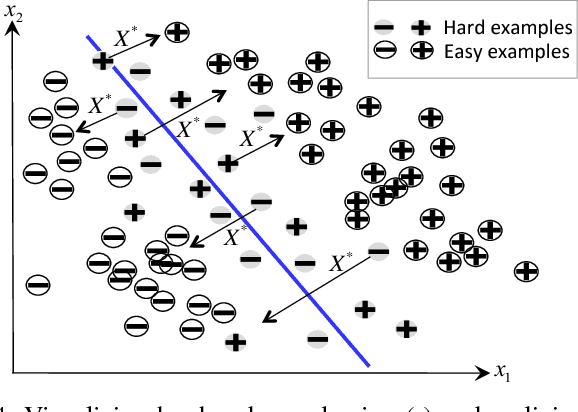
For well over a quarter century, detection systems have been driven by models learned from input features collected from real or simulated environments. An artifact (e.g., network event, potential malware sample, suspicious email) is deemed malicious or non-malicious based on its similarity to the learned model at runtime. However, the training of the models has been historically limited to only those features available at runtime. In this paper, we consider an alternate learning approach that trains models using "privileged" information--features available at training time but not at runtime--to improve the accuracy and resilience of detection systems. In particular, we adapt and extend recent advances in knowledge transfer, model influence, and distillation to enable the use of forensic or other data unavailable at runtime in a range of security domains. An empirical evaluation shows that privileged information increases precision and recall over a system with no privileged information: we observe up to 7.7% relative decrease in detection error for fast-flux bot detection, 8.6% for malware traffic detection, 7.3% for malware classification, and 16.9% for face recognition. We explore the limitations and applications of different privileged information techniques in detection systems. Such techniques provide a new means for detection systems to learn from data that would otherwise not be available at runtime.
Multi-Scale Local Shape Analysis and Feature Selection in Machine Learning Applications
Oct 13, 2014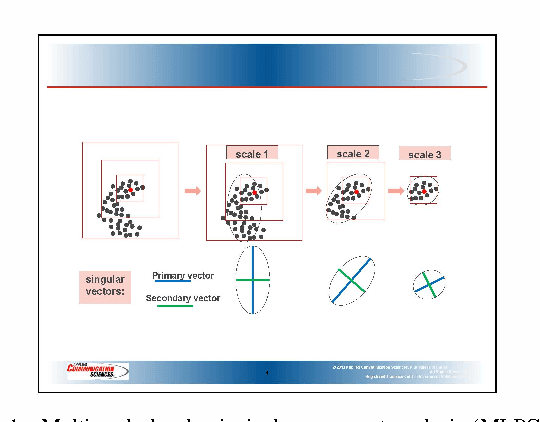
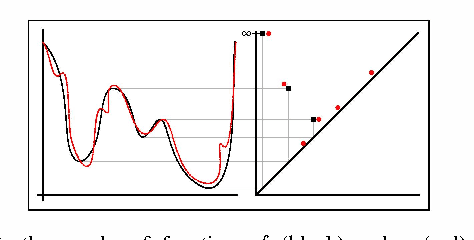
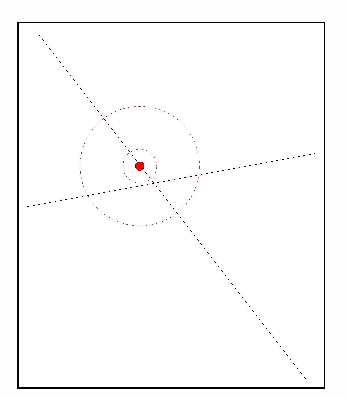
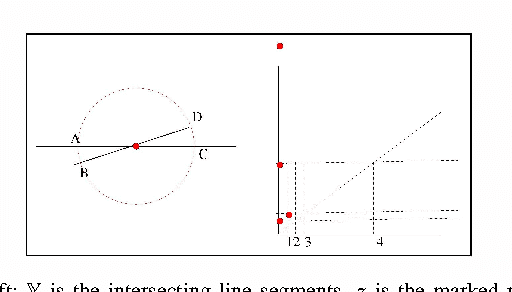
We introduce a method called multi-scale local shape analysis, or MLSA, for extracting features that describe the local structure of points within a dataset. The method uses both geometric and topological features at multiple levels of granularity to capture diverse types of local information for subsequent machine learning algorithms operating on the dataset. Using synthetic and real dataset examples, we demonstrate significant performance improvement of classification algorithms constructed for these datasets with correspondingly augmented features.
Constructive Setting of the Density Ratio Estimation Problem and its Rigorous Solution
Jun 15, 2013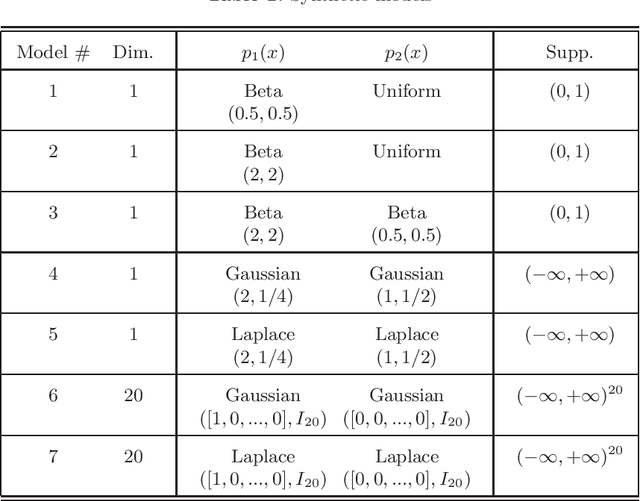
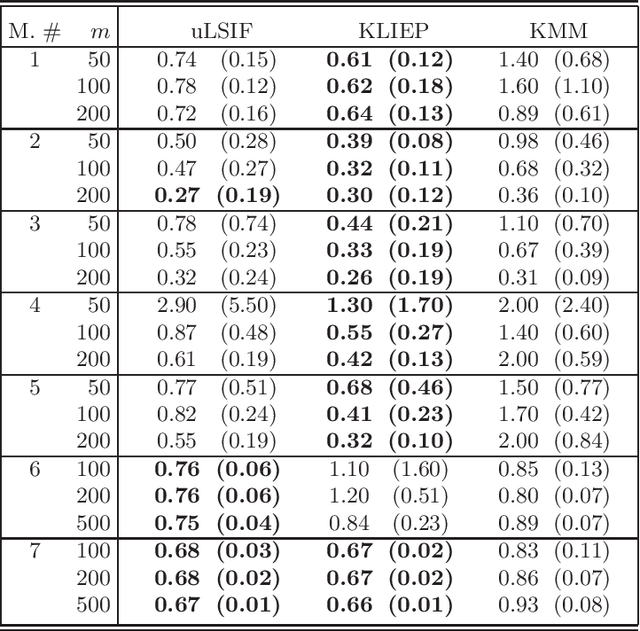

We introduce a general constructive setting of the density ratio estimation problem as a solution of a (multidimensional) integral equation. In this equation, not only its right hand side is known approximately, but also the integral operator is defined approximately. We show that this ill-posed problem has a rigorous solution and obtain the solution in a closed form. The key element of this solution is the novel V-matrix, which captures the geometry of the observed samples. We compare our method with three well-known previously proposed ones. Our experimental results demonstrate the good potential of the new approach.