 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGAN: Robust Classifier Against Adversarial Attacks
Paper and Code
Dec 08, 2018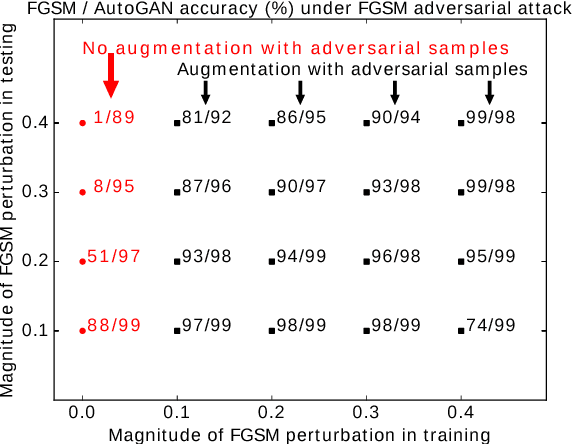
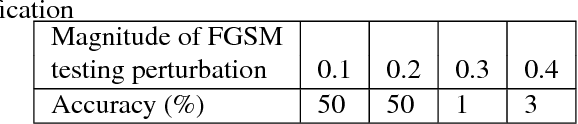
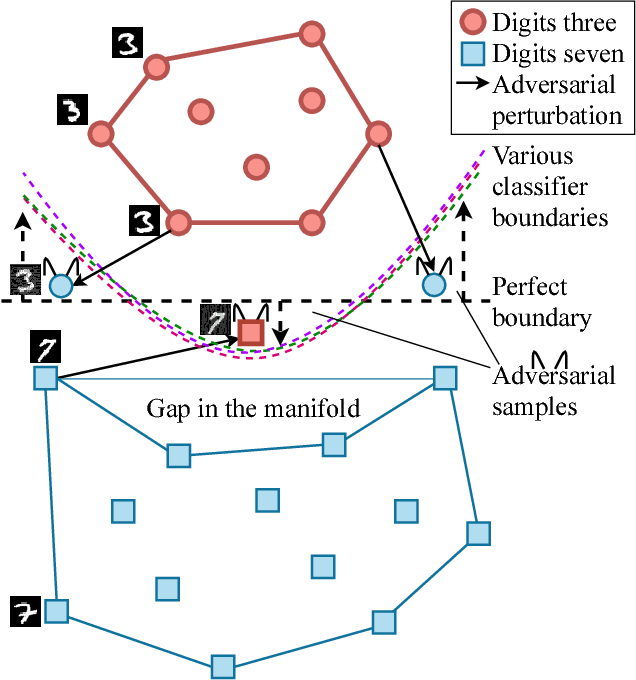

Classifiers fail to classify correctly input images that have been purposefully and imperceptibly perturbed to cause misclassification. This susceptability has been shown to be consistent across classifiers, regardless of their type, architecture or parameters. Common defenses against adversarial attacks modify the classifer boundary by training on additional adversarial examples created in various ways. In this paper, we introduce AutoGAN, which counters adversarial attacks by enhancing the lower-dimensional manifold defined by the training data and by projecting perturbed data points onto it. AutoGAN mitigates the need for knowing the attack type and magnitude as well as the need for having adversarial samples of the attack. Our approach uses a Generative Adversarial Network (GAN) with an autoencoder generator and a discriminator that also serves as a classifier. We test AutoGAN against adversarial samples generated with state-of-the-art Fast Gradient Sign Method (FGSM) as well as samples generated with random Gaussian noise, both using the MNIST dataset. For different magnitudes of perturbation in training and testing, AutoGAN can surpass the accuracy of FGSM method by up to 25\% points on samples perturbed using FGSM. Without an augmented training dataset, AutoGAN achieves an accuracy of 89\% compared to 1\% achieved by FGSM method on FGSM testing adversarial samples.