 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry Defense Against XGBoost Adversarial Perturbation Attacks
Aug 10, 2023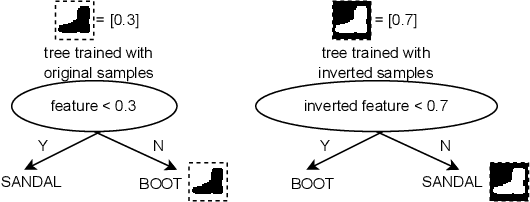
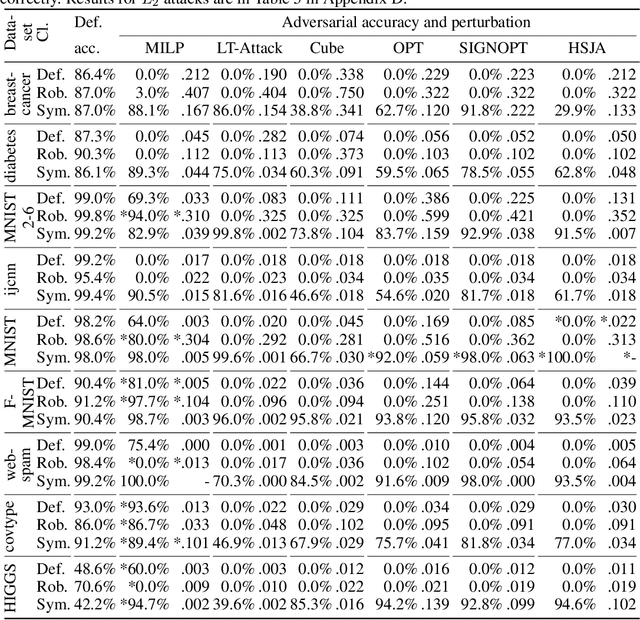
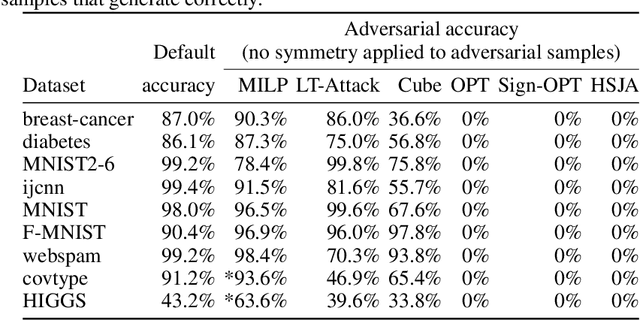
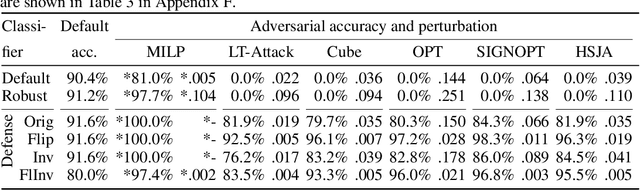
We examine whether symmetry can be used to defend tree-based ensemble classifiers such as gradient-boosting decision trees (GBDTs) against adversarial perturbation attacks. The idea is based on a recent symmetry defense for convolutional neural network classifiers (CNNs) that utilizes CNNs' lack of invariance with respect to symmetries. CNNs lack invariance because they can classify a symmetric sample, such as a horizontally flipped image, differently from the original sample. CNNs' lack of invariance also means that CNNs can classify symmetric adversarial samples differently from the incorrect classification of adversarial samples. Using CNNs' lack of invariance, the recent CNN symmetry defense has shown that the classification of symmetric adversarial samples reverts to the correct sample classification. In order to apply the same symmetry defense to GBDTs, we examine GBDT invariance and are the first to show that GBDTs also lack invariance with respect to symmetries. We apply and evaluate the GBDT symmetry defense for nine datasets against six perturbation attacks with a threat model that ranges from zero-knowledge to perfect-knowledge adversaries. Using the feature inversion symmetry against zero-knowledge adversaries, we achieve up to 100% accuracy on adversarial samples even when default and robust classifiers have 0% accuracy. Using the feature inversion and horizontal flip symmetries against perfect-knowledge adversaries, we achieve up to over 95% accuracy on adversarial samples for the GBDT classifier of the F-MNIST dataset even when default and robust classifiers have 0% accuracy.
Symmetry Subgroup Defense Against Adversarial Attacks
Oct 08, 2022

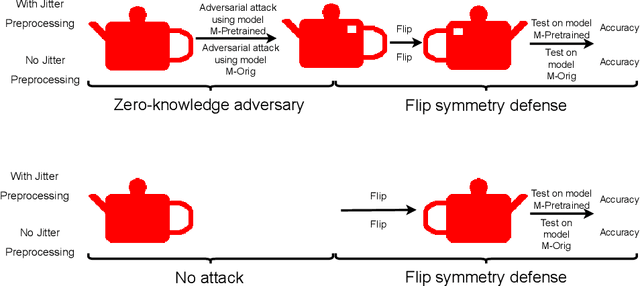
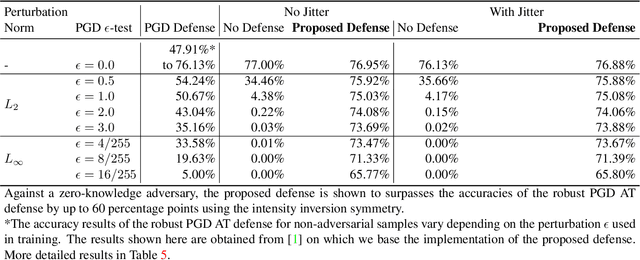
Adversarial attacks and defenses disregard the lack of invariance of convolutional neural networks (CNNs), that is, the inability of CNNs to classify samples and their symmetric transformations the same. The lack of invariance of CNNs with respect to symmetry transformations is detrimental when classifying transformed original samples but not necessarily detrimental when classifying transformed adversarial samples. For original images, the lack of invariance means that symmetrically transformed original samples are classified differently from their correct labels. However, for adversarial images, the lack of invariance means that symmetrically transformed adversarial images are classified differently from their incorrect adversarial labels. Might the CNN lack of invariance revert symmetrically transformed adversarial samples to the correct classification? This paper answers this question affirmatively for a threat model that ranges from zero-knowledge adversaries to perfect-knowledge adversaries. We base our defense against perfect-knowledge adversaries on devising a Klein four symmetry subgroup that incorporates an additional artificial symmetry of pixel intensity inversion. The closure property of the subgroup not only provides a framework for the accuracy evaluation but also confines the transformations that an adaptive, perfect-knowledge adversary can apply. We find that by using only symmetry defense, no adversarial samples, and by changing nothing in the model architecture and parameters, we can defend against white-box PGD adversarial attacks, surpassing the PGD adversarial training defense by up to ~50% even against a perfect-knowledge adversary for ImageNet. The proposed defense also maintains and surpasses the classification accuracy for non-adversarial samples.
Delving into the pixels of adversarial samples
Jun 21, 2021

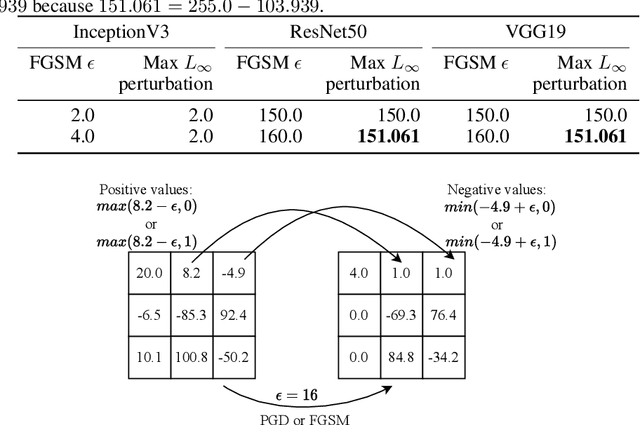

Despite extensive research into adversarial attacks, we do not know how adversarial attacks affect image pixels. Knowing how image pixels are affected by adversarial attacks has the potential to lead us to better adversarial defenses. Motivated by instances that we find where strong attacks do not transfer, we delve into adversarial examples at pixel level to scrutinize how adversarial attacks affect image pixel values. We consider several ImageNet architectures, InceptionV3, VGG19 and ResNet50, as well as several strong attacks. We find that attacks can have different effects at pixel level depending on classifier architecture. In particular, input pre-processing plays a previously overlooked role in the effect that attacks have on pixels. Based on the insights of pixel-level examination, we find new ways to detect some of the strongest current attacks.
Target Training Does Adversarial Training Without Adversarial Samples
Feb 09, 2021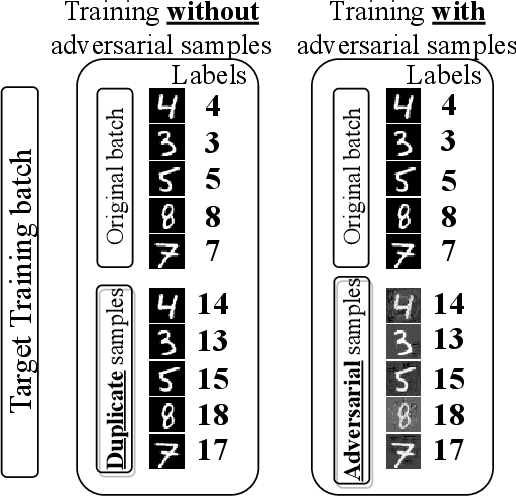
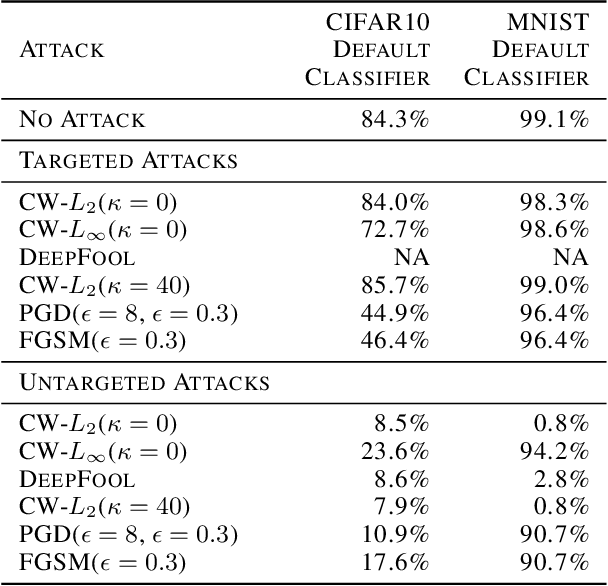

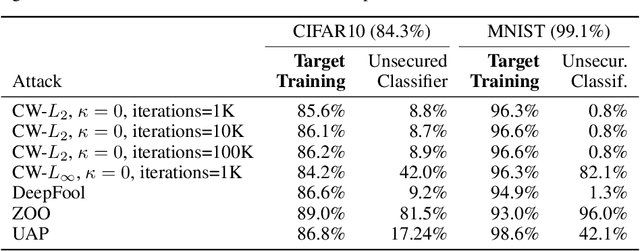
Neural network classifiers are vulnerable to misclassification of adversarial samples, for which the current best defense trains classifiers with adversarial samples. However, adversarial samples are not optimal for steering attack convergence, based on the minimization at the core of adversarial attacks. The minimization perturbation term can be minimized towards $0$ by replacing adversarial samples in training with duplicated original samples, labeled differently only for training. Using only original samples, Target Training eliminates the need to generate adversarial samples for training against all attacks that minimize perturbation. In low-capacity classifiers and without using adversarial samples, Target Training exceeds both default CIFAR10 accuracy ($84.3$%) and current best defense accuracy (below $25$%) with $84.8$% against CW-L$_2$($\kappa=0$) attack, and $86.6$% against DeepFool. Using adversarial samples against attacks that do not minimize perturbation, Target Training exceeds current best defense ($69.1$%) with $76.4$% against CW-L$_2$($\kappa=40$) in CIFAR10.
Tricking Adversarial Attacks To Fail
Jun 08, 2020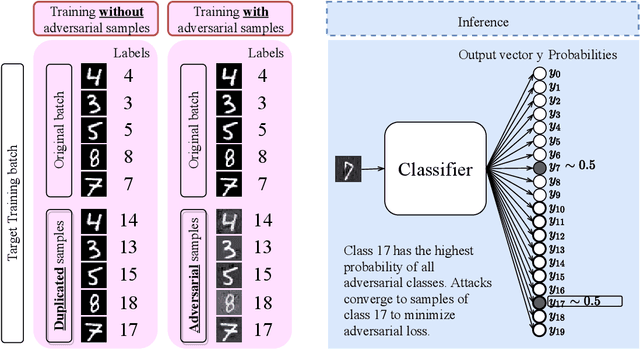


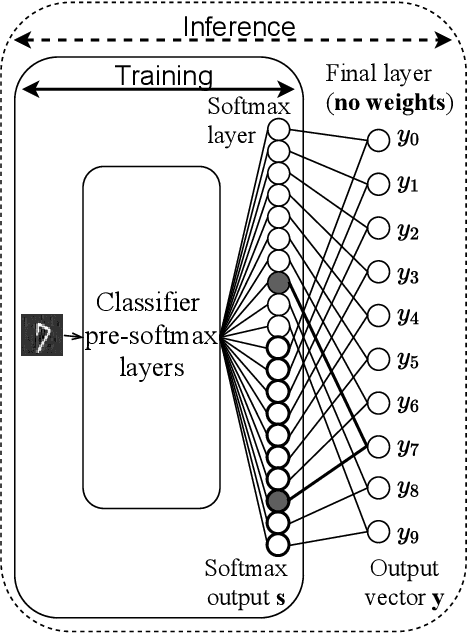
Recent adversarial defense approaches have failed. Untargeted gradient-based attacks cause classifiers to choose any wrong class. Our novel white-box defense tricks untargeted attacks into becoming attacks targeted at designated target classes. From these target classes, we can derive the real classes. Our Target Training defense tricks the minimization at the core of untargeted, gradient-based adversarial attacks: minimize the sum of (1) perturbation and (2) classifier adversarial loss. Target Training changes the classifier minimally, and trains it with additional duplicated points (at 0 distance) labeled with designated classes. These differently-labeled duplicated samples minimize both terms (1) and (2) of the minimization, steering attack convergence to samples of designated classes, from which correct classification is derived. Importantly, Target Training eliminates the need to know the attack and the overhead of generating adversarial samples of attacks that minimize perturbations. We obtain an 86.2% accuracy for CW-L2 (confidence=0) in CIFAR10, exceeding even unsecured classifier accuracy on non-adversarial samples. Target Training presents a fundamental change in adversarial defense strategy.
Minimax Defense against Gradient-based Adversarial Attacks
Feb 04, 2020
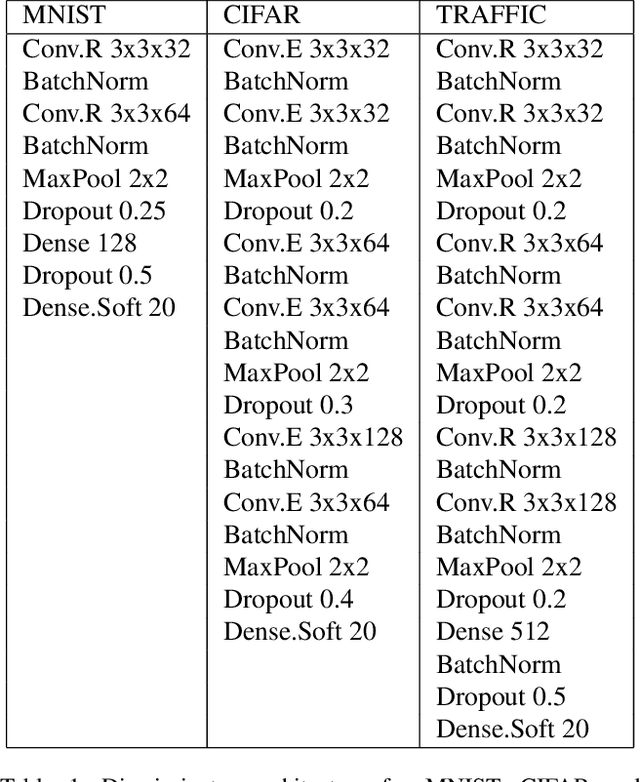


State-of-the-art adversarial attacks are aimed at neural network classifiers. By default, neural networks use gradient descent to minimize their loss function. The gradient of a classifier's loss function is used by gradient-based adversarial attacks to generate adversarially perturbed images. We pose the question whether another type of optimization could give neural network classifiers an edge. Here, we introduce a novel approach that uses minimax optimization to foil gradient-based adversarial attacks. Our minimax classifier is the discriminator of a generative adversarial network (GAN) that plays a minimax game with the GAN generator. In addition, our GAN generator projects all points onto a manifold that is different from the original manifold since the original manifold might be the cause of adversarial attacks. To measure the performance of our minimax defense, we use adversarial attacks - Carlini Wagner (CW), DeepFool, Fast Gradient Sign Method (FGSM) - on three datasets: MNIST, CIFAR-10 and German Traffic Sign (TRAFFIC). Against CW attacks, our minimax defense achieves 98.07% (MNIST-default 98.93%), 73.90% (CIFAR-10-default 83.14%) and 94.54% (TRAFFIC-default 96.97%). Against DeepFool attacks, our minimax defense achieves 98.87% (MNIST), 76.61% (CIFAR-10) and 94.57% (TRAFFIC). Against FGSM attacks, we achieve 97.01% (MNIST), 76.79% (CIFAR-10) and 81.41% (TRAFFIC). Our Minimax adversarial approach presents a significant shift in defense strategy for neural network classifiers.
AutoGAN: Robust Classifier Against Adversarial Attacks
Dec 08, 2018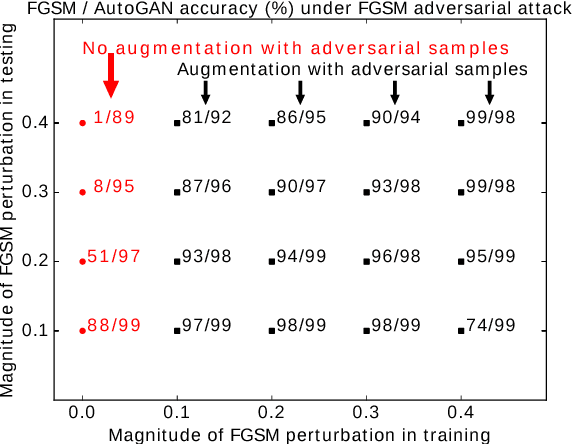
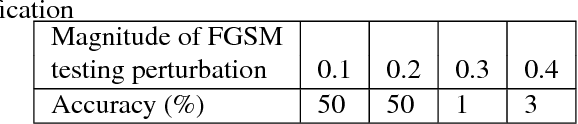
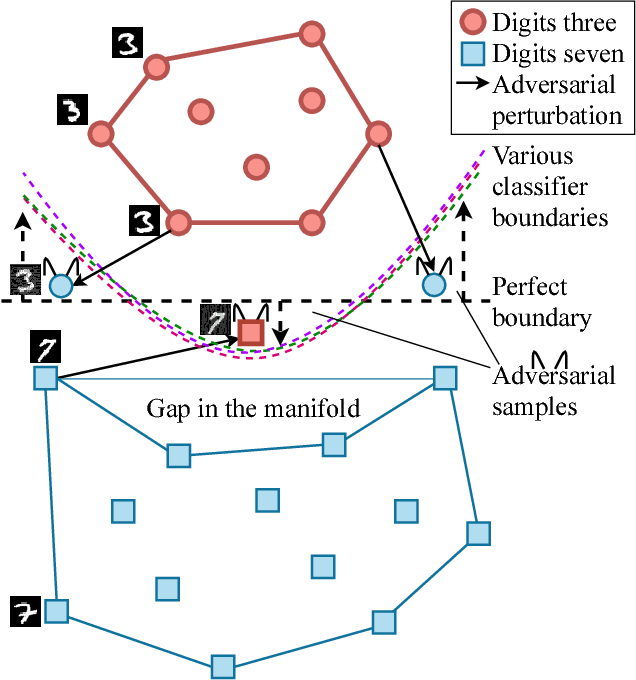

Classifiers fail to classify correctly input images that have been purposefully and imperceptibly perturbed to cause misclassification. This susceptability has been shown to be consistent across classifiers, regardless of their type, architecture or parameters. Common defenses against adversarial attacks modify the classifer boundary by training on additional adversarial examples created in various ways. In this paper, we introduce AutoGAN, which counters adversarial attacks by enhancing the lower-dimensional manifold defined by the training data and by projecting perturbed data points onto it. AutoGAN mitigates the need for knowing the attack type and magnitude as well as the need for having adversarial samples of the attack. Our approach uses a Generative Adversarial Network (GAN) with an autoencoder generator and a discriminator that also serves as a classifier. We test AutoGAN against adversarial samples generated with state-of-the-art Fast Gradient Sign Method (FGSM) as well as samples generated with random Gaussian noise, both using the MNIST dataset. For different magnitudes of perturbation in training and testing, AutoGAN can surpass the accuracy of FGSM method by up to 25\% points on samples perturbed using FGSM. Without an augmented training dataset, AutoGAN achieves an accuracy of 89\% compared to 1\% achieved by FGSM method on FGSM testing adversarial samples.