 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTGuard: Attention-aware Detection against Adversarial Examples for Vision Transformer
Sep 20, 2024The use of transformers for vision tasks has challenged the traditional dominant role of convolutional neural networks (CNN) in computer vision (CV). For image classification tasks, Vision Transformer (ViT) effectively establishes spatial relationships between patches within images, directing attention to important areas for accurate predictions. However, similar to CNNs, ViTs are vulnerable to adversarial attacks, which mislead the image classifier into making incorrect decisions on images with carefully designed perturbations. Moreover, adversarial patch attacks, which introduce arbitrary perturbations within a small area, pose a more serious threat to ViTs. Even worse, traditional detection methods, originally designed for CNN models, are impractical or suffer significant performance degradation when applied to ViTs, and they generally overlook patch attacks. In this paper, we propose ViTGuard as a general detection method for defending ViT models against adversarial attacks, including typical attacks where perturbations spread over the entire input and patch attacks. ViTGuard uses a Masked Autoencoder (MAE) model to recover randomly masked patches from the unmasked regions, providing a flexible image reconstruction strategy. Then, threshold-based detectors leverage distinctive ViT features, including attention maps and classification (CLS) token representations, to distinguish between normal and adversarial samples. The MAE model does not involve any adversarial samples during training, ensuring the effectiveness of our detectors against unseen attacks. ViTGuard is compared with seven existing detection methods under nine attacks across three datasets. The evaluation results show the superiority of ViTGuard over existing detectors. Finally, considering the potential detection evasion, we further demonstrate ViTGuard's robustness against adaptive attacks for evasion.
Partner in Crime: Boosting Targeted Poisoning Attacks against Federated Learning
Jul 13, 2024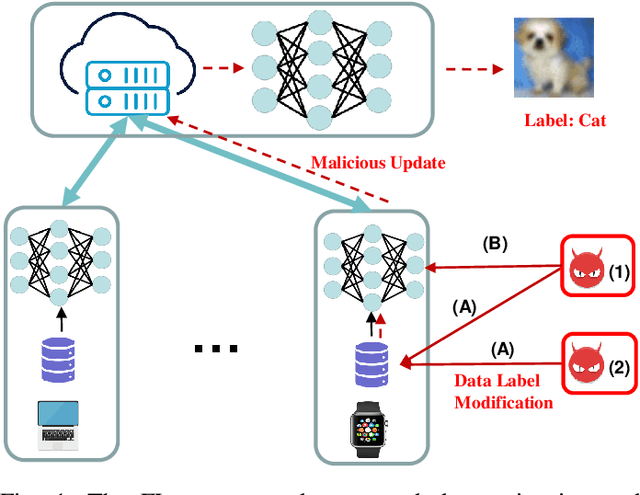
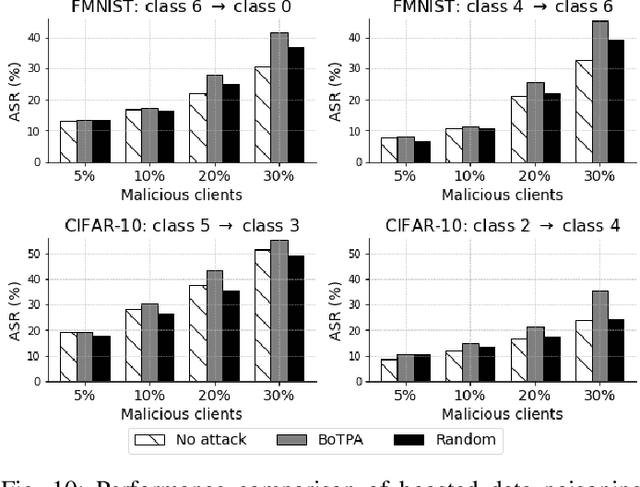
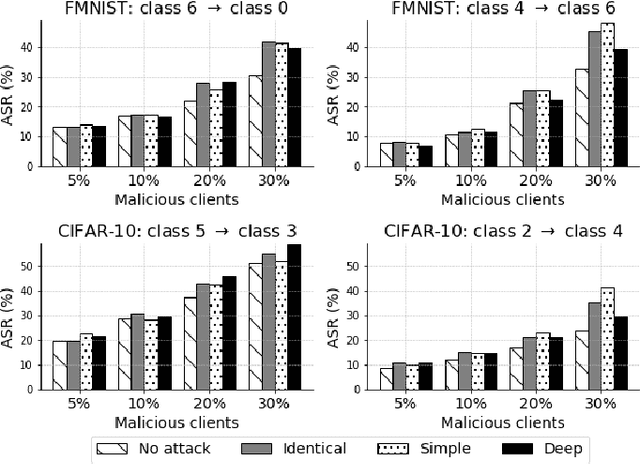
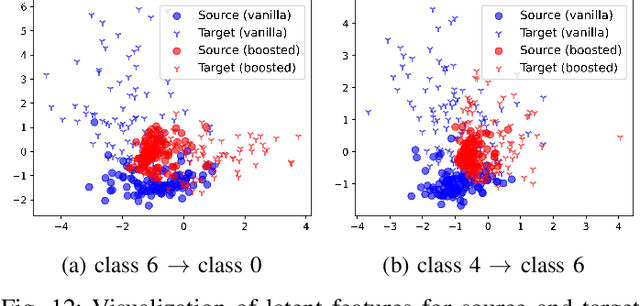
Federated Learning (FL) exposes vulnerabilities to targeted poisoning attacks that aim to cause misclassification specifically from the source class to the target class. However, using well-established defense frameworks, the poisoning impact of these attacks can be greatly mitigated. We introduce a generalized pre-training stage approach to Boost Targeted Poisoning Attacks against FL, called BoTPA. Its design rationale is to leverage the model update contributions of all data points, including ones outside of the source and target classes, to construct an Amplifier set, in which we falsify the data labels before the FL training process, as a means to boost attacks. We comprehensively evaluate the effectiveness and compatibility of BoTPA on various targeted poisoning attacks. Under data poisoning attacks, our evaluations reveal that BoTPA can achieve a median Relative Increase in Attack Success Rate (RI-ASR) between 15.3% and 36.9% across all possible source-target class combinations, with varying percentages of malicious clients, compared to its baseline. In the context of model poisoning, BoTPA attains RI-ASRs ranging from 13.3% to 94.7% in the presence of the Krum and Multi-Krum defenses, from 2.6% to 49.2% under the Median defense, and from 2.9% to 63.5% under the Flame defense.
AutoGAN: Robust Classifier Against Adversarial Attacks
Dec 08, 2018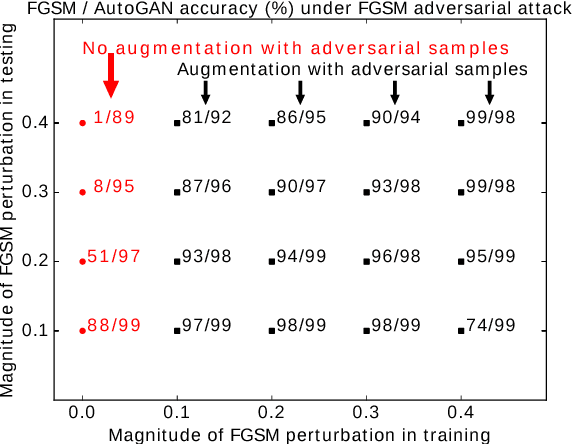
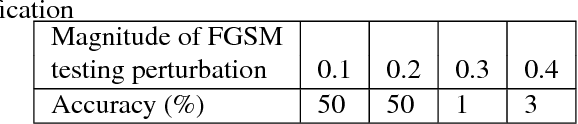
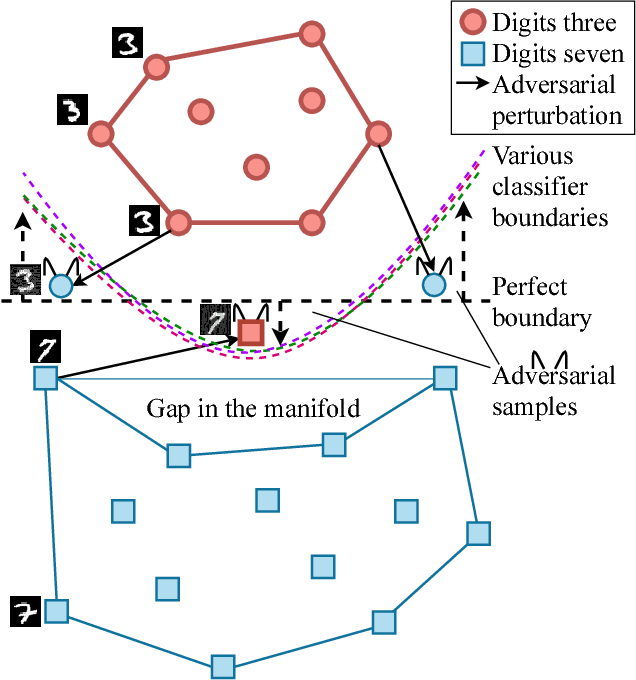

Classifiers fail to classify correctly input images that have been purposefully and imperceptibly perturbed to cause misclassification. This susceptability has been shown to be consistent across classifiers, regardless of their type, architecture or parameters. Common defenses against adversarial attacks modify the classifer boundary by training on additional adversarial examples created in various ways. In this paper, we introduce AutoGAN, which counters adversarial attacks by enhancing the lower-dimensional manifold defined by the training data and by projecting perturbed data points onto it. AutoGAN mitigates the need for knowing the attack type and magnitude as well as the need for having adversarial samples of the attack. Our approach uses a Generative Adversarial Network (GAN) with an autoencoder generator and a discriminator that also serves as a classifier. We test AutoGAN against adversarial samples generated with state-of-the-art Fast Gradient Sign Method (FGSM) as well as samples generated with random Gaussian noise, both using the MNIST dataset. For different magnitudes of perturbation in training and testing, AutoGAN can surpass the accuracy of FGSM method by up to 25\% points on samples perturbed using FGSM. Without an augmented training dataset, AutoGAN achieves an accuracy of 89\% compared to 1\% achieved by FGSM method on FGSM testing adversarial samples.