 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Geometric Summaries for Similarity-based Sensor Fusion
Oct 13, 2018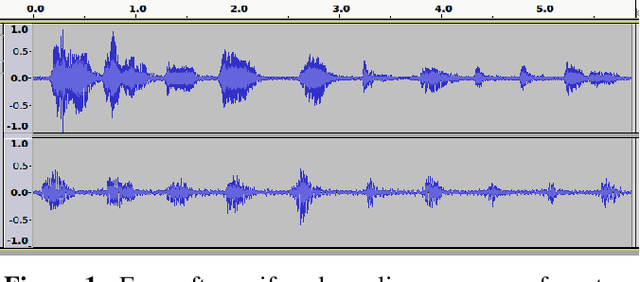

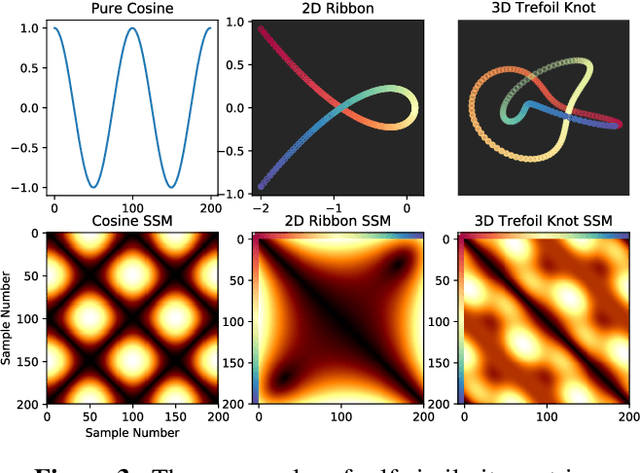
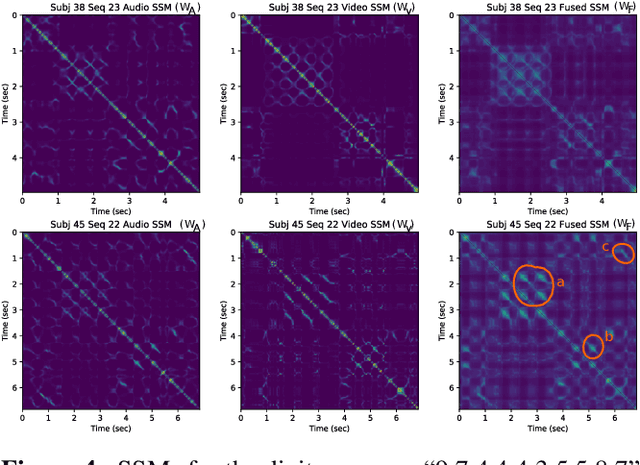
In this work, we address fusion of heterogeneous sensor data using wavelet-based summaries of fused self-similarity information from each sensor. The technique we develop is quite general, does not require domain specific knowledge or physical models, and requires no training. Nonetheless, it can perform surprisingly well at the general task of differentiating classes of time-ordered behavior sequences which are sensed by more than one modality. As a demonstration of our capabilities in the audio to video context, we focus on the differentiation of speech sequences. Data from two or more modalities first are represented using self-similarity matrices(SSMs) corresponding to time-ordered point clouds in feature spaces of each of these data sources; we note that these feature spaces can be of entirely different scale and dimensionality. A fused similarity template is then derived from the modality-specific SSMs using a technique called similarity network fusion (SNF). We investigate pipelines using SNF as both an upstream (feature-level) and a downstream (ranking-level) fusion technique. Multiscale geometric features of this template are then extracted using a recently-developed technique called the scattering transform, and these features are then used to differentiate speech sequences. This method outperforms unsupervised techniques which operate directly on the raw data, and it also outperforms stovepiped methods which operate on SSMs separately derived from the distinct modalities. The benefits of this method become even more apparent as the simulated peak signal to noise ratio decreases.
Supervised Learning of Labeled Pointcloud Differences via Cover-Tree Entropy Reduction
Jan 19, 2018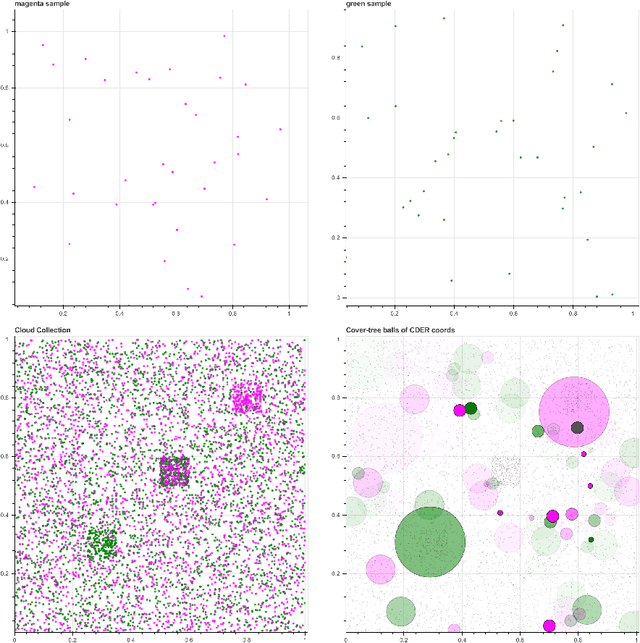
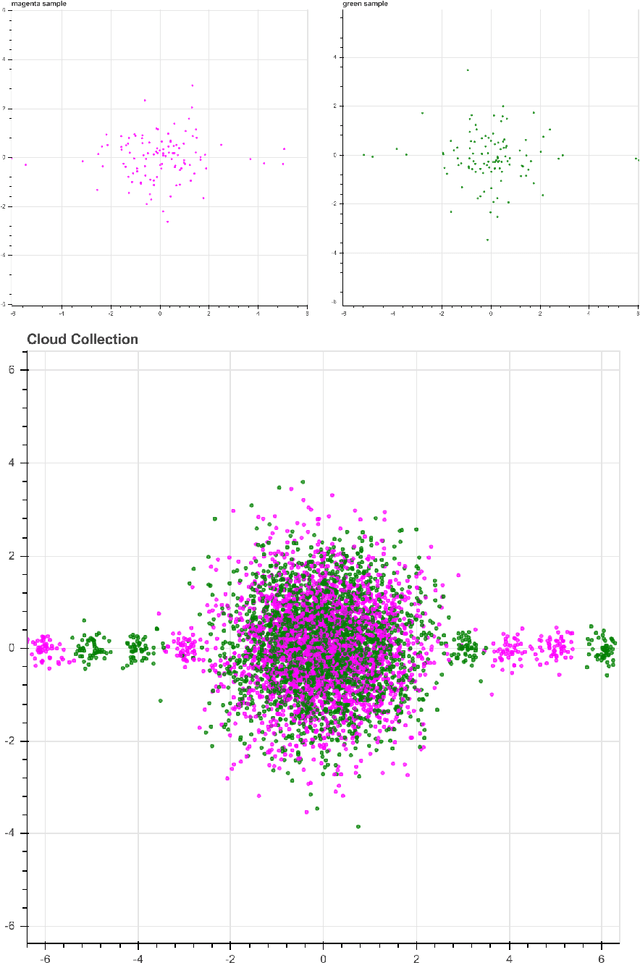
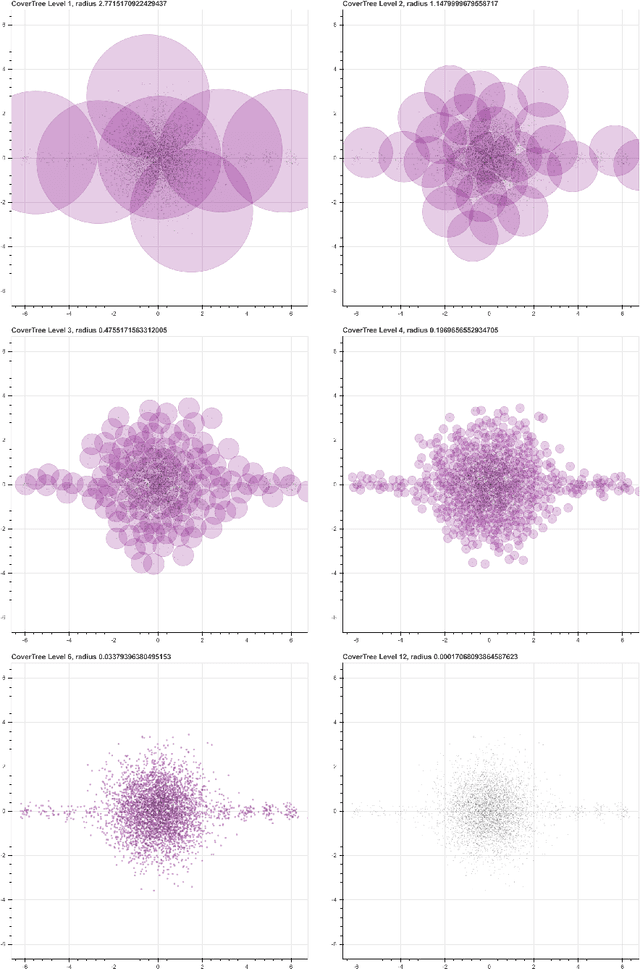
We introduce a new algorithm, called CDER, for supervised machine learning that merges the multi-scale geometric properties of Cover Trees with the information-theoretic properties of entropy. CDER applies to a training set of labeled pointclouds embedded in a common Euclidean space. If typical pointclouds corresponding to distinct labels tend to differ at any scale in any sub-region, CDER can identify these differences in (typically) linear time, creating a set of distributional coordinates which act as a feature extraction mechanism for supervised learning. We describe theoretical properties and implementation details of CDER, and illustrate its benefits on several synthetic examples.
Geometric Cross-Modal Comparison of Heterogeneous Sensor Data
Nov 23, 2017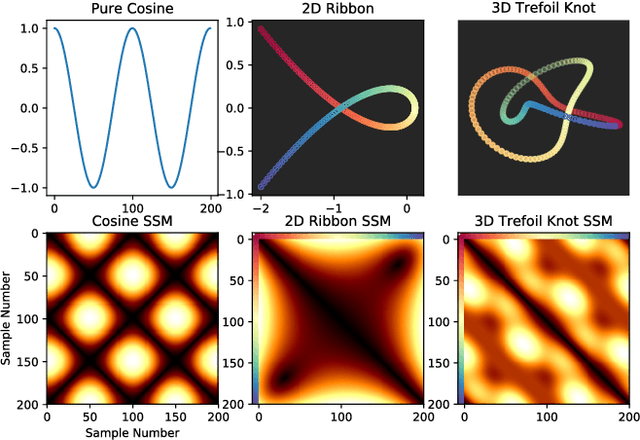
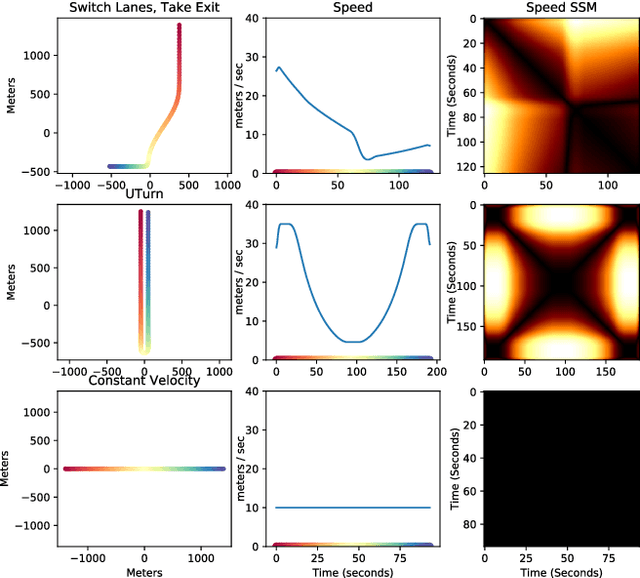
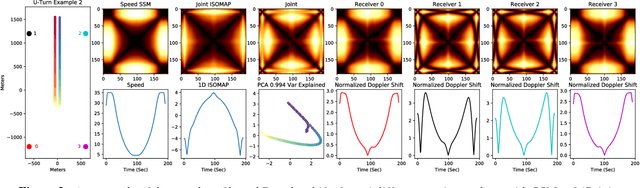
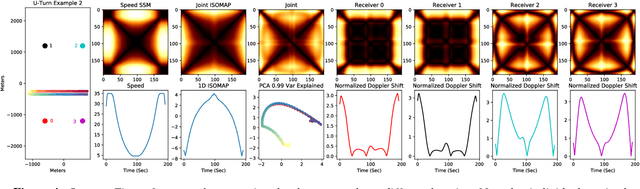
In this work, we address the problem of cross-modal comparison of aerial data streams. A variety of simulated automobile trajectories are sensed using two different modalities: full-motion video, and radio-frequency (RF) signals received by detectors at various locations. The information represented by the two modalities is compared using self-similarity matrices (SSMs) corresponding to time-ordered point clouds in feature spaces of each of these data sources; we note that these feature spaces can be of entirely different scale and dimensionality. Several metrics for comparing SSMs are explored, including a cutting-edge time-warping technique that can simultaneously handle local time warping and partial matches, while also controlling for the change in geometry between feature spaces of the two modalities. We note that this technique is quite general, and does not depend on the choice of modalities. In this particular setting, we demonstrate that the cross-modal distance between SSMs corresponding to the same trajectory type is smaller than the cross-modal distance between SSMs corresponding to distinct trajectory types, and we formalize this observation via precision-recall metrics in experiments. Finally, we comment on promising implications of these ideas for future integration into multiple-hypothesis tracking systems.
Multi-Scale Local Shape Analysis and Feature Selection in Machine Learning Applications
Oct 13, 2014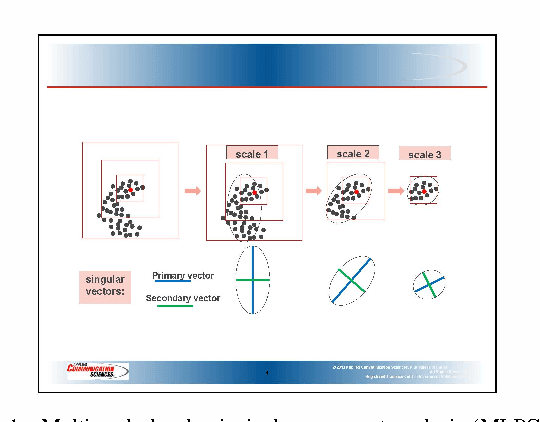
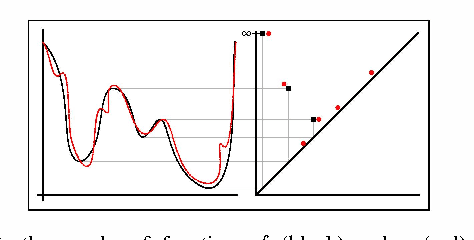
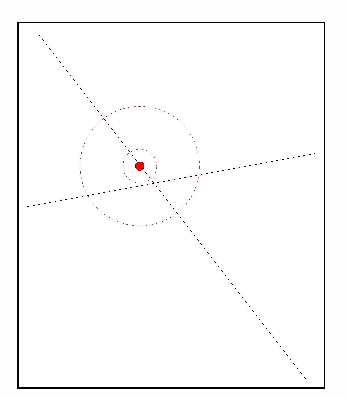
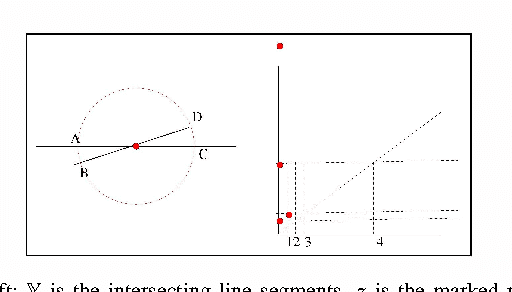
We introduce a method called multi-scale local shape analysis, or MLSA, for extracting features that describe the local structure of points within a dataset. The method uses both geometric and topological features at multiple levels of granularity to capture diverse types of local information for subsequent machine learning algorithms operating on the dataset. Using synthetic and real dataset examples, we demonstrate significant performance improvement of classification algorithms constructed for these datasets with correspondingly augmented features.
Topological and Statistical Behavior Classifiers for Tracking Applications
Jun 01, 2014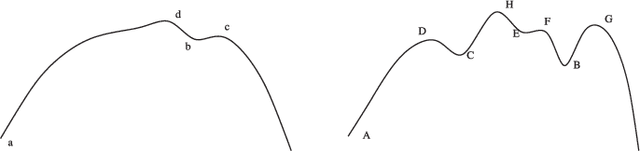
We introduce the first unified theory for target tracking using Multiple Hypothesis Tracking, Topological Data Analysis, and machine learning. Our string of innovations are 1) robust topological features are used to encode behavioral information, 2) statistical models are fitted to distributions over these topological features, and 3) the target type classification methods of Wigren and Bar Shalom et al. are employed to exploit the resulting likelihoods for topological features inside of the tracking procedure. To demonstrate the efficacy of our approach, we test our procedure on synthetic vehicular data generated by the Simulation of Urban Mobility package.