 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Geometric Summaries for Similarity-based Sensor Fusion
Paper and Code
Oct 13, 2018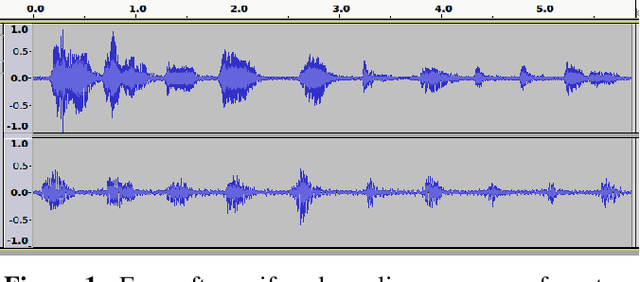

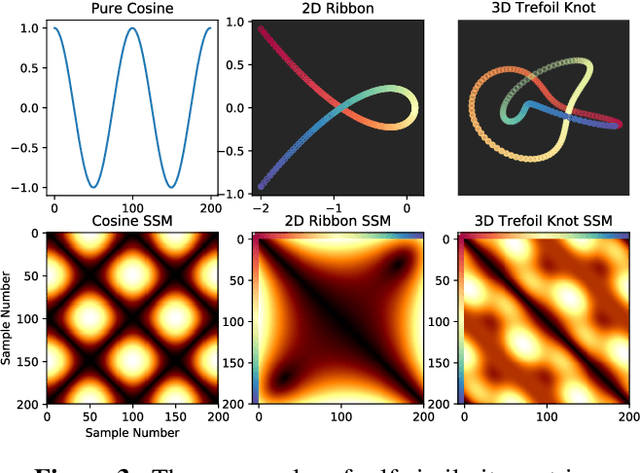
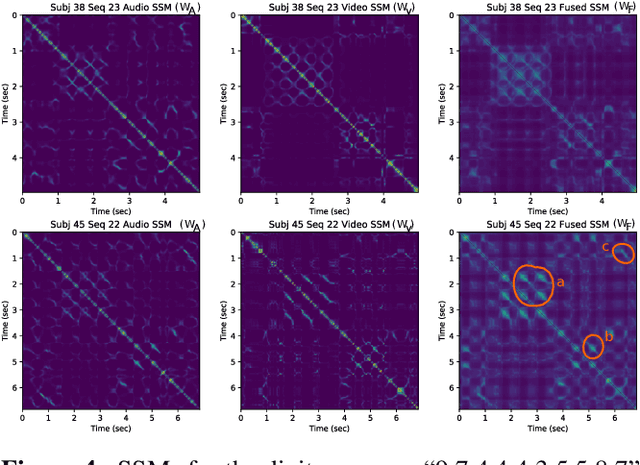
In this work, we address fusion of heterogeneous sensor data using wavelet-based summaries of fused self-similarity information from each sensor. The technique we develop is quite general, does not require domain specific knowledge or physical models, and requires no training. Nonetheless, it can perform surprisingly well at the general task of differentiating classes of time-ordered behavior sequences which are sensed by more than one modality. As a demonstration of our capabilities in the audio to video context, we focus on the differentiation of speech sequences. Data from two or more modalities first are represented using self-similarity matrices(SSMs) corresponding to time-ordered point clouds in feature spaces of each of these data sources; we note that these feature spaces can be of entirely different scale and dimensionality. A fused similarity template is then derived from the modality-specific SSMs using a technique called similarity network fusion (SNF). We investigate pipelines using SNF as both an upstream (feature-level) and a downstream (ranking-level) fusion technique. Multiscale geometric features of this template are then extracted using a recently-developed technique called the scattering transform, and these features are then used to differentiate speech sequences. This method outperforms unsupervised techniques which operate directly on the raw data, and it also outperforms stovepiped methods which operate on SSMs separately derived from the distinct modalities. The benefits of this method become even more apparent as the simulated peak signal to noise ratio decreases.