 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Echoes Survive Training in Audio To Audio Generative Instrument Models
Dec 14, 2024As generative techniques pervade the audio domain, there has been increasing interest in tracing back through these complicated models to understand how they draw on their training data to synthesize new examples, both to ensure that they use properly licensed data and also to elucidate their black box behavior. In this paper, we show that if imperceptible echoes are hidden in the training data, a wide variety of audio to audio architectures (differentiable digital signal processing (DDSP), Realtime Audio Variational autoEncoder (RAVE), and ``Dance Diffusion'') will reproduce these echoes in their outputs. Hiding a single echo is particularly robust across all architectures, but we also show promising results hiding longer time spread echo patterns for an increased information capacity. We conclude by showing that echoes make their way into fine tuned models, that they survive mixing/demixing, and that they survive pitch shift augmentation during training. Hence, this simple, classical idea in watermarking shows significant promise for tagging generative audio models.
Artistic Curve Steganography Carried by Musical Audio
Jan 29, 2023


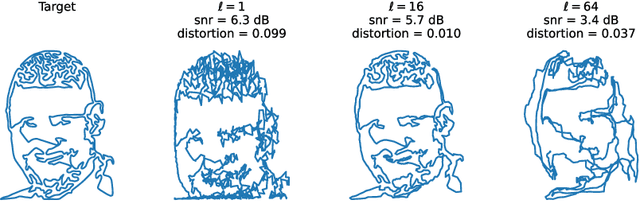
In this work, we create artistic closed loop curves that trace out images and 3D shapes, which we then hide in musical audio as a form of steganography. We use traveling salesperson art to create artistic plane loops to trace out image contours, and we use Hamiltonian cycles on triangle meshes to create artistic space loops that fill out 3D surfaces. Our embedding scheme is designed to faithfully preserve the geometry of these loops after lossy compression, while keeping their presence undetectable to the audio listener. To accomplish this, we hide each dimension of the curve in a different frequency, and we perturb a sliding window sum of the magnitude of that frequency to best match the target curve at that dimension, while hiding scale information in that frequency's phase. In the process, we exploit geometric properties of the curves to help to more effectively hide and recover them. Our scheme is simple and encoding happens efficiently with a nonnegative least squares framework, while decoding is trivial. We validate our technique quantitatively on large datasets of images and audio, and we show results of a crowd sourced listening test that validate that the hidden information is indeed unobtrusive.
The DOPE Distance is SIC: A Stable, Informative, and Computable Metric on Time Series And Ordered Merge Trees
Dec 03, 2022



Metrics for merge trees that are simultaneously stable, informative, and efficiently computable have so far eluded researchers. We show in this work that it is possible to devise such a metric when restricting merge trees to ordered domains such as the interval and the circle. We present the ``dynamic ordered persistence editing'' (DOPE) distance, which we prove is stable and informative while satisfying metric properties. We then devise a simple $O(N^2)$ dynamic programming algorithm to compute it on the interval and an $O(N^3)$ algorithm to compute it on the circle. Surprisingly, we accomplish this by ignoring all of the hierarchical information of the merge tree and simply focusing on a sequence of ordered critical points, which can be interpreted as a time series. Thus our algorithm is more similar to string edit distance and dynamic time warping than it is to more conventional merge tree comparison algorithms. In the context of time series with the interval as a domain, we show empirically on the UCR time series classification dataset that DOPE performs better than bottleneck/Wasserstein distances between persistence diagrams.
Audio-based Musical Version Identification: Elements and Challenges
Sep 06, 2021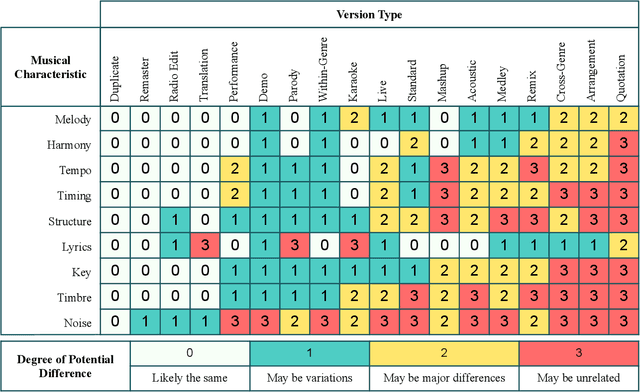
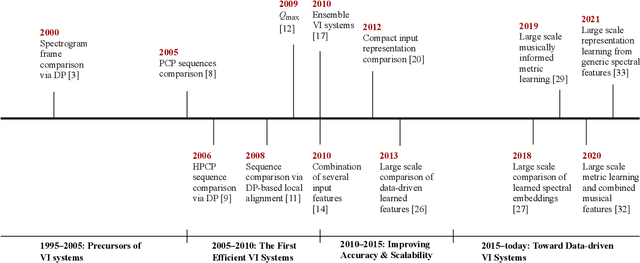
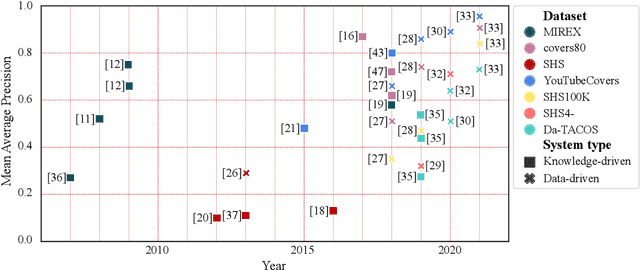
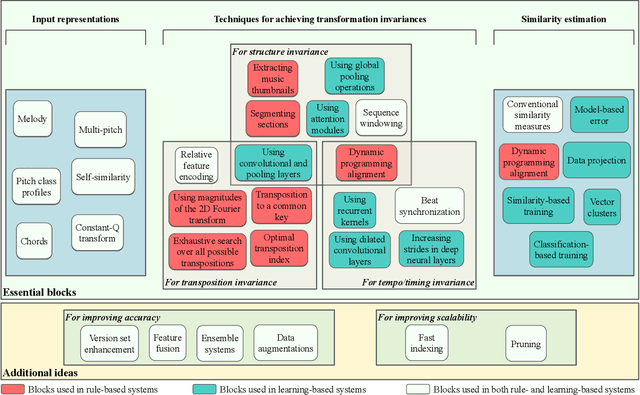
In this article, we aim to provide a review of the key ideas and approaches proposed in 20 years of scientific literature around musical version identification (VI) research and connect them to current practice. For more than a decade, VI systems suffered from the accuracy-scalability trade-off, with attempts to increase accuracy that typically resulted in cumbersome, non-scalable systems. Recent years, however, have witnessed the rise of deep learning-based approaches that take a step toward bridging the accuracy-scalability gap, yielding systems that can realistically be deployed in industrial applications. Although this trend positively influences the number of researchers and institutions working on VI, it may also result in obscuring the literature before the deep learning era. To appreciate two decades of novel ideas in VI research and to facilitate building better systems, we now review some of the successful concepts and applications proposed in the literature and study their evolution throughout the years.
Multi-scale Geometric Summaries for Similarity-based Sensor Fusion
Oct 13, 2018

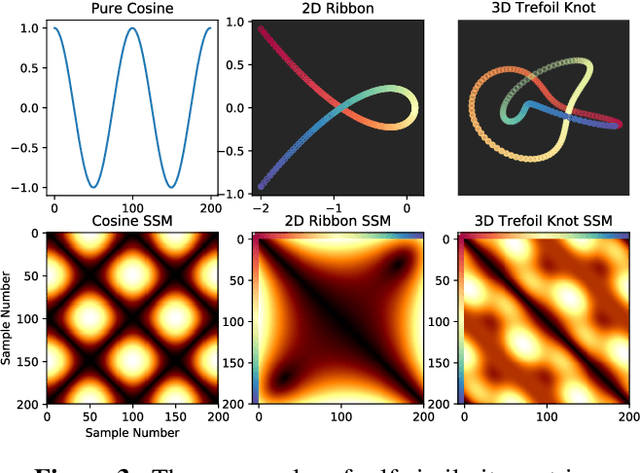
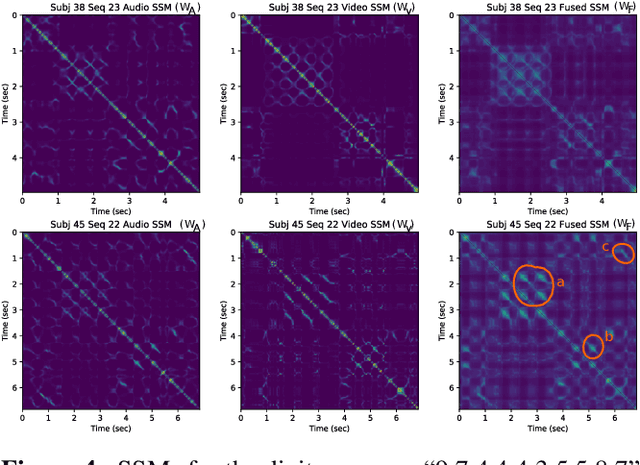
In this work, we address fusion of heterogeneous sensor data using wavelet-based summaries of fused self-similarity information from each sensor. The technique we develop is quite general, does not require domain specific knowledge or physical models, and requires no training. Nonetheless, it can perform surprisingly well at the general task of differentiating classes of time-ordered behavior sequences which are sensed by more than one modality. As a demonstration of our capabilities in the audio to video context, we focus on the differentiation of speech sequences. Data from two or more modalities first are represented using self-similarity matrices(SSMs) corresponding to time-ordered point clouds in feature spaces of each of these data sources; we note that these feature spaces can be of entirely different scale and dimensionality. A fused similarity template is then derived from the modality-specific SSMs using a technique called similarity network fusion (SNF). We investigate pipelines using SNF as both an upstream (feature-level) and a downstream (ranking-level) fusion technique. Multiscale geometric features of this template are then extracted using a recently-developed technique called the scattering transform, and these features are then used to differentiate speech sequences. This method outperforms unsupervised techniques which operate directly on the raw data, and it also outperforms stovepiped methods which operate on SSMs separately derived from the distinct modalities. The benefits of this method become even more apparent as the simulated peak signal to noise ratio decreases.
(Quasi)Periodicity Quantification in Video Data, Using Topology
Jan 21, 2018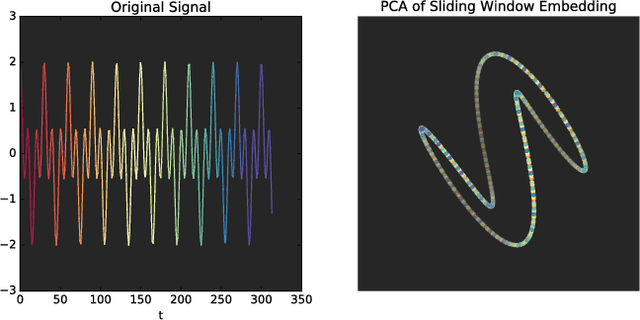
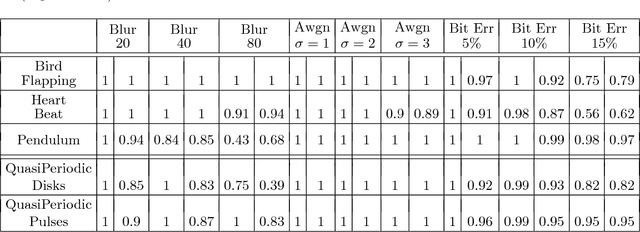

This work introduces a novel framework for quantifying the presence and strength of recurrent dynamics in video data. Specifically, we provide continuous measures of periodicity (perfect repetition) and quasiperiodicity (superposition of periodic modes with non-commensurate periods), in a way which does not require segmentation, training, object tracking or 1-dimensional surrogate signals. Our methodology operates directly on video data. The approach combines ideas from nonlinear time series analysis (delay embeddings) and computational topology (persistent homology), by translating the problem of finding recurrent dynamics in video data, into the problem of determining the circularity or toroidality of an associated geometric space. Through extensive testing, we show the robustness of our scores with respect to several noise models/levels, we show that our periodicity score is superior to other methods when compared to human-generated periodicity rankings, and furthermore, we show that our quasiperiodicity score clearly indicates the presence of biphonation in videos of vibrating vocal folds, which has never before been accomplished end to end quantitatively.
Geometric Cross-Modal Comparison of Heterogeneous Sensor Data
Nov 23, 2017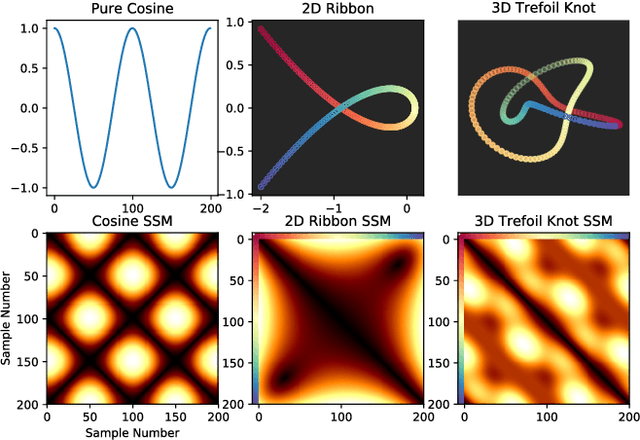
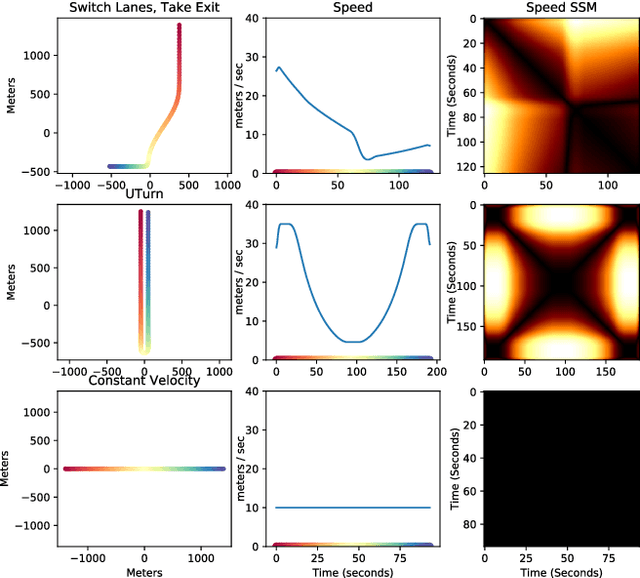
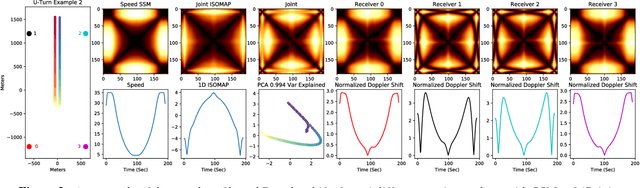
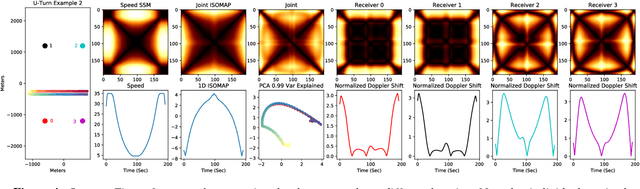
In this work, we address the problem of cross-modal comparison of aerial data streams. A variety of simulated automobile trajectories are sensed using two different modalities: full-motion video, and radio-frequency (RF) signals received by detectors at various locations. The information represented by the two modalities is compared using self-similarity matrices (SSMs) corresponding to time-ordered point clouds in feature spaces of each of these data sources; we note that these feature spaces can be of entirely different scale and dimensionality. Several metrics for comparing SSMs are explored, including a cutting-edge time-warping technique that can simultaneously handle local time warping and partial matches, while also controlling for the change in geometry between feature spaces of the two modalities. We note that this technique is quite general, and does not depend on the choice of modalities. In this particular setting, we demonstrate that the cross-modal distance between SSMs corresponding to the same trajectory type is smaller than the cross-modal distance between SSMs corresponding to distinct trajectory types, and we formalize this observation via precision-recall metrics in experiments. Finally, we comment on promising implications of these ideas for future integration into multiple-hypothesis tracking systems.
Self-Similarity Based Time Warping
Nov 20, 2017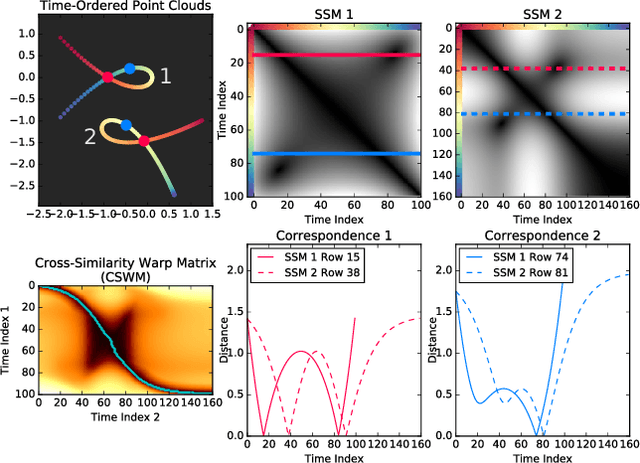


In this work, we explore the problem of aligning two time-ordered point clouds which are spatially transformed and re-parameterized versions of each other. This has a diverse array of applications such as cross modal time series synchronization (e.g. MOCAP to video) and alignment of discretized curves in images. Most other works that address this problem attempt to jointly uncover a spatial alignment and correspondences between the two point clouds, or to derive local invariants to spatial transformations such as curvature before computing correspondences. By contrast, we sidestep spatial alignment completely by using self-similarity matrices (SSMs) as a proxy to the time-ordered point clouds, since self-similarity matrices are blind to isometries and respect global geometry. Our algorithm, dubbed "Isometry Blind Dynamic Time Warping" (IBDTW), is simple and general, and we show that its associated dissimilarity measure lower bounds the L1 Gromov-Hausdorff distance between the two point sets when restricted to warping paths. We also present a local, partial alignment extension of IBDTW based on the Smith Waterman algorithm. This eliminates the need for tedious manual cropping of time series, which is ordinarily necessary for global alignment algorithms to function properly.