 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled oscillation modeling using port-Hamiltonian neural networks
Feb 17, 2026Learning dynamical systems through purely data-driven methods is challenging as they do not learn the underlying conservation laws that enable them to correctly generalize. Existing port-Hamiltonian neural network methods have recently been successfully applied for modeling mechanical systems. However, even though these methods are designed on power-balance principles, they usually do not consider power-preserving discretizations and often rely on Runge-Kutta numerical methods. In this work, we propose to use a second-order discrete gradient method embedded in the learning of dynamical systems with port-Hamiltonian neural networks. Numerical results are provided for three systems deliberately selected to span different ranges of dynamical behavior under control: a baseline harmonic oscillator with quadratic energy storage; a Duffing oscillator, with a non-quadratic Hamiltonian offering amplitude-dependent effects; and a self-sustained oscillator, which can stabilize in a controlled limit cycle through the incorporation of a nonlinear dissipation. We show how the use of this discrete gradient method outperforms the performance of a Runge-Kutta method of the same order. Experiments are also carried out to compare two theoretically equivalent port-Hamiltonian systems formulations and to analyze the impact of regularizing the Jacobian of port-Hamiltonian neural networks during training.
Combining audio control and style transfer using latent diffusion
Jul 31, 2024



Deep generative models are now able to synthesize high-quality audio signals, shifting the critical aspect in their development from audio quality to control capabilities. Although text-to-music generation is getting largely adopted by the general public, explicit control and example-based style transfer are more adequate modalities to capture the intents of artists and musicians. In this paper, we aim to unify explicit control and style transfer within a single model by separating local and global information to capture musical structure and timbre respectively. To do so, we leverage the capabilities of diffusion autoencoders to extract semantic features, in order to build two representation spaces. We enforce disentanglement between those spaces using an adversarial criterion and a two-stage training strategy. Our resulting model can generate audio matching a timbre target, while specifying structure either with explicit controls or through another audio example. We evaluate our model on one-shot timbre transfer and MIDI-to-audio tasks on instrumental recordings and show that we outperform existing baselines in terms of audio quality and target fidelity. Furthermore, we show that our method can generate cover versions of complete musical pieces by transferring rhythmic and melodic content to the style of a target audio in a different genre.
* ISMIR 2024
And what if two musical versions don't share melody, harmony, rhythm, or lyrics ?
Oct 03, 2022

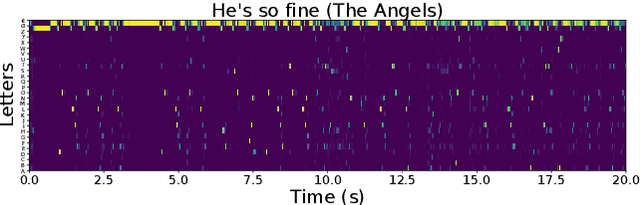

Version identification (VI) has seen substantial progress over the past few years. On the one hand, the introduction of the metric learning paradigm has favored the emergence of scalable yet accurate VI systems. On the other hand, using features focusing on specific aspects of musical pieces, such as melody, harmony, or lyrics, yielded interpretable and promising performances. In this work, we build upon these recent advances and propose a metric learning-based system systematically leveraging four dimensions commonly admitted to convey musical similarity between versions: melodic line, harmonic structure, rhythmic patterns, and lyrics. We describe our deliberately simple model architecture, and we show in particular that an approximated representation of the lyrics is an efficient proxy to discriminate between versions and non-versions. We then describe how these features complement each other and yield new state-of-the-art performances on two publicly available datasets. We finally suggest that a VI system using a combination of melodic, harmonic, rhythmic and lyrics features could theoretically reach the optimal performances obtainable on these datasets.
Audio-based Musical Version Identification: Elements and Challenges
Sep 06, 2021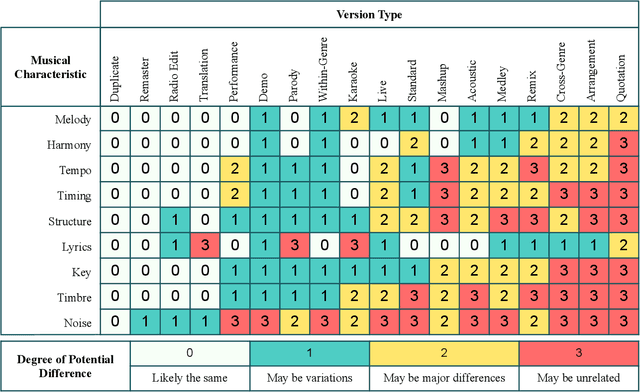
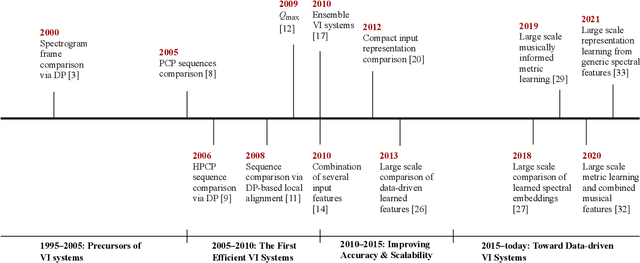
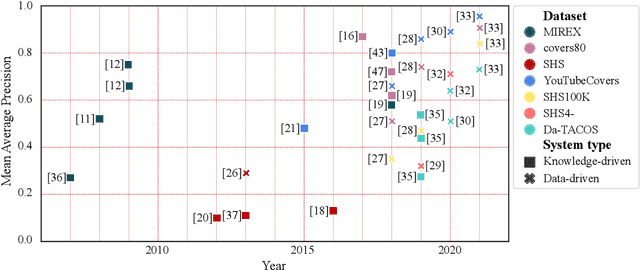
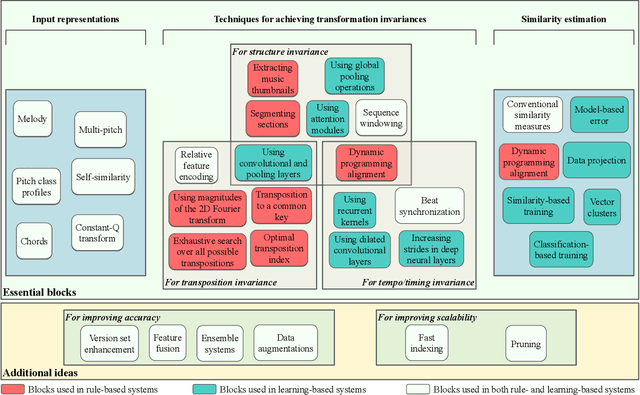
In this article, we aim to provide a review of the key ideas and approaches proposed in 20 years of scientific literature around musical version identification (VI) research and connect them to current practice. For more than a decade, VI systems suffered from the accuracy-scalability trade-off, with attempts to increase accuracy that typically resulted in cumbersome, non-scalable systems. Recent years, however, have witnessed the rise of deep learning-based approaches that take a step toward bridging the accuracy-scalability gap, yielding systems that can realistically be deployed in industrial applications. Although this trend positively influences the number of researchers and institutions working on VI, it may also result in obscuring the literature before the deep learning era. To appreciate two decades of novel ideas in VI research and to facilitate building better systems, we now review some of the successful concepts and applications proposed in the literature and study their evolution throughout the years.
A Prototypical Triplet Loss for Cover Detection
Oct 22, 2019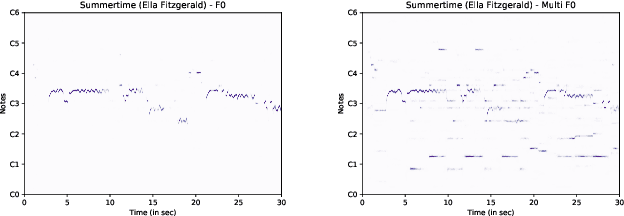
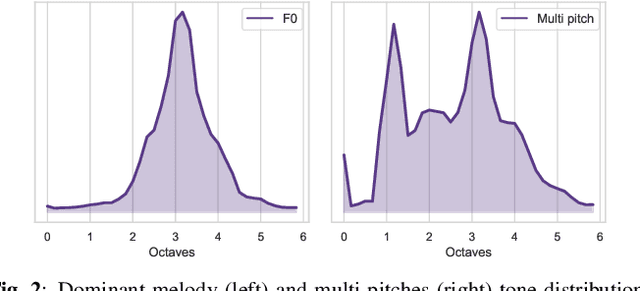

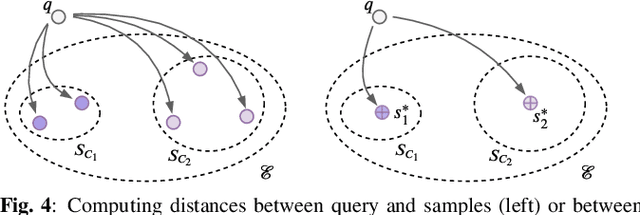
Automatic cover detection -- the task of finding in a audio dataset all covers of a query track -- has long been a challenging theoretical problem in MIR community. It also became a practical need for music composers societies requiring to detect automatically if an audio excerpt embeds musical content belonging to their catalog. In a recent work, we addressed this problem with a convolutional neural network mapping each track's dominant melody to an embedding vector, and trained to minimize cover pairs distance in the embeddings space, while maximizing it for non-covers. We showed in particular that training this model with enough works having five or more covers yields state-of-the-art results. This however does not reflect the realistic use case, where music catalogs typically contain works with zero or at most one or two covers. We thus introduce here a new test set incorporating these constraints, and propose two contributions to improve our model's accuracy under these stricter conditions: we replace dominant melody with multi-pitch representation as input data, and describe a novel prototypical triplet loss designed to improve covers clustering. We show that these changes improve results significantly for two concrete use cases, large dataset lookup and live songs identification.
Cover Detection using Dominant Melody Embeddings
Jul 03, 2019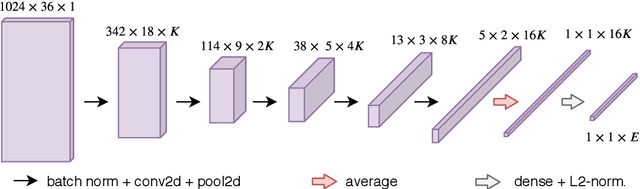
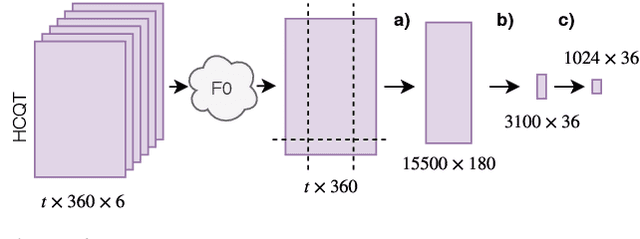

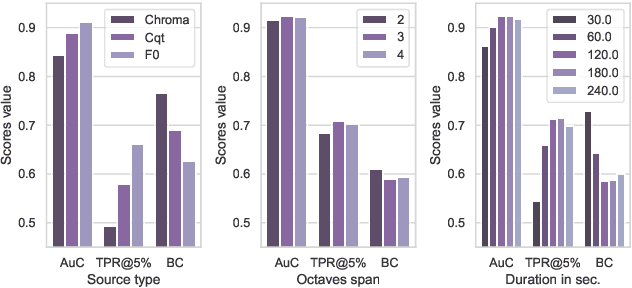
Automatic cover detection -- the task of finding in an audio database all the covers of one or several query tracks -- has long been seen as a challenging theoretical problem in the MIR community and as an acute practical problem for authors and composers societies. Original algorithms proposed for this task have proven their accuracy on small datasets, but are unable to scale up to modern real-life audio corpora. On the other hand, faster approaches designed to process thousands of pairwise comparisons resulted in lower accuracy, making them unsuitable for practical use. In this work, we propose a neural network architecture that is trained to represent each track as a single embedding vector. The computation burden is therefore left to the embedding extraction -- that can be conducted offline and stored, while the pairwise comparison task reduces to a simple Euclidean distance computation. We further propose to extract each track's embedding out of its dominant melody representation, obtained by another neural network trained for this task. We then show that this architecture improves state-of-the-art accuracy both on small and large datasets, and is able to scale to query databases of thousands of tracks in a few seconds.