 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLark: A Multimodal Foundation Model for Music
Oct 11, 2023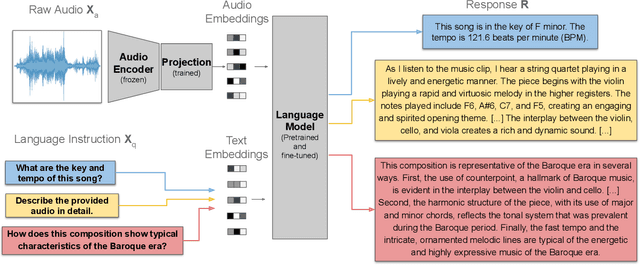
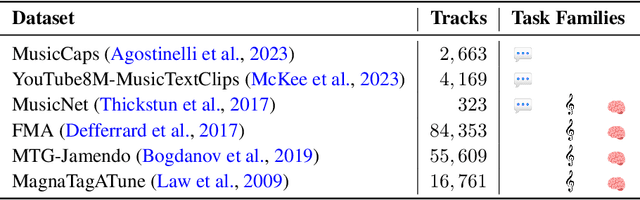
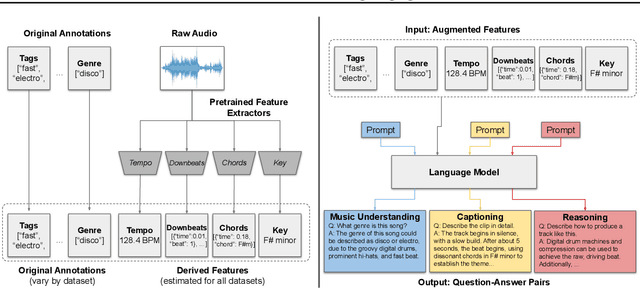
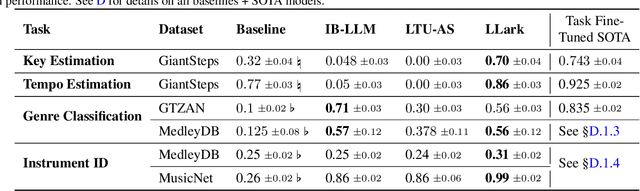
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for music understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, and reasoning), we show that our model matches or outperforms existing baselines in zero-shot generalization for music understanding, and that humans show a high degree of agreement with the model's responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
Few-Shot Musical Source Separation
May 03, 2022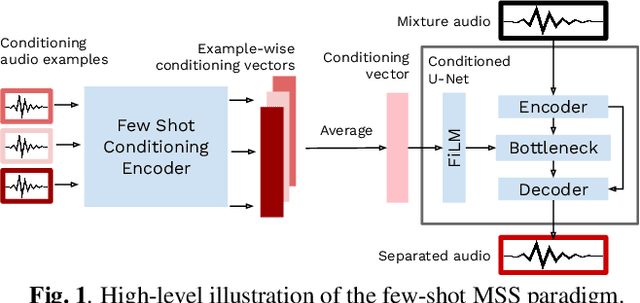
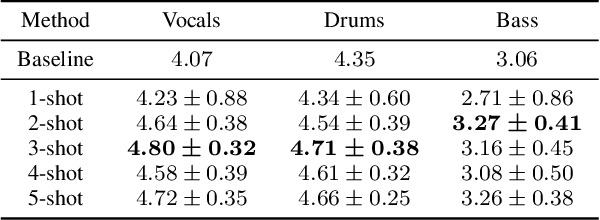
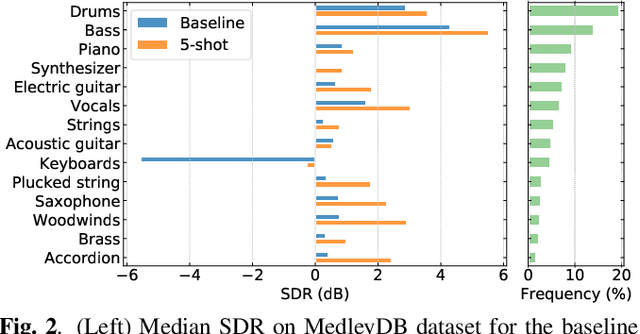

Deep learning-based approaches to musical source separation are often limited to the instrument classes that the models are trained on and do not generalize to separate unseen instruments. To address this, we propose a few-shot musical source separation paradigm. We condition a generic U-Net source separation model using few audio examples of the target instrument. We train a few-shot conditioning encoder jointly with the U-Net to encode the audio examples into a conditioning vector to configure the U-Net via feature-wise linear modulation (FiLM). We evaluate the trained models on real musical recordings in the MUSDB18 and MedleyDB datasets. We show that our proposed few-shot conditioning paradigm outperforms the baseline one-hot instrument-class conditioned model for both seen and unseen instruments. To extend the scope of our approach to a wider variety of real-world scenarios, we also experiment with different conditioning example characteristics, including examples from different recordings, with multiple sources, or negative conditioning examples.
A Lightweight Instrument-Agnostic Model for Polyphonic Note Transcription and Multipitch Estimation
Mar 18, 2022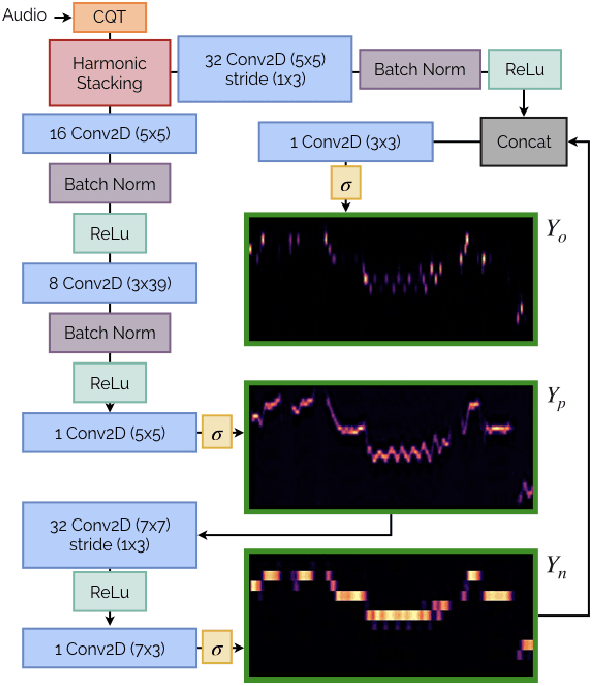
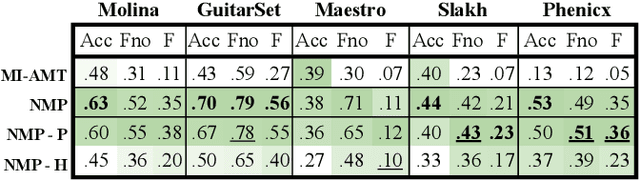
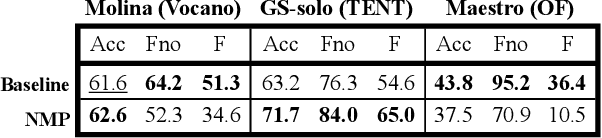
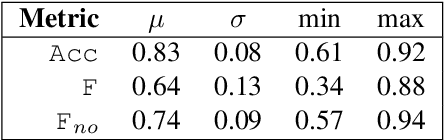
Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise $f_0$ values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems.
vocadito: A dataset of solo vocals with $f_0$, note, and lyric annotations
Oct 29, 2021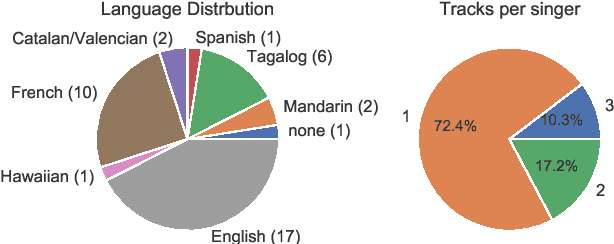

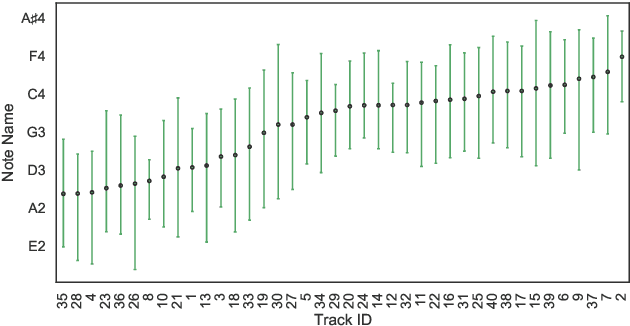
To compliment the existing set of datasets, we present a small dataset entitled vocadito, consisting of 40 short excerpts of monophonic singing, sung in 7 different languages by singers with varying of levels of training, and recorded on a variety of devices. We provide several types of annotations, including $f_0$, lyrics, and two different note annotations. All annotations were created by musicians. We provide an analysis of the differences between the two note annotations, and see that the agreement level is low, which has implications for evaluating vocal note estimation algorithms. We also analyze the relation between the $f_0$ and note annotations, and show that quantizing $f_0$ values in frequency does not provide a reasonable note estimate, reinforcing the difficulty of the note estimation task for singing voice. Finally, we provide baseline results from recent algorithms on vocadito for note and $f_0$ transcription. Vocadito is made freely available for public use.
Audio-based Musical Version Identification: Elements and Challenges
Sep 06, 2021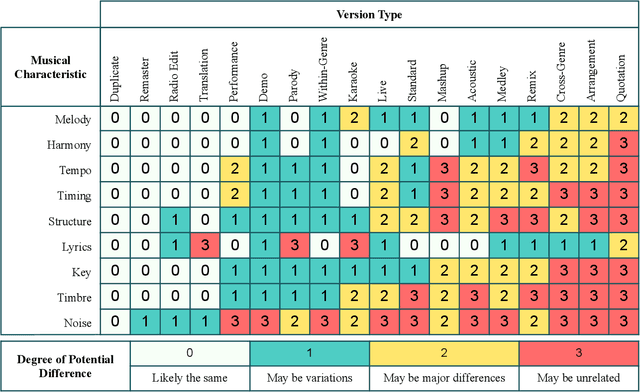
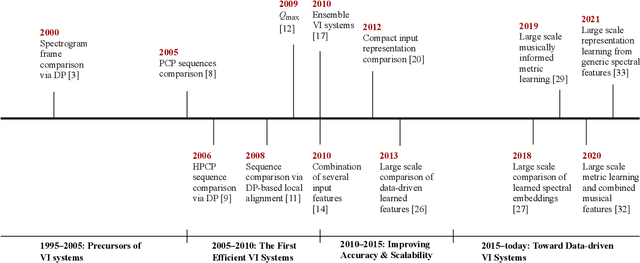
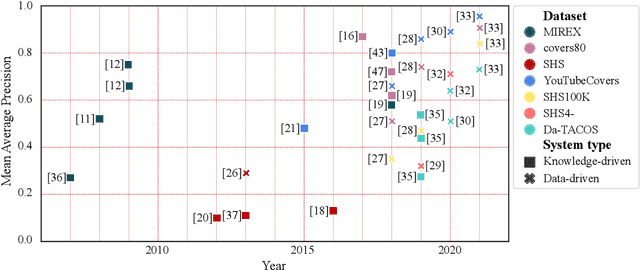
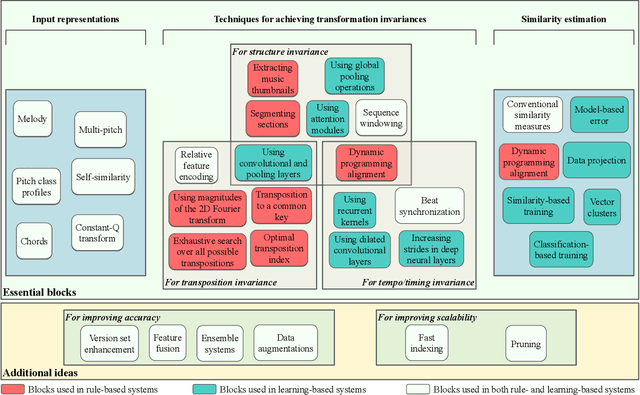
In this article, we aim to provide a review of the key ideas and approaches proposed in 20 years of scientific literature around musical version identification (VI) research and connect them to current practice. For more than a decade, VI systems suffered from the accuracy-scalability trade-off, with attempts to increase accuracy that typically resulted in cumbersome, non-scalable systems. Recent years, however, have witnessed the rise of deep learning-based approaches that take a step toward bridging the accuracy-scalability gap, yielding systems that can realistically be deployed in industrial applications. Although this trend positively influences the number of researchers and institutions working on VI, it may also result in obscuring the literature before the deep learning era. To appreciate two decades of novel ideas in VI research and to facilitate building better systems, we now review some of the successful concepts and applications proposed in the literature and study their evolution throughout the years.
Learned complex masks for multi-instrument source separation
Mar 23, 2021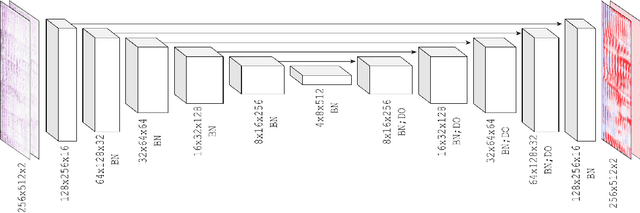
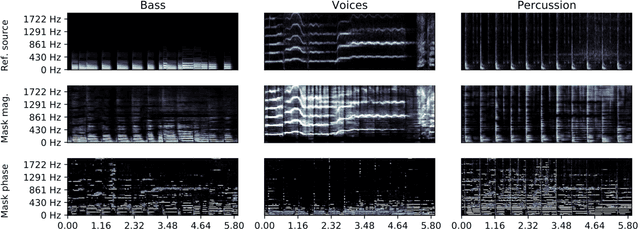
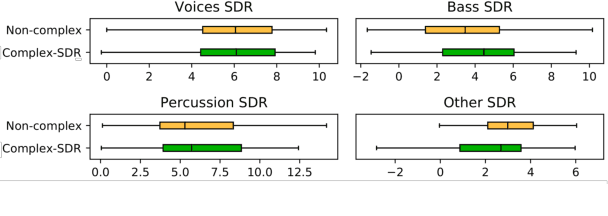
Music source separation in the time-frequency domain is commonly achieved by applying a soft or binary mask to the magnitude component of (complex) spectrograms. The phase component is usually not estimated, but instead copied from the mixture and applied to the magnitudes of the estimated isolated sources. While this method has several practical advantages, it imposes an upper bound on the performance of the system, where the estimated isolated sources inherently exhibit audible "phase artifacts". In this paper we address these shortcomings by directly estimating masks in the complex domain, extending recent work from the speech enhancement literature. The method is particularly well suited for multi-instrument musical source separation since residual phase artifacts are more pronounced for spectrally overlapping instrument sources, a common scenario in music. We show that complex masks result in better separation than masks that operate solely on the magnitude component.
Multitask Learning for Fundamental Frequency Estimation in Music
Sep 02, 2018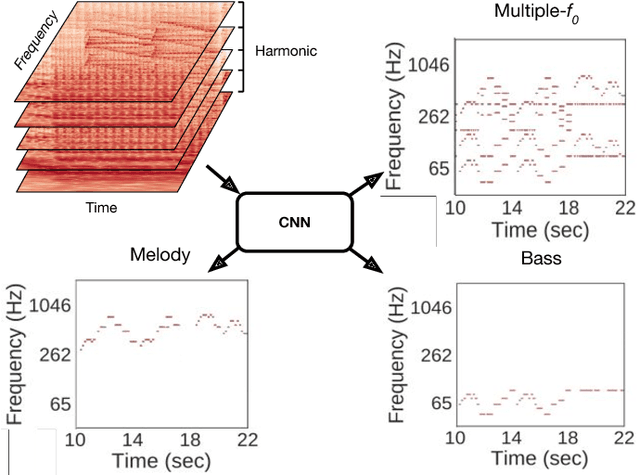
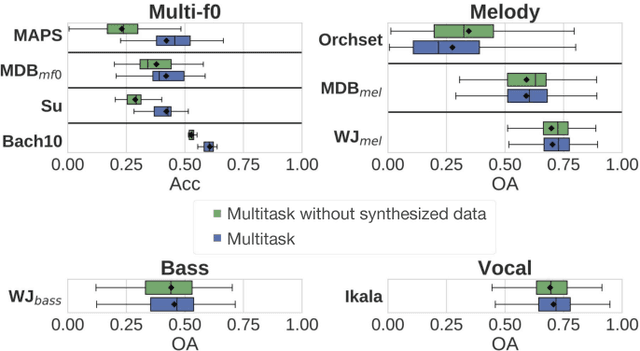
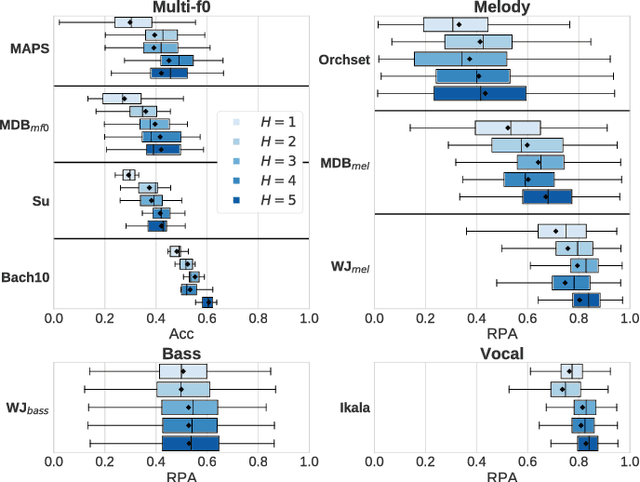
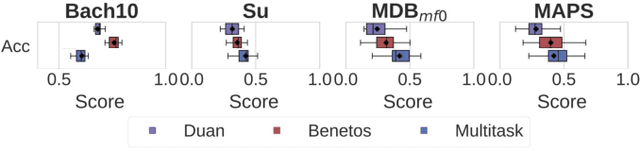
Fundamental frequency (f0) estimation from polyphonic music includes the tasks of multiple-f0, melody, vocal, and bass line estimation. Historically these problems have been approached separately, and only recently, using learning-based approaches. We present a multitask deep learning architecture that jointly estimates outputs for various tasks including multiple-f0, melody, vocal and bass line estimation, and is trained using a large, semi-automatically annotated dataset. We show that the multitask model outperforms its single-task counterparts, and explore the effect of various design decisions in our approach, and show that it performs better or at least competitively when compared against strong baseline methods.