 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying Pokémon Red via Deep Reinforcement Learning
Feb 27, 2025Pok\'emon Red, a classic Game Boy JRPG, presents significant challenges as a testbed for agents, including multi-tasking, long horizons of tens of thousands of steps, hard exploration, and a vast array of potential policies. We introduce a simplistic environment and a Deep Reinforcement Learning (DRL) training methodology, demonstrating a baseline agent that completes an initial segment of the game up to completing Cerulean City. Our experiments include various ablations that reveal vulnerabilities in reward shaping, where agents exploit specific reward signals. We also discuss limitations and argue that games like Pok\'emon hold strong potential for future research on Large Language Model agents, hierarchical training algorithms, and advanced exploration methods. Source Code: https://github.com/MarcoMeter/neroRL/tree/poke_red
A Lightweight Instrument-Agnostic Model for Polyphonic Note Transcription and Multipitch Estimation
Mar 18, 2022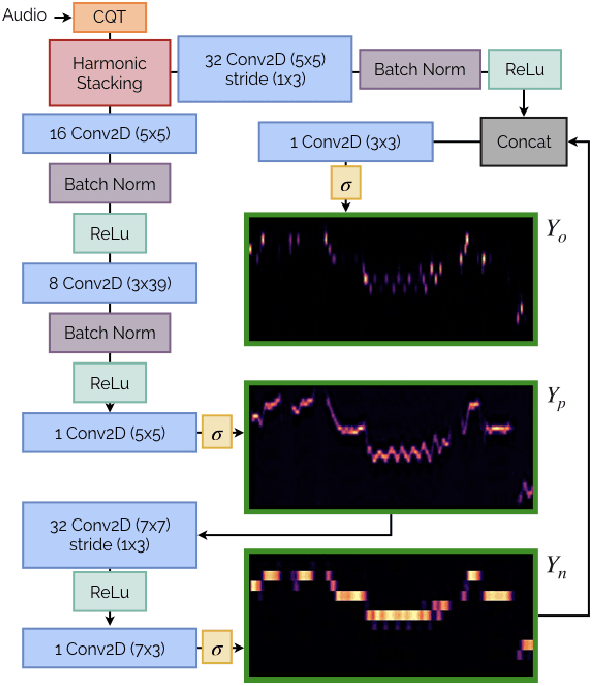
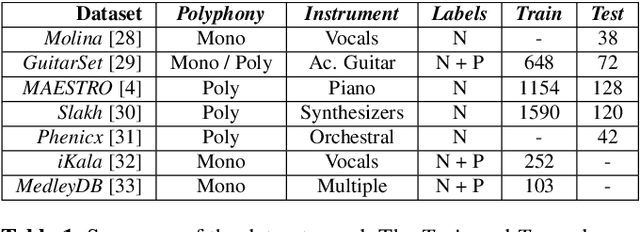
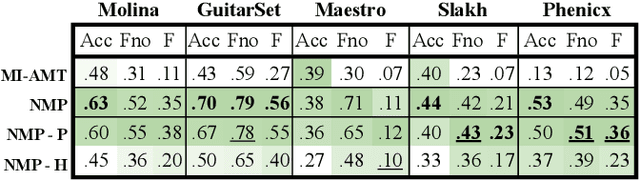
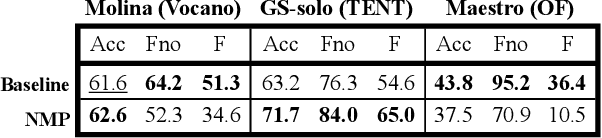
Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise $f_0$ values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems.
vocadito: A dataset of solo vocals with $f_0$, note, and lyric annotations
Oct 29, 2021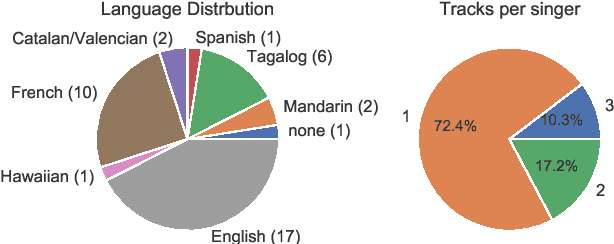

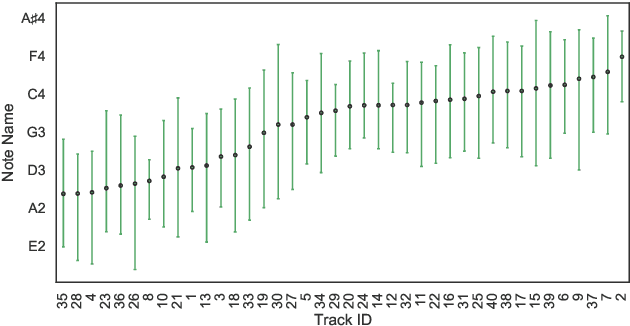
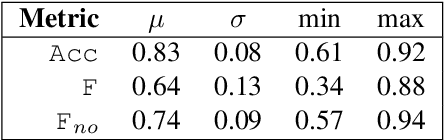
To compliment the existing set of datasets, we present a small dataset entitled vocadito, consisting of 40 short excerpts of monophonic singing, sung in 7 different languages by singers with varying of levels of training, and recorded on a variety of devices. We provide several types of annotations, including $f_0$, lyrics, and two different note annotations. All annotations were created by musicians. We provide an analysis of the differences between the two note annotations, and see that the agreement level is low, which has implications for evaluating vocal note estimation algorithms. We also analyze the relation between the $f_0$ and note annotations, and show that quantizing $f_0$ values in frequency does not provide a reasonable note estimate, reinforcing the difficulty of the note estimation task for singing voice. Finally, we provide baseline results from recent algorithms on vocadito for note and $f_0$ transcription. Vocadito is made freely available for public use.