 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgevocadito: A dataset of solo vocals with $f_0$, note, and lyric annotations
Oct 29, 2021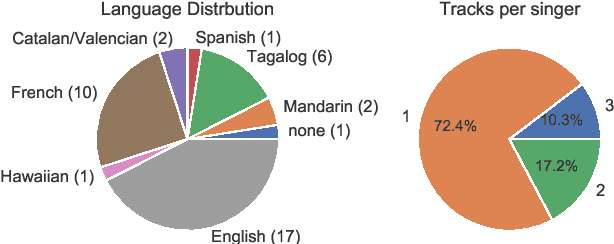

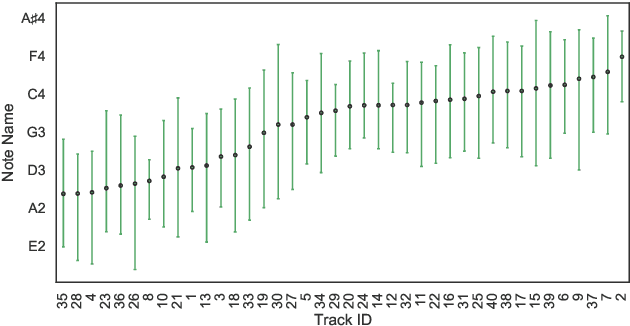
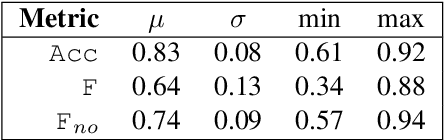
To compliment the existing set of datasets, we present a small dataset entitled vocadito, consisting of 40 short excerpts of monophonic singing, sung in 7 different languages by singers with varying of levels of training, and recorded on a variety of devices. We provide several types of annotations, including $f_0$, lyrics, and two different note annotations. All annotations were created by musicians. We provide an analysis of the differences between the two note annotations, and see that the agreement level is low, which has implications for evaluating vocal note estimation algorithms. We also analyze the relation between the $f_0$ and note annotations, and show that quantizing $f_0$ values in frequency does not provide a reasonable note estimate, reinforcing the difficulty of the note estimation task for singing voice. Finally, we provide baseline results from recent algorithms on vocadito for note and $f_0$ transcription. Vocadito is made freely available for public use.