 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings
Jan 16, 2026Music Cover Retrieval, also known as Version Identification, aims to recognize distinct renditions of the same underlying musical work, a task central to catalog management, copyright enforcement, and music retrieval. State-of-the-art approaches have largely focused on harmonic and melodic features, employing increasingly complex audio pipelines designed to be invariant to musical attributes that often vary widely across covers. While effective, these methods demand substantial training time and computational resources. By contrast, lyrics constitute a strong invariant across covers, though their use has been limited by the difficulty of extracting them accurately and efficiently from polyphonic audio. Early methods relied on simple frameworks that limited downstream performance, while more recent systems deliver stronger results but require large models integrated within complex multimodal architectures. We introduce LIVI (Lyrics-Informed Version Identification), an approach that seeks to balance retrieval accuracy with computational efficiency. First, LIVI leverages supervision from state-of-the-art transcription and text embedding models during training to achieve retrieval accuracy on par with--or superior to--harmonic-based systems. Second, LIVI remains lightweight and efficient by removing the transcription step at inference, challenging the dominance of complexity-heavy pipelines.
"Beyond the past": Leveraging Audio and Human Memory for Sequential Music Recommendation
Jul 23, 2025On music streaming services, listening sessions are often composed of a balance of familiar and new tracks. Recently, sequential recommender systems have adopted cognitive-informed approaches, such as Adaptive Control of Thought-Rational (ACT-R), to successfully improve the prediction of the most relevant tracks for the next user session. However, one limitation of using a model inspired by human memory (or the past), is that it struggles to recommend new tracks that users have not previously listened to. To bridge this gap, here we propose a model that leverages audio information to predict in advance the ACT-R-like activation of new tracks and incorporates them into the recommendation scoring process. We demonstrate the empirical effectiveness of the proposed model using proprietary data, which we publicly release along with the model's source code to foster future research in this field.
AI-Generated Music Detection and its Challenges
Jan 17, 2025


In the face of a new era of generative models, the detection of artificially generated content has become a matter of utmost importance. In particular, the ability to create credible minute-long synthetic music in a few seconds on user-friendly platforms poses a real threat of fraud on streaming services and unfair competition to human artists. This paper demonstrates the possibility (and surprising ease) of training classifiers on datasets comprising real audio and artificial reconstructions, achieving a convincing accuracy of 99.8%. To our knowledge, this marks the first publication of a AI-music detector, a tool that will help in the regulation of synthetic media. Nevertheless, informed by decades of literature on forgery detection in other fields, we stress that getting a good test score is not the end of the story. We expose and discuss several facets that could be problematic with such a deployed detector: robustness to audio manipulation, generalisation to unseen models. This second part acts as a position for future research steps in the field and a caveat to a flourishing market of artificial content checkers.
From Real to Cloned Singer Identification
Jul 11, 2024
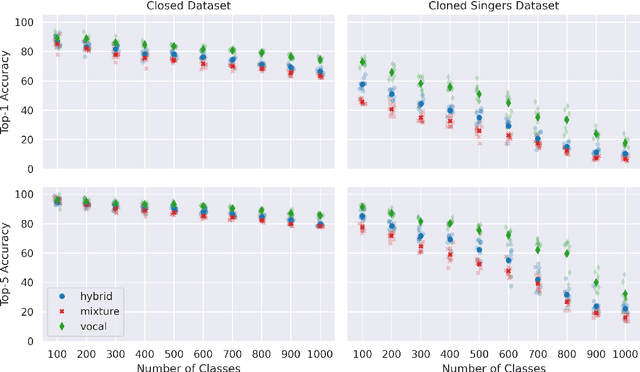

Cloned voices of popular singers sound increasingly realistic and have gained popularity over the past few years. They however pose a threat to the industry due to personality rights concerns. As such, methods to identify the original singer in synthetic voices are needed. In this paper, we investigate how singer identification methods could be used for such a task. We present three embedding models that are trained using a singer-level contrastive learning scheme, where positive pairs consist of segments with vocals from the same singers. These segments can be mixtures for the first model, vocals for the second, and both for the third. We demonstrate that all three models are highly capable of identifying real singers. However, their performance deteriorates when classifying cloned versions of singers in our evaluation set. This is especially true for models that use mixtures as an input. These findings highlight the need to understand the biases that exist within singer identification systems, and how they can influence the identification of voice deepfakes in music.
STONE: Self-supervised Tonality Estimator
Jul 10, 2024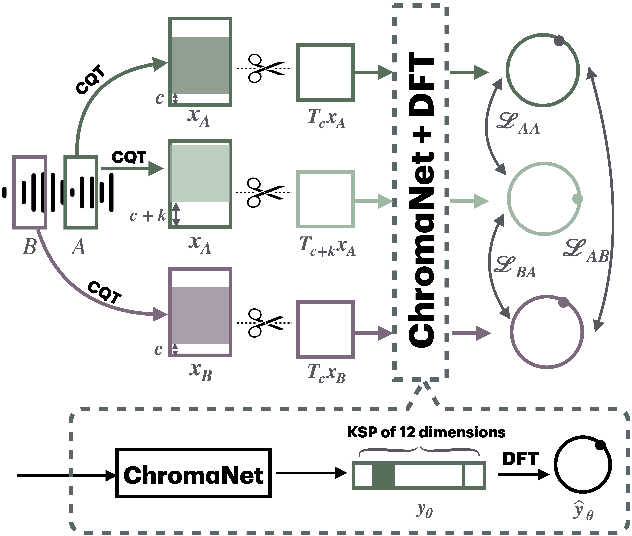
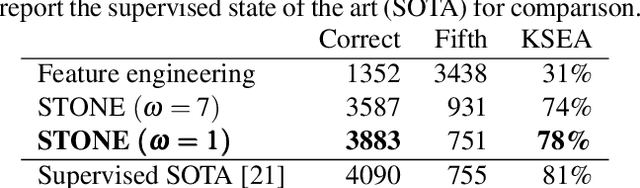

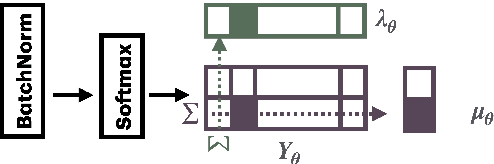
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a key signature profile (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
Detecting Synthetic Lyrics with Few-Shot Inference
Jun 21, 2024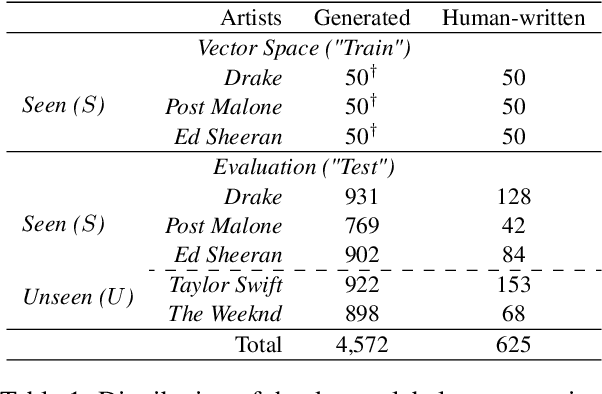

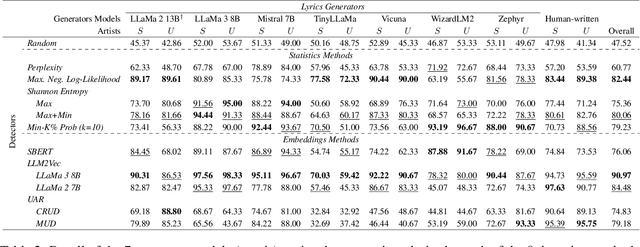
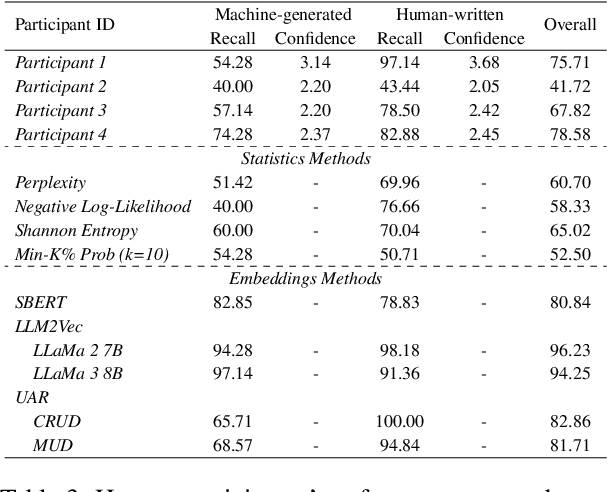
In recent years, generated content in music has gained significant popularity, with large language models being effectively utilized to produce human-like lyrics in various styles, themes, and linguistic structures. This technological advancement supports artists in their creative processes but also raises issues of authorship infringement, consumer satisfaction and content spamming. To address these challenges, methods for detecting generated lyrics are necessary. However, existing works have not yet focused on this specific modality or on creative text in general regarding machine-generated content detection methods and datasets. In response, we have curated the first dataset of high-quality synthetic lyrics and conducted a comprehensive quantitative evaluation of various few-shot content detection approaches, testing their generalization capabilities and complementing this with a human evaluation. Our best few-shot detector, based on LLM2Vec, surpasses stylistic and statistical methods, which are shown competitive in other domains at distinguishing human-written from machine-generated content. It also shows good generalization capabilities to new artists and models, and effectively detects post-generation paraphrasing. This study emphasizes the need for further research on creative content detection, particularly in terms of generalization and scalability with larger song catalogs. All datasets, pre-processing scripts, and code are available publicly on GitHub and Hugging Face under the Apache 2.0 license.
An Experimental Comparison Of Multi-view Self-supervised Methods For Music Tagging
Apr 14, 2024


Self-supervised learning has emerged as a powerful way to pre-train generalizable machine learning models on large amounts of unlabeled data. It is particularly compelling in the music domain, where obtaining labeled data is time-consuming, error-prone, and ambiguous. During the self-supervised process, models are trained on pretext tasks, with the primary objective of acquiring robust and informative features that can later be fine-tuned for specific downstream tasks. The choice of the pretext task is critical as it guides the model to shape the feature space with meaningful constraints for information encoding. In the context of music, most works have relied on contrastive learning or masking techniques. In this study, we expand the scope of pretext tasks applied to music by investigating and comparing the performance of new self-supervised methods for music tagging. We open-source a simple ResNet model trained on a diverse catalog of millions of tracks. Our results demonstrate that, although most of these pre-training methods result in similar downstream results, contrastive learning consistently results in better downstream performance compared to other self-supervised pre-training methods. This holds true in a limited-data downstream context.
A Lightweight Instrument-Agnostic Model for Polyphonic Note Transcription and Multipitch Estimation
Mar 18, 2022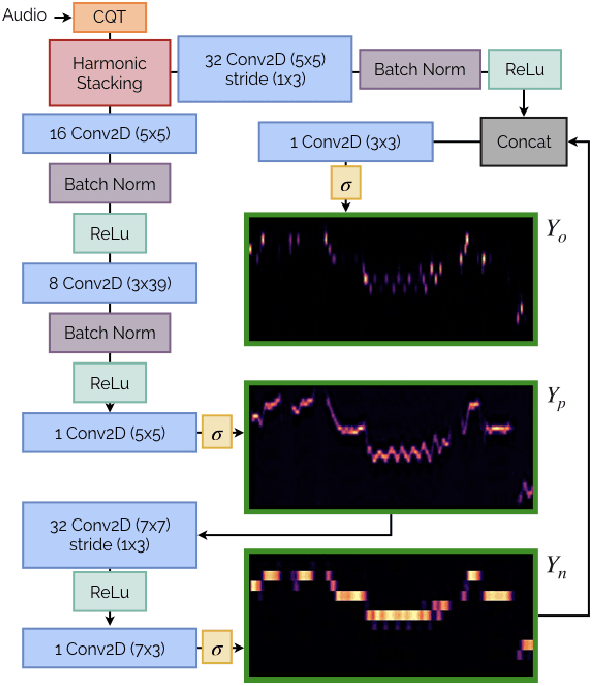
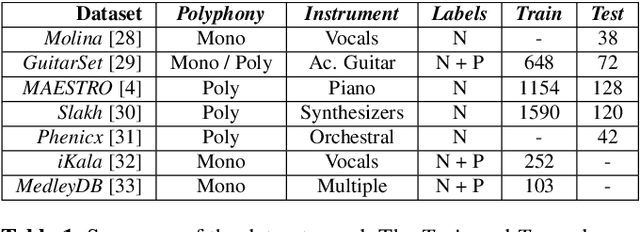
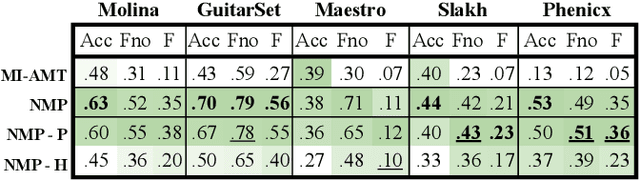
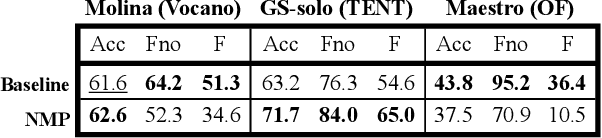
Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise $f_0$ values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems.
vocadito: A dataset of solo vocals with $f_0$, note, and lyric annotations
Oct 29, 2021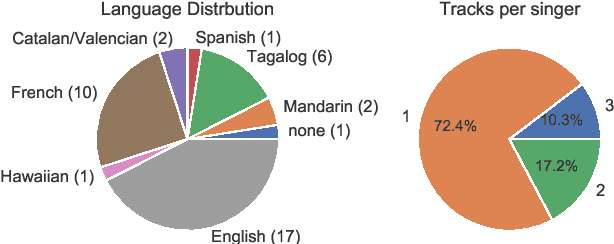

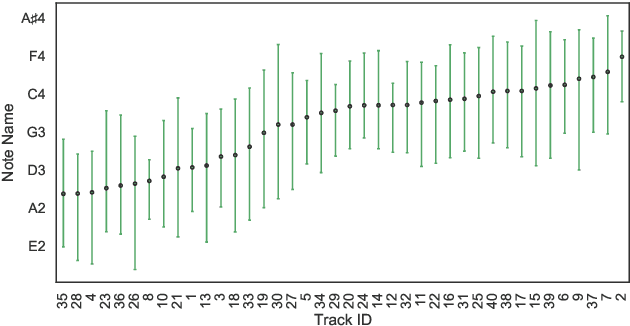
To compliment the existing set of datasets, we present a small dataset entitled vocadito, consisting of 40 short excerpts of monophonic singing, sung in 7 different languages by singers with varying of levels of training, and recorded on a variety of devices. We provide several types of annotations, including $f_0$, lyrics, and two different note annotations. All annotations were created by musicians. We provide an analysis of the differences between the two note annotations, and see that the agreement level is low, which has implications for evaluating vocal note estimation algorithms. We also analyze the relation between the $f_0$ and note annotations, and show that quantizing $f_0$ values in frequency does not provide a reasonable note estimate, reinforcing the difficulty of the note estimation task for singing voice. Finally, we provide baseline results from recent algorithms on vocadito for note and $f_0$ transcription. Vocadito is made freely available for public use.
MULTIMODAL ANALYSIS: Informed content estimation and audio source separation
May 03, 2021
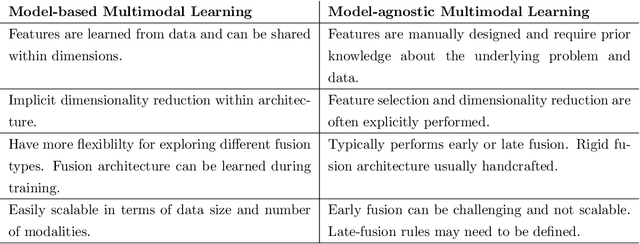
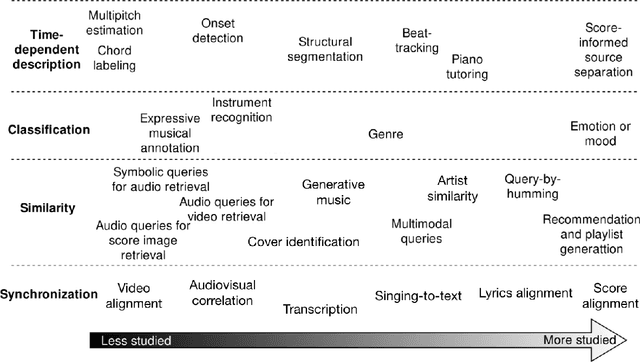
This dissertation proposes the study of multimodal learning in the context of musical signals. Throughout, we focus on the interaction between audio signals and text information. Among the many text sources related to music that can be used (e.g. reviews, metadata, or social network feedback), we concentrate on lyrics. The singing voice directly connects the audio signal and the text information in a unique way, combining melody and lyrics where a linguistic dimension complements the abstraction of musical instruments. Our study focuses on the audio and lyrics interaction for targeting source separation and informed content estimation.