 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLacking Data? No worries! How synthetic images can alleviate image scarcity in wildlife surveys: a case study with muskox (Ovibos moschatus)
Nov 14, 2025Accurate population estimates are essential for wildlife management, providing critical insights into species abundance and distribution. Traditional survey methods, including visual aerial counts and GNSS telemetry tracking, are widely used to monitor muskox populations in Arctic regions. These approaches are resource intensive and constrained by logistical challenges. Advances in remote sensing, artificial intelligence, and high resolution aerial imagery offer promising alternatives for wildlife detection. Yet, the effectiveness of deep learning object detection models (ODMs) is often limited by small datasets, making it challenging to train robust ODMs for sparsely distributed species like muskoxen. This study investigates the integration of synthetic imagery (SI) to supplement limited training data and improve muskox detection in zero shot (ZS) and few-shot (FS) settings. We compared a baseline model trained on real imagery with 5 ZS and 5 FS models that incorporated progressively more SI in the training set. For the ZS models, where no real images were included in the training set, adding SI improved detection performance. As more SI were added, performance in precision, recall and F1 score increased, but eventually plateaued, suggesting diminishing returns when SI exceeded 100% of the baseline model training dataset. For FS models, combining real and SI led to better recall and slightly higher overall accuracy compared to using real images alone, though these improvements were not statistically significant. Our findings demonstrate the potential of SI to train accurate ODMs when data is scarce, offering important perspectives for wildlife monitoring by enabling rare or inaccessible species to be monitored and to increase monitoring frequency. This approach could be used to initiate ODMs without real data and refine it as real images are acquired over time.
Automatic Identification of Samples in Hip-Hop Music via Multi-Loss Training and an Artificial Dataset
Feb 10, 2025Sampling, the practice of reusing recorded music or sounds from another source in a new work, is common in popular music genres like hip-hop and rap. Numerous services have emerged that allow users to identify connections between samples and the songs that incorporate them, with the goal of enhancing music discovery. Designing a system that can perform the same task automatically is challenging, as samples are commonly altered with audio effects like pitch- and time-stretching and may only be seconds long. Progress on this task has been minimal and is further blocked by the limited availability of training data. Here, we show that a convolutional neural network trained on an artificial dataset can identify real-world samples in commercial hip-hop music. We extract vocal, harmonic, and percussive elements from several databases of non-commercial music recordings using audio source separation, and train the model to fingerprint a subset of these elements in transformed versions of the original audio. We optimize the model using a joint classification and metric learning loss and show that it achieves 13% greater precision on real-world instances of sampling than a fingerprinting system using acoustic landmarks, and that it can recognize samples that have been both pitch shifted and time stretched. We also show that, for half of the commercial music recordings we tested, our model is capable of locating the position of a sample to within five seconds.
LLark: A Multimodal Foundation Model for Music
Oct 11, 2023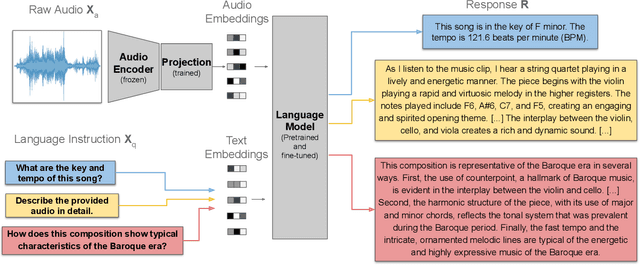
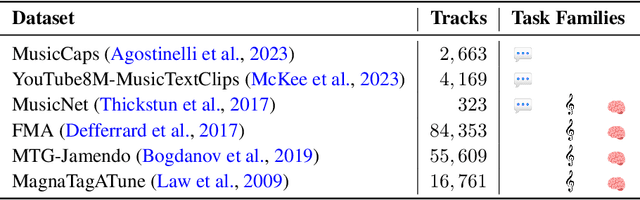
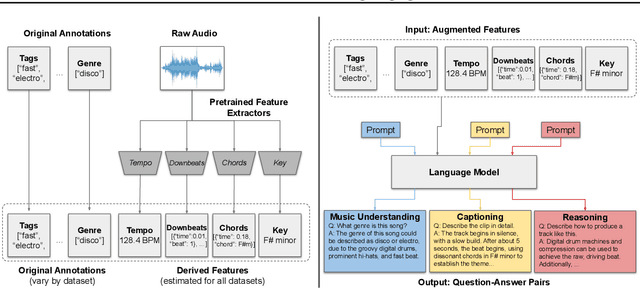
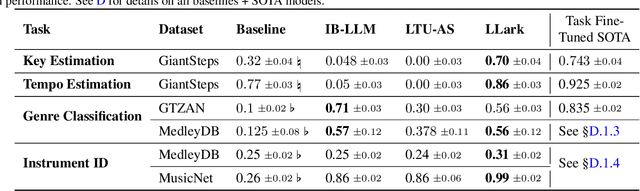
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for music understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, and reasoning), we show that our model matches or outperforms existing baselines in zero-shot generalization for music understanding, and that humans show a high degree of agreement with the model's responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
Contrastive Learning-Based Audio to Lyrics Alignment for Multiple Languages
Jun 13, 2023Lyrics alignment gained considerable attention in recent years. State-of-the-art systems either re-use established speech recognition toolkits, or design end-to-end solutions involving a Connectionist Temporal Classification (CTC) loss. However, both approaches suffer from specific weaknesses: toolkits are known for their complexity, and CTC systems use a loss designed for transcription which can limit alignment accuracy. In this paper, we use instead a contrastive learning procedure that derives cross-modal embeddings linking the audio and text domains. This way, we obtain a novel system that is simple to train end-to-end, can make use of weakly annotated training data, jointly learns a powerful text model, and is tailored to alignment. The system is not only the first to yield an average absolute error below 0.2 seconds on the standard Jamendo dataset but it is also robust to other languages, even when trained on English data only. Finally, we release word-level alignments for the JamendoLyrics Multi-Lang dataset.
* 5 pages, accepted at the International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023
Data Cleansing with Contrastive Learning for Vocal Note Event Annotations
Aug 05, 2020
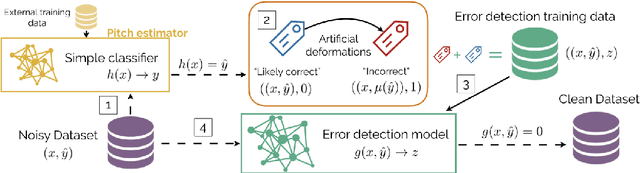

Data cleansing is a well studied strategy for cleaning erroneous labels in datasets, which has not yet been widely adopted in Music Information Retrieval. Previously proposed data cleansing models do not consider structured (e.g. time varying) labels, such as those common to music data. We propose a novel data cleansing model for time-varying, structured labels which exploits the local structure of the labels, and demonstrate its usefulness for vocal note event annotations in music. %Our model is trained in a contrastive learning manner by automatically creating local deformations of likely correct labels. Our model is trained in a contrastive learning manner by automatically contrasting likely correct labels pairs against local deformations of them. We demonstrate that the accuracy of a transcription model improves greatly when trained using our proposed strategy compared with the accuracy when trained using the original dataset. Additionally we use our model to estimate the annotation error rates in the DALI dataset, and highlight other potential uses for this type of model.
Dereverberation using joint estimation of dry speech signal and acoustic system
Jul 24, 2020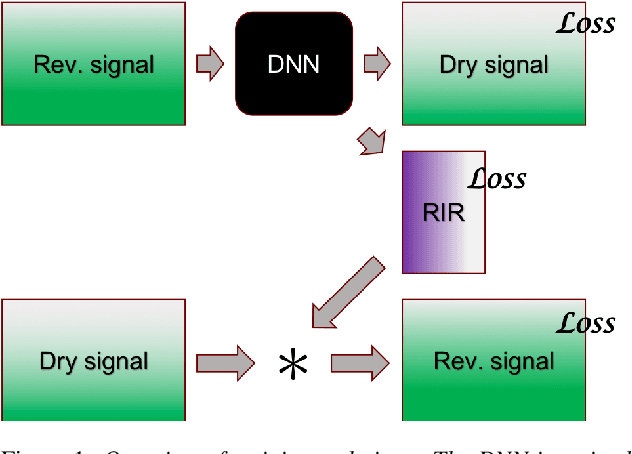
The purpose of speech dereverberation is to remove quality-degrading effects of a time-invariant impulse response filter from the signal. In this report, we describe an approach to speech dereverberation that involves joint estimation of the dry speech signal and of the room impulse response. We explore deep learning models that apply to each task separately, and how these can be combined in a joint model with shared parameters.
End-to-end Lyrics Alignment for Polyphonic Music Using an Audio-to-Character Recognition Model
Feb 18, 2019
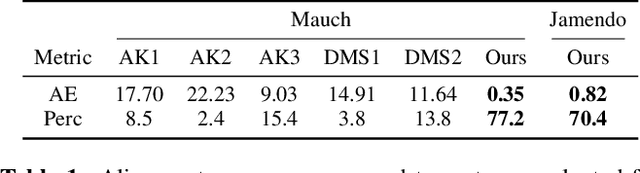
Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form. Here, we present a novel system based on a modified Wave-U-Net architecture, which predicts character probabilities directly from raw audio using learnt multi-scale representations of the various signal components. There are no sub-modules whose interdependencies need to be optimized. Our training procedure is designed to work with weak, line-level annotations available in the real world. With a mean alignment error of 0.35s on a standard dataset our system outperforms the state-of-the-art by an order of magnitude.