 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLark: A Multimodal Foundation Model for Music
Oct 11, 2023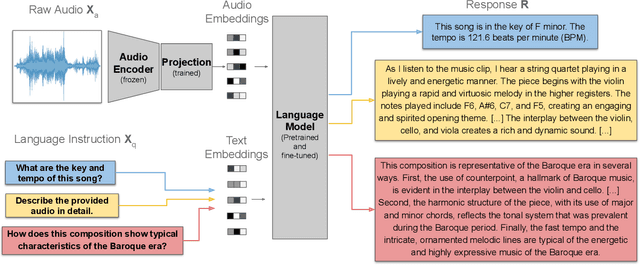
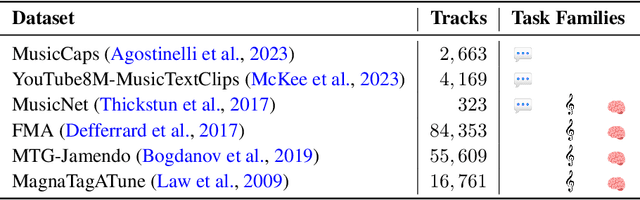
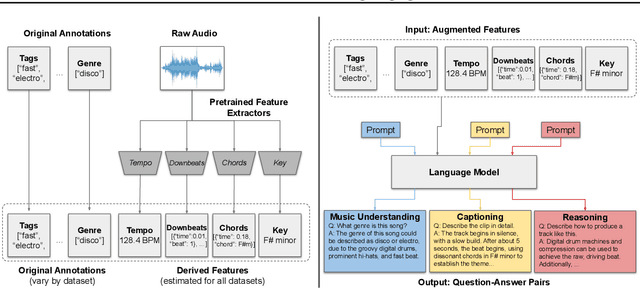
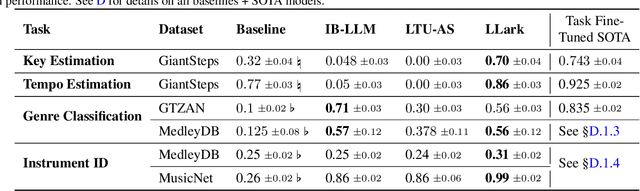
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for music understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, and reasoning), we show that our model matches or outperforms existing baselines in zero-shot generalization for music understanding, and that humans show a high degree of agreement with the model's responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
Contrastive Learning-Based Audio to Lyrics Alignment for Multiple Languages
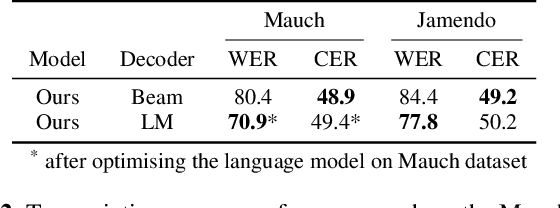
Jun 13, 2023Lyrics alignment gained considerable attention in recent years. State-of-the-art systems either re-use established speech recognition toolkits, or design end-to-end solutions involving a Connectionist Temporal Classification (CTC) loss. However, both approaches suffer from specific weaknesses: toolkits are known for their complexity, and CTC systems use a loss designed for transcription which can limit alignment accuracy. In this paper, we use instead a contrastive learning procedure that derives cross-modal embeddings linking the audio and text domains. This way, we obtain a novel system that is simple to train end-to-end, can make use of weakly annotated training data, jointly learns a powerful text model, and is tailored to alignment. The system is not only the first to yield an average absolute error below 0.2 seconds on the standard Jamendo dataset but it is also robust to other languages, even when trained on English data only. Finally, we release word-level alignments for the JamendoLyrics Multi-Lang dataset.
* 5 pages, accepted at the International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023
Few-Shot Musical Source Separation
May 03, 2022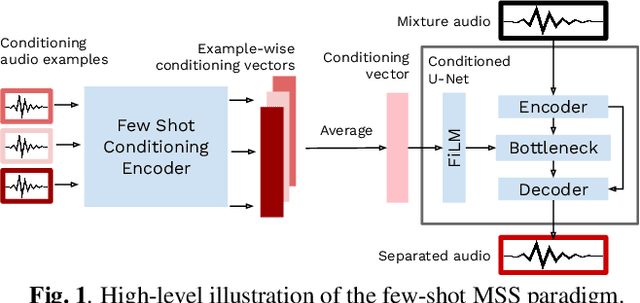
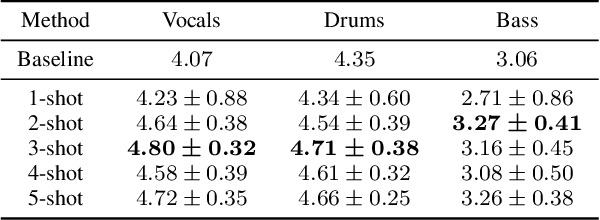
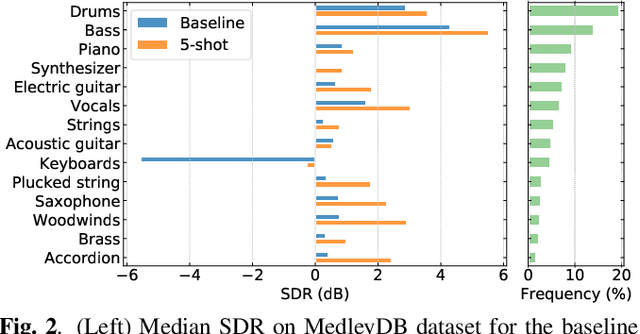

Deep learning-based approaches to musical source separation are often limited to the instrument classes that the models are trained on and do not generalize to separate unseen instruments. To address this, we propose a few-shot musical source separation paradigm. We condition a generic U-Net source separation model using few audio examples of the target instrument. We train a few-shot conditioning encoder jointly with the U-Net to encode the audio examples into a conditioning vector to configure the U-Net via feature-wise linear modulation (FiLM). We evaluate the trained models on real musical recordings in the MUSDB18 and MedleyDB datasets. We show that our proposed few-shot conditioning paradigm outperforms the baseline one-hot instrument-class conditioned model for both seen and unseen instruments. To extend the scope of our approach to a wider variety of real-world scenarios, we also experiment with different conditioning example characteristics, including examples from different recordings, with multiple sources, or negative conditioning examples.
Seq-U-Net: A One-Dimensional Causal U-Net for Efficient Sequence Modelling
Nov 14, 2019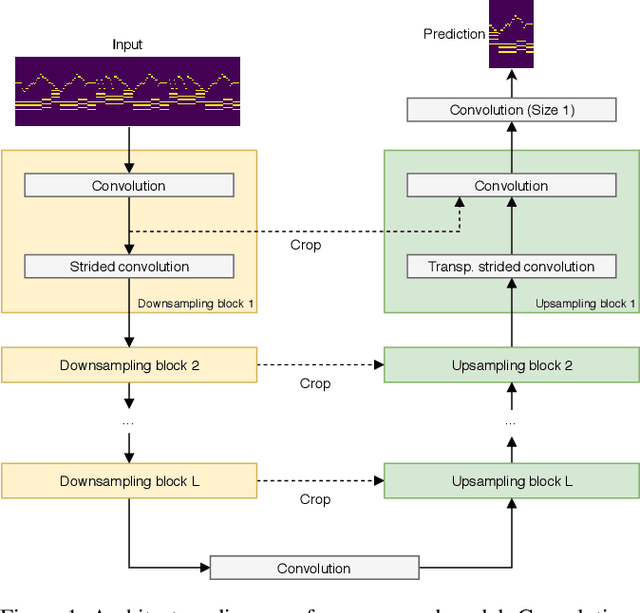

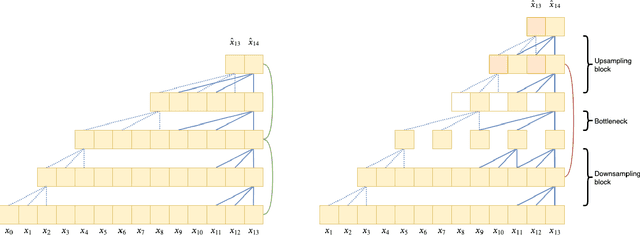

Convolutional neural networks (CNNs) with dilated filters such as the Wavenet or the Temporal Convolutional Network (TCN) have shown good results in a variety of sequence modelling tasks. However, efficiently modelling long-term dependencies in these sequences is still challenging. Although the receptive field of these models grows exponentially with the number of layers, computing the convolutions over very long sequences of features in each layer is time and memory-intensive, prohibiting the use of longer receptive fields in practice. To increase efficiency, we make use of the "slow feature" hypothesis stating that many features of interest are slowly varying over time. For this, we use a U-Net architecture that computes features at multiple time-scales and adapt it to our auto-regressive scenario by making convolutions causal. We apply our model ("Seq-U-Net") to a variety of tasks including language and audio generation. In comparison to TCN and Wavenet, our network consistently saves memory and computation time, with speed-ups for training and inference of over 4x in the audio generation experiment in particular, while achieving a comparable performance in all tasks.
Training Generative Adversarial Networks from Incomplete Observations using Factorised Discriminators
May 29, 2019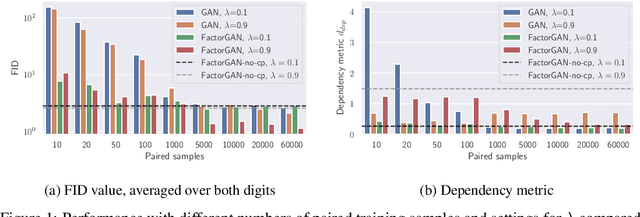

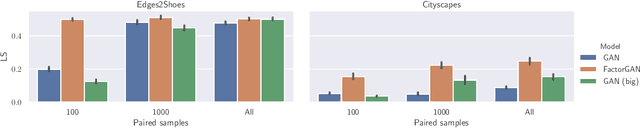

Generative adversarial networks (GANs) have shown great success in applications such as image generation and inpainting. To stabilize the challenging training process, one typically requires large datasets - which are not available for many tasks. Large amounts of additionally available incomplete observations could be exploited in many cases, but it remains unclear how to train a GAN in such a setting. To address this shortcoming, we factorise the high-dimensional joint distribution of the complete data into a set of lower-dimensional distributions along with their dependencies. As a consequence, we can split the discriminator in a GAN into multiple "sub-discriminators" that can be independently trained from incomplete observations. Their outputs can be combined to obtain an estimate of the density ratio between the joint real and the generator distribution, which enables training the generator as in the original GAN framework. As an additional benefit, our modularisation facilitates incorporating prior knowledge into the discriminator architecture. We apply our method to image generation, image segmentation and audio source separation, and show an improved performance compared to a standard GAN when additional incomplete training examples are available.
GAN-based Generation and Automatic Selection of Explanations for Neural Networks
Apr 27, 2019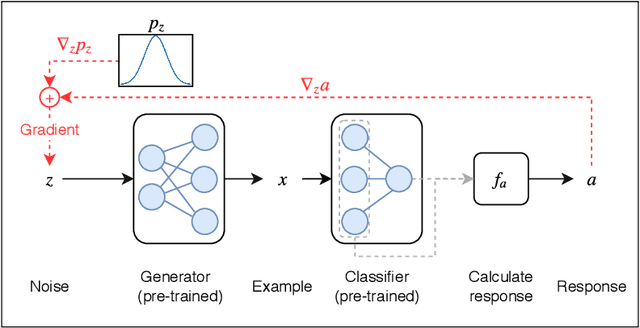
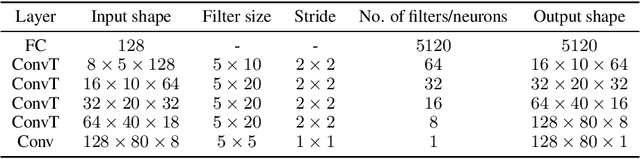
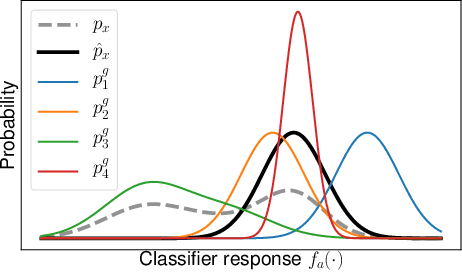
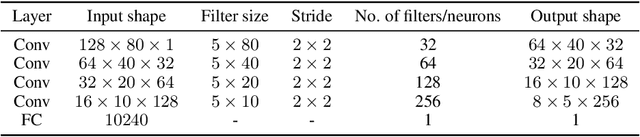
One way to interpret trained deep neural networks (DNNs) is by inspecting characteristics that neurons in the model respond to, such as by iteratively optimising the model input (e.g., an image) to maximally activate specific neurons. However, this requires a careful selection of hyper-parameters to generate interpretable examples for each neuron of interest, and current methods rely on a manual, qualitative evaluation of each setting, which is prohibitively slow. We introduce a new metric that uses Fr\'echet Inception Distance (FID) to encourage similarity between model activations for real and generated data. This provides an efficient way to evaluate a set of generated examples for each setting of hyper-parameters. We also propose a novel GAN-based method for generating explanations that enables an efficient search through the input space and imposes a strong prior favouring realistic outputs. We apply our approach to a classification model trained to predict whether a music audio recording contains singing voice. Our results suggest that this proposed metric successfully selects hyper-parameters leading to interpretable examples, avoiding the need for manual evaluation. Moreover, we see that examples synthesised to maximise or minimise the predicted probability of singing voice presence exhibit vocal or non-vocal characteristics, respectively, suggesting that our approach is able to generate suitable explanations for understanding concepts learned by a neural network.
* 8 pages plus references and appendix. Accepted at the ICLR 2019 Workshop "Safe Machine Learning: Specification, Robustness and Assurance". Camera-ready version. v2: Corrected page header
End-to-end Lyrics Alignment for Polyphonic Music Using an Audio-to-Character Recognition Model
Feb 18, 2019
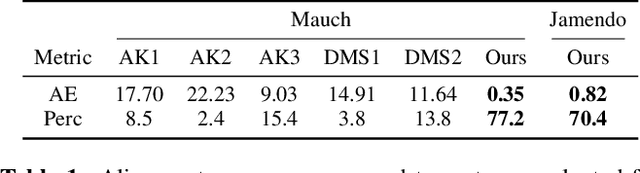
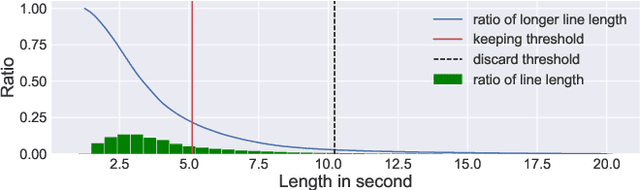
Time-aligned lyrics can enrich the music listening experience by enabling karaoke, text-based song retrieval and intra-song navigation, and other applications. Compared to text-to-speech alignment, lyrics alignment remains highly challenging, despite many attempts to combine numerous sub-modules including vocal separation and detection in an effort to break down the problem. Furthermore, training required fine-grained annotations to be available in some form. Here, we present a novel system based on a modified Wave-U-Net architecture, which predicts character probabilities directly from raw audio using learnt multi-scale representations of the various signal components. There are no sub-modules whose interdependencies need to be optimized. Our training procedure is designed to work with weak, line-level annotations available in the real world. With a mean alignment error of 0.35s on a standard dataset our system outperforms the state-of-the-art by an order of magnitude.
Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
Jun 08, 2018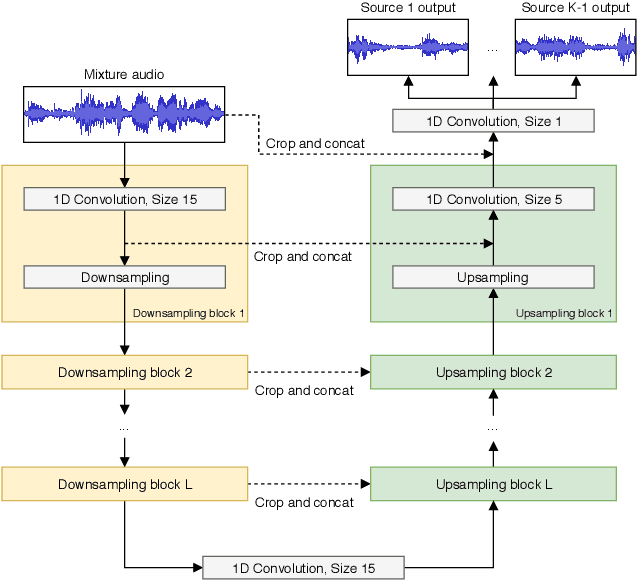
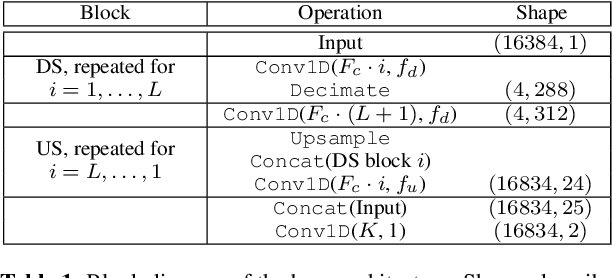
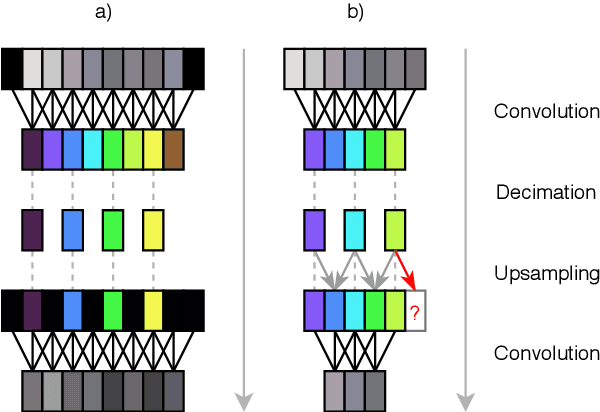
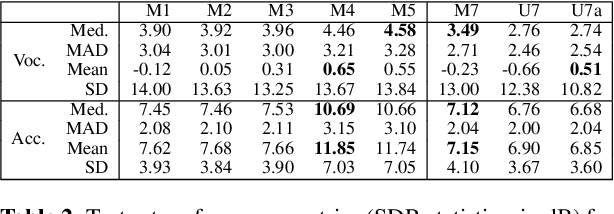
Models for audio source separation usually operate on the magnitude spectrum, which ignores phase information and makes separation performance dependant on hyper-parameters for the spectral front-end. Therefore, we investigate end-to-end source separation in the time-domain, which allows modelling phase information and avoids fixed spectral transformations. Due to high sampling rates for audio, employing a long temporal input context on the sample level is difficult, but required for high quality separation results because of long-range temporal correlations. In this context, we propose the Wave-U-Net, an adaptation of the U-Net to the one-dimensional time domain, which repeatedly resamples feature maps to compute and combine features at different time scales. We introduce further architectural improvements, including an output layer that enforces source additivity, an upsampling technique and a context-aware prediction framework to reduce output artifacts. Experiments for singing voice separation indicate that our architecture yields a performance comparable to a state-of-the-art spectrogram-based U-Net architecture, given the same data. Finally, we reveal a problem with outliers in the currently used SDR evaluation metrics and suggest reporting rank-based statistics to alleviate this problem.
* 7 pages (1 for references), 4 figures, 3 tables. Appearing in the proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR 2018) (camera-ready version). Implementation available at https://github.com/f90/Wave-U-Net
Adversarial Semi-Supervised Audio Source Separation applied to Singing Voice Extraction
Apr 06, 2018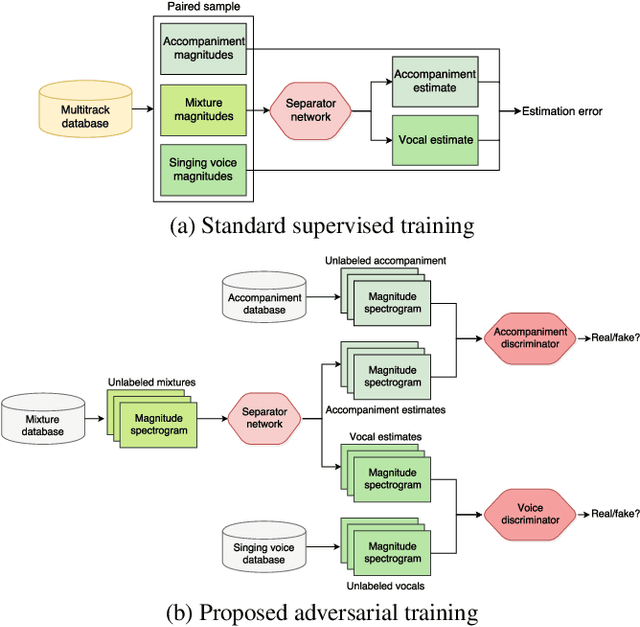


The state of the art in music source separation employs neural networks trained in a supervised fashion on multi-track databases to estimate the sources from a given mixture. With only few datasets available, often extensive data augmentation is used to combat overfitting. Mixing random tracks, however, can even reduce separation performance as instruments in real music are strongly correlated. The key concept in our approach is that source estimates of an optimal separator should be indistinguishable from real source signals. Based on this idea, we drive the separator towards outputs deemed as realistic by discriminator networks that are trained to tell apart real from separator samples. This way, we can also use unpaired source and mixture recordings without the drawbacks of creating unrealistic music mixtures. Our framework is widely applicable as it does not assume a specific network architecture or number of sources. To our knowledge, this is the first adoption of adversarial training for music source separation. In a prototype experiment for singing voice separation, separation performance increases with our approach compared to purely supervised training.
Jointly Detecting and Separating Singing Voice: A Multi-Task Approach
Apr 05, 2018

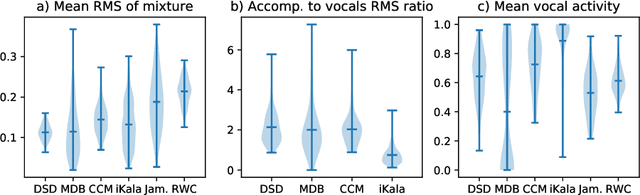
A main challenge in applying deep learning to music processing is the availability of training data. One potential solution is Multi-task Learning, in which the model also learns to solve related auxiliary tasks on additional datasets to exploit their correlation. While intuitive in principle, it can be challenging to identify related tasks and construct the model to optimally share information between tasks. In this paper, we explore vocal activity detection as an additional task to stabilise and improve the performance of vocal separation. Further, we identify problematic biases specific to each dataset that could limit the generalisation capability of separation and detection models, to which our proposed approach is robust. Experiments show improved performance in separation as well as vocal detection compared to single-task baselines. However, we find that the commonly used Signal-to-Distortion Ratio (SDR) metrics did not capture the improvement on non-vocal sections, indicating the need for improved evaluation methodologies.