 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Generative Adversarial Networks from Incomplete Observations using Factorised Discriminators
Paper and Code
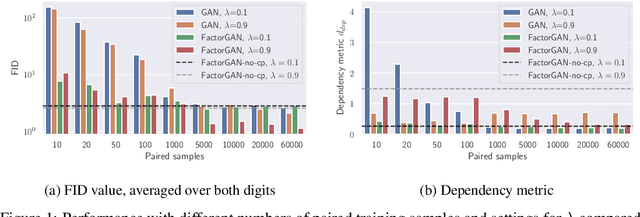

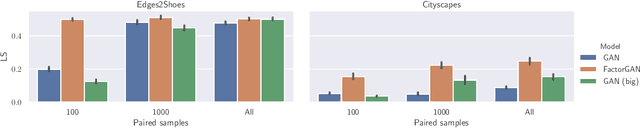

Generative adversarial networks (GANs) have shown great success in applications such as image generation and inpainting. To stabilize the challenging training process, one typically requires large datasets - which are not available for many tasks. Large amounts of additionally available incomplete observations could be exploited in many cases, but it remains unclear how to train a GAN in such a setting. To address this shortcoming, we factorise the high-dimensional joint distribution of the complete data into a set of lower-dimensional distributions along with their dependencies. As a consequence, we can split the discriminator in a GAN into multiple "sub-discriminators" that can be independently trained from incomplete observations. Their outputs can be combined to obtain an estimate of the density ratio between the joint real and the generator distribution, which enables training the generator as in the original GAN framework. As an additional benefit, our modularisation facilitates incorporating prior knowledge into the discriminator architecture. We apply our method to image generation, image segmentation and audio source separation, and show an improved performance compared to a standard GAN when additional incomplete training examples are available.