 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Musical Source Separation
Paper and Code
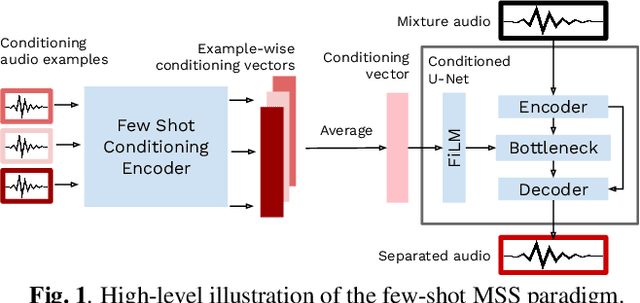
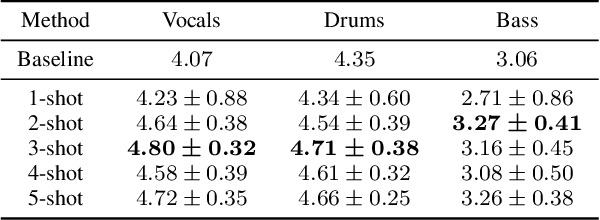
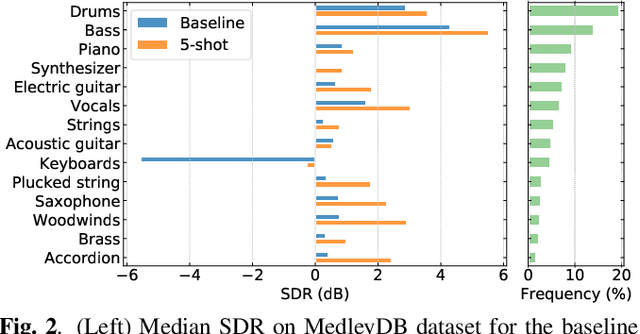

Deep learning-based approaches to musical source separation are often limited to the instrument classes that the models are trained on and do not generalize to separate unseen instruments. To address this, we propose a few-shot musical source separation paradigm. We condition a generic U-Net source separation model using few audio examples of the target instrument. We train a few-shot conditioning encoder jointly with the U-Net to encode the audio examples into a conditioning vector to configure the U-Net via feature-wise linear modulation (FiLM). We evaluate the trained models on real musical recordings in the MUSDB18 and MedleyDB datasets. We show that our proposed few-shot conditioning paradigm outperforms the baseline one-hot instrument-class conditioned model for both seen and unseen instruments. To extend the scope of our approach to a wider variety of real-world scenarios, we also experiment with different conditioning example characteristics, including examples from different recordings, with multiple sources, or negative conditioning examples.