 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-View Learning for Disentangled Music Audio Representations
Nov 05, 2024Self-supervised learning (SSL) offers a powerful way to learn robust, generalizable representations without labeled data. In music, where labeled data is scarce, existing SSL methods typically use generated supervision and multi-view redundancy to create pretext tasks. However, these approaches often produce entangled representations and lose view-specific information. We propose a novel self-supervised multi-view learning framework for audio designed to incentivize separation between private and shared representation spaces. A case study on audio disentanglement in a controlled setting demonstrates the effectiveness of our method.
Two vs. Four-Channel Sound Event Localization and Detection
Sep 23, 2023Sound event localization and detection (SELD) systems estimate both the direction-of-arrival (DOA) and class of sound sources over time. In the DCASE 2022 SELD Challenge (Task 3), models are designed to operate in a 4-channel setting. While beneficial to further the development of SELD systems using a multichannel recording setup such as first-order Ambisonics (FOA), most consumer electronics devices rarely are able to record using more than two channels. For this reason, in this work we investigate the performance of the DCASE 2022 SELD baseline model using three audio input representations: FOA, binaural, and stereo. We perform a novel comparative analysis illustrating the effect of these audio input representations on SELD performance. Crucially, we show that binaural and stereo (i.e. 2-channel) audio-based SELD models are still able to localize and detect sound sources laterally quite well, despite overall performance degrading as less audio information is provided. Further, we segment our analysis by scenes containing varying degrees of sound source polyphony to better understand the effect of audio input representation on localization and detection performance as scene conditions become increasingly complex.
Sound Source Distance Estimation in Diverse and Dynamic Acoustic Conditions
Sep 17, 2023



Localizing a moving sound source in the real world involves determining its direction-of-arrival (DOA) and distance relative to a microphone. Advancements in DOA estimation have been facilitated by data-driven methods optimized with large open-source datasets with microphone array recordings in diverse environments. In contrast, estimating a sound source's distance remains understudied. Existing approaches assume recordings by non-coincident microphones to use methods that are susceptible to differences in room reverberation. We present a CRNN able to estimate the distance of moving sound sources across multiple datasets featuring diverse rooms, outperforming a recently-published approach. We also characterize our model's performance as a function of sound source distance and different training losses. This analysis reveals optimal training using a loss that weighs model errors as an inverse function of the sound source true distance. Our study is the first to demonstrate that sound source distance estimation can be performed across diverse acoustic conditions using deep learning.
Bridging High-Quality Audio and Video via Language for Sound Effects Retrieval from Visual Queries
Aug 17, 2023
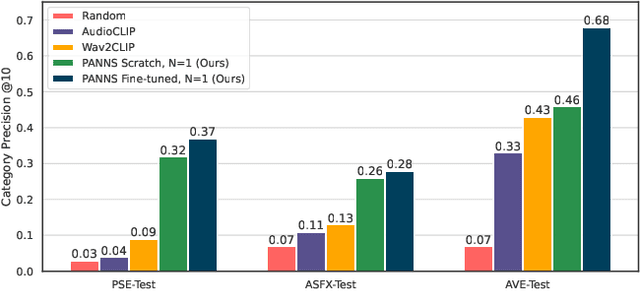
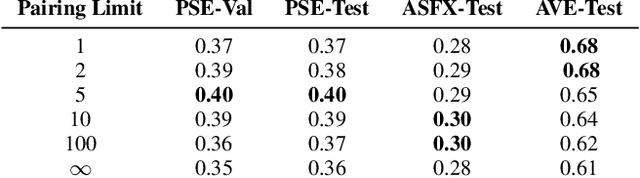
Finding the right sound effects (SFX) to match moments in a video is a difficult and time-consuming task, and relies heavily on the quality and completeness of text metadata. Retrieving high-quality (HQ) SFX using a video frame directly as the query is an attractive alternative, removing the reliance on text metadata and providing a low barrier to entry for non-experts. Due to the lack of HQ audio-visual training data, previous work on audio-visual retrieval relies on YouTube (in-the-wild) videos of varied quality for training, where the audio is often noisy and the video of amateur quality. As such it is unclear whether these systems would generalize to the task of matching HQ audio to production-quality video. To address this, we propose a multimodal framework for recommending HQ SFX given a video frame by (1) leveraging large language models and foundational vision-language models to bridge HQ audio and video to create audio-visual pairs, resulting in a highly scalable automatic audio-visual data curation pipeline; and (2) using pre-trained audio and visual encoders to train a contrastive learning-based retrieval system. We show that our system, trained using our automatic data curation pipeline, significantly outperforms baselines trained on in-the-wild data on the task of HQ SFX retrieval for video. Furthermore, while the baselines fail to generalize to this task, our system generalizes well from clean to in-the-wild data, outperforming the baselines on a dataset of YouTube videos despite only being trained on the HQ audio-visual pairs. A user study confirms that people prefer SFX retrieved by our system over the baseline 67% of the time both for HQ and in-the-wild data. Finally, we present ablations to determine the impact of model and data pipeline design choices on downstream retrieval performance. Please visit our project website to listen to and view our SFX retrieval results.
Audio-Text Models Do Not Yet Leverage Natural Language
Mar 19, 2023Multi-modal contrastive learning techniques in the audio-text domain have quickly become a highly active area of research. Most works are evaluated with standard audio retrieval and classification benchmarks assuming that (i) these models are capable of leveraging the rich information contained in natural language, and (ii) current benchmarks are able to capture the nuances of such information. In this work, we show that state-of-the-art audio-text models do not yet really understand natural language, especially contextual concepts such as sequential or concurrent ordering of sound events. Our results suggest that existing benchmarks are not sufficient to assess these models' capabilities to match complex contexts from the audio and text modalities. We propose a Transformer-based architecture and show that, unlike prior work, it is capable of modeling the sequential relationship between sound events in the text and audio, given appropriate benchmark data. We advocate for the collection or generation of additional, diverse, data to allow future research to fully leverage natural language for audio-text modeling.
FlowGrad: Using Motion for Visual Sound Source Localization
Nov 15, 2022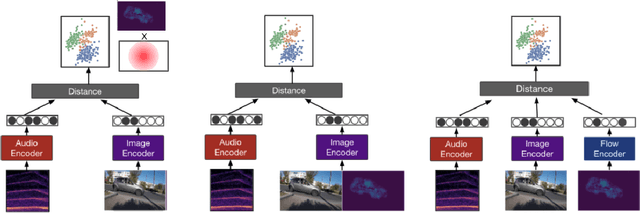
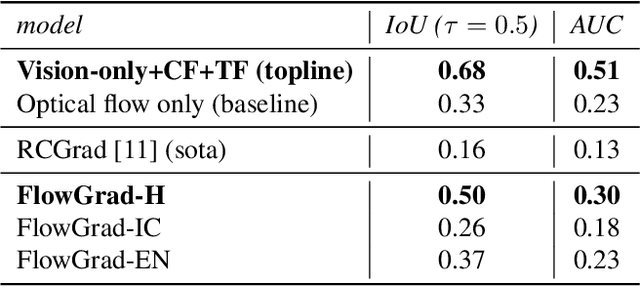
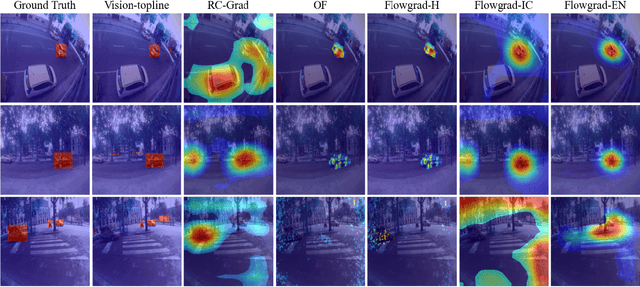
Most recent work in visual sound source localization relies on semantic audio-visual representations learned in a self-supervised manner, and by design excludes temporal information present in videos. While it proves to be effective for widely used benchmark datasets, the method falls short for challenging scenarios like urban traffic. This work introduces temporal context into the state-of-the-art methods for sound source localization in urban scenes using optical flow as a means to encode motion information. An analysis of the strengths and weaknesses of our methods helps us better understand the problem of visual sound source localization and sheds light on open challenges for audio-visual scene understanding.
Few-Shot Musical Source Separation
May 03, 2022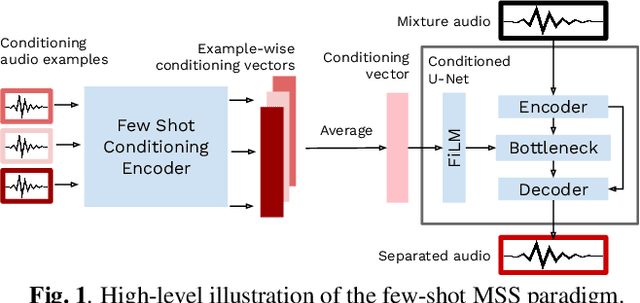
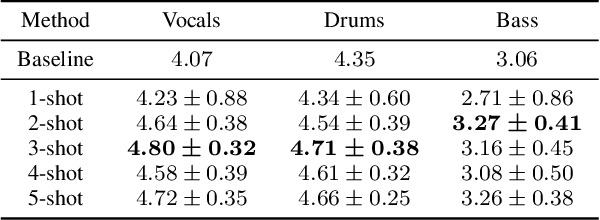
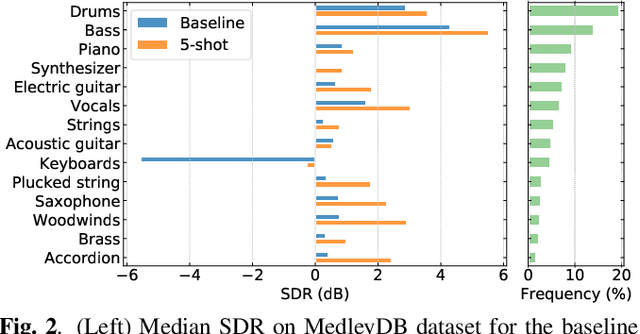

Deep learning-based approaches to musical source separation are often limited to the instrument classes that the models are trained on and do not generalize to separate unseen instruments. To address this, we propose a few-shot musical source separation paradigm. We condition a generic U-Net source separation model using few audio examples of the target instrument. We train a few-shot conditioning encoder jointly with the U-Net to encode the audio examples into a conditioning vector to configure the U-Net via feature-wise linear modulation (FiLM). We evaluate the trained models on real musical recordings in the MUSDB18 and MedleyDB datasets. We show that our proposed few-shot conditioning paradigm outperforms the baseline one-hot instrument-class conditioned model for both seen and unseen instruments. To extend the scope of our approach to a wider variety of real-world scenarios, we also experiment with different conditioning example characteristics, including examples from different recordings, with multiple sources, or negative conditioning examples.
How to Listen? Rethinking Visual Sound Localization
Apr 11, 2022
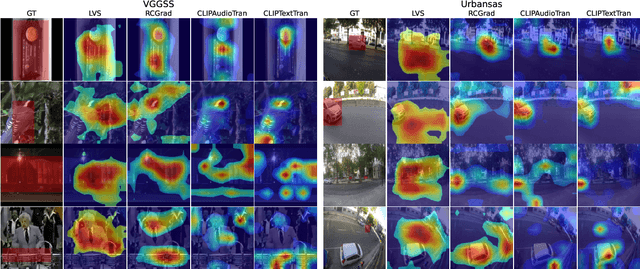

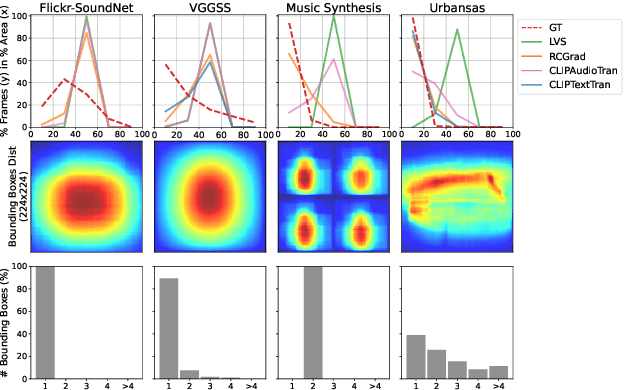
Localizing visual sounds consists on locating the position of objects that emit sound within an image. It is a growing research area with potential applications in monitoring natural and urban environments, such as wildlife migration and urban traffic. Previous works are usually evaluated with datasets having mostly a single dominant visible object, and proposed models usually require the introduction of localization modules during training or dedicated sampling strategies, but it remains unclear how these design choices play a role in the adaptability of these methods in more challenging scenarios. In this work, we analyze various model choices for visual sound localization and discuss how their different components affect the model's performance, namely the encoders' architecture, the loss function and the localization strategy. Furthermore, we study the interaction between these decisions, the model performance, and the data, by digging into different evaluation datasets spanning different difficulties and characteristics, and discuss the implications of such decisions in the context of real-world applications. Our code and model weights are open-sourced and made available for further applications.
A Study on Robustness to Perturbations for Representations of Environmental Sound
Mar 23, 2022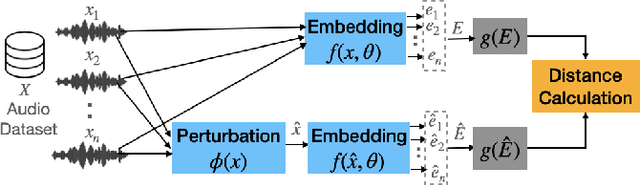
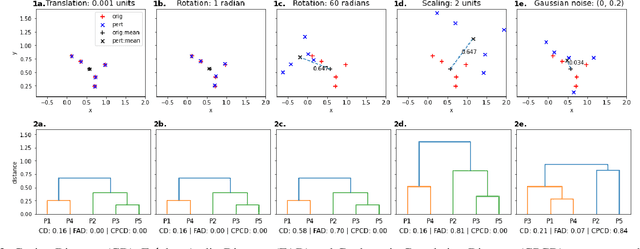
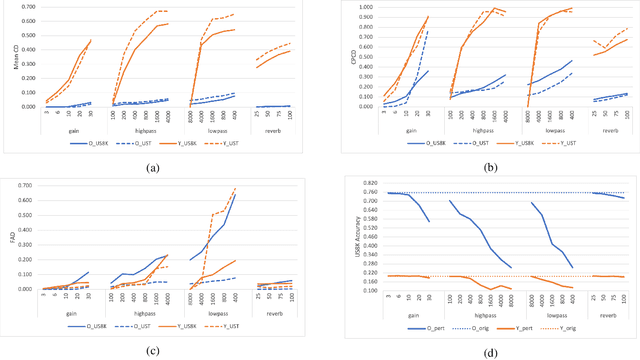
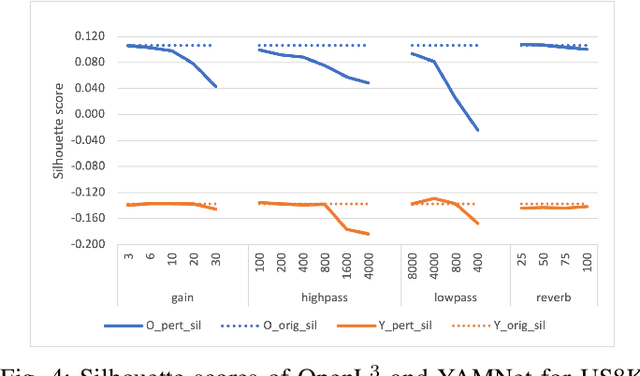
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.
Infrastructure-free, Deep Learned Urban Noise Monitoring at $\sim$100mW
Mar 11, 2022
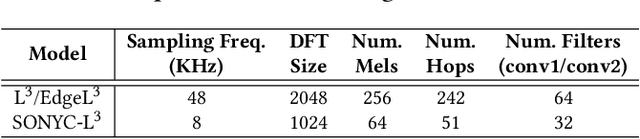
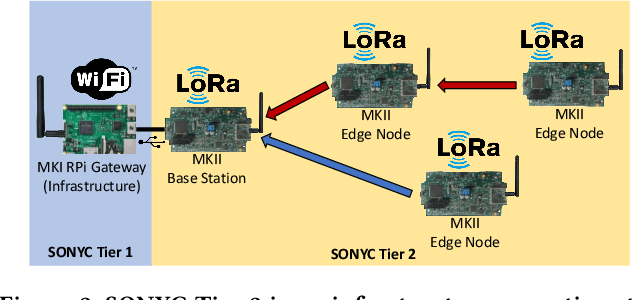
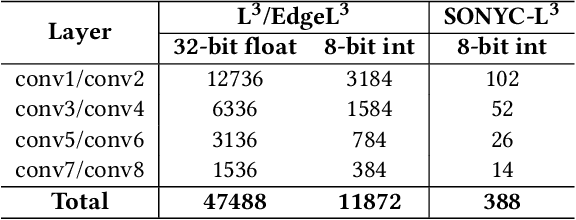
The Sounds of New York City (SONYC) wireless sensor network (WSN) has been fielded in Manhattan and Brooklyn over the past five years, as part of a larger human-in-the-loop cyber-physical control system for monitoring, analyzing, and mitigating urban noise pollution. We describe the evolution of the 2-tier SONYC WSN from an acoustic data collection fabric into a 3-tier in situ noise complaint monitoring WSN, and its current evaluation. The added tier consists of long-range (LoRa), multi-hop networks of a new low-power acoustic mote, MKII ("Mach 2"), that we have designed and fabricated. MKII motes are notable in three ways: First, they advance machine learning capability at mote-scale in this application domain by introducing a real-time Convolutional Neural Network (CNN) based embedding model that is competitive with alternatives while also requiring 10$\times$ lesser training data and $\sim$2 orders of magnitude fewer runtime resources. Second, they are conveniently deployed relatively far from higher-tier base station nodes without assuming power or network infrastructure support at operationally relevant sites (such as construction zones), yielding a relatively low-cost solution. And third, their networking is frequency agile, unlike conventional LoRa networks: it tolerates in a distributed, self-stabilizing way the variable external interference and link fading in the cluttered 902-928MHz ISM band urban environment by dynamically choosing good frequencies using an efficient new method that combines passive and active measurements.