 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-WIPER : Training-Free Object and Associated Effect Removal in Videos
Jan 10, 2026In this paper, we introduce Object-WIPER, a training-free framework for removing dynamic objects and their associated visual effects from videos, and inpainting them with semantically consistent and temporally coherent content. Our approach leverages a pre-trained text-to-video diffusion transformer (DiT). Given an input video, a user-provided object mask, and query tokens describing the target object and its effects, we localize relevant visual tokens via visual-text cross-attention and visual self-attention. This produces an intermediate effect mask that we fuse with the user mask to obtain a final foreground token mask to replace. We first invert the video through the DiT to obtain structured noise, then reinitialize the masked tokens with Gaussian noise while preserving background tokens. During denoising, we copy values for the background tokens saved during inversion to maintain scene fidelity. To address the lack of suitable evaluation, we introduce a new object removal metric that rewards temporal consistency among foreground tokens across consecutive frames, coherence between foreground and background tokens within each frame, and dissimilarity between the input and output foreground tokens. Experiments on DAVIS and a newly curated real-world associated effect benchmark (WIPER-Bench) show that Object-WIPER surpasses both training-based and training-free baselines in terms of the metric, achieving clean removal and temporally stable reconstruction without any retraining. Our new benchmark, source code, and pre-trained models will be publicly available.
VinTAGe: Joint Video and Text Conditioning for Holistic Audio Generation
Dec 14, 2024



Recent advances in audio generation have focused on text-to-audio (T2A) and video-to-audio (V2A) tasks. However, T2A or V2A methods cannot generate holistic sounds (onscreen and off-screen). This is because T2A cannot generate sounds aligning with onscreen objects, while V2A cannot generate semantically complete (offscreen sounds missing). In this work, we address the task of holistic audio generation: given a video and a text prompt, we aim to generate both onscreen and offscreen sounds that are temporally synchronized with the video and semantically aligned with text and video. Previous approaches for joint text and video-to-audio generation often suffer from modality bias, favoring one modality over the other. To overcome this limitation, we introduce VinTAGe, a flow-based transformer model that jointly considers text and video to guide audio generation. Our framework comprises two key components: a Visual-Text Encoder and a Joint VT-SiT model. To reduce modality bias and improve generation quality, we employ pretrained uni-modal text-to-audio and video-to-audio generation models for additional guidance. Due to the lack of appropriate benchmarks, we also introduce VinTAGe-Bench, a dataset of 636 video-text-audio pairs containing both onscreen and offscreen sounds. Our comprehensive experiments on VinTAGe-Bench demonstrate that joint text and visual interaction is necessary for holistic audio generation. Furthermore, VinTAGe achieves state-of-the-art results on the VGGSound benchmark. Our source code and pre-trained models will be released. Demo is available at: https://www.youtube.com/watch?v=QmqWhUjPkJI.
Diff-SAGe: End-to-End Spatial Audio Generation Using Diffusion Models
Oct 15, 2024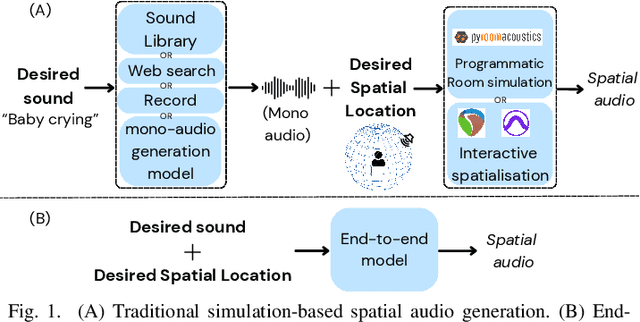
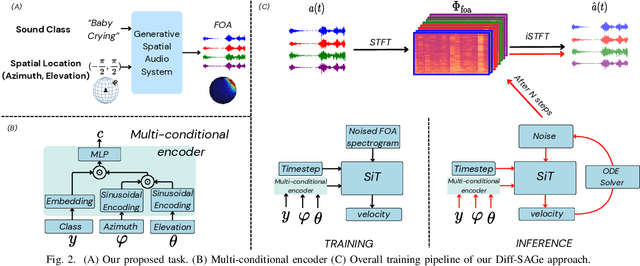
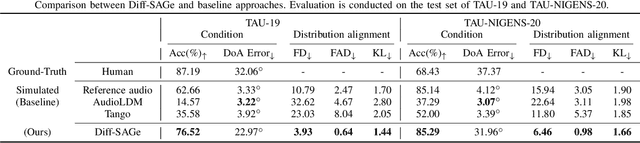
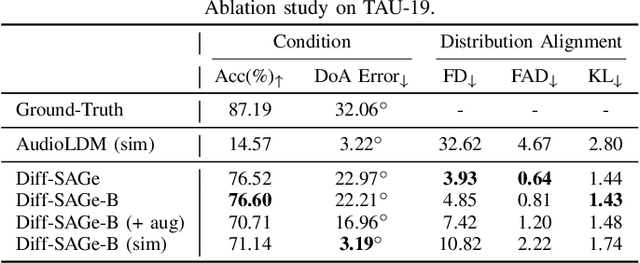
Spatial audio is a crucial component in creating immersive experiences. Traditional simulation-based approaches to generate spatial audio rely on expertise, have limited scalability, and assume independence between semantic and spatial information. To address these issues, we explore end-to-end spatial audio generation. We introduce and formulate a new task of generating first-order Ambisonics (FOA) given a sound category and sound source spatial location. We propose Diff-SAGe, an end-to-end, flow-based diffusion-transformer model for this task. Diff-SAGe utilizes a complex spectrogram representation for FOA, preserving the phase information crucial for accurate spatial cues. Additionally, a multi-conditional encoder integrates the input conditions into a unified representation, guiding the generation of FOA waveforms from noise. Through extensive evaluations on two datasets, we demonstrate that our method consistently outperforms traditional simulation-based baselines across both objective and subjective metrics.
Sound Source Distance Estimation in Diverse and Dynamic Acoustic Conditions
Sep 17, 2023



Localizing a moving sound source in the real world involves determining its direction-of-arrival (DOA) and distance relative to a microphone. Advancements in DOA estimation have been facilitated by data-driven methods optimized with large open-source datasets with microphone array recordings in diverse environments. In contrast, estimating a sound source's distance remains understudied. Existing approaches assume recordings by non-coincident microphones to use methods that are susceptible to differences in room reverberation. We present a CRNN able to estimate the distance of moving sound sources across multiple datasets featuring diverse rooms, outperforming a recently-published approach. We also characterize our model's performance as a function of sound source distance and different training losses. This analysis reveals optimal training using a loss that weighs model errors as an inverse function of the sound source true distance. Our study is the first to demonstrate that sound source distance estimation can be performed across diverse acoustic conditions using deep learning.
A Multimodal Prototypical Approach for Unsupervised Sound Classification
Jun 21, 2023In the context of environmental sound classification, the adaptability of systems is key: which sound classes are interesting depends on the context and the user's needs. Recent advances in text-to-audio retrieval allow for zero-shot audio classification, but performance compared to supervised models remains limited. This work proposes a multimodal prototypical approach that exploits local audio-text embeddings to provide more relevant answers to audio queries, augmenting the adaptability of sound detection in the wild. We do this by first using text to query a nearby community of audio embeddings that best characterize each query sound, and select the group's centroids as our prototypes. Second, we compare unseen audio to these prototypes for classification. We perform multiple ablation studies to understand the impact of the embedding models and prompts. Our unsupervised approach improves upon the zero-shot state-of-the-art in three sound recognition benchmarks by an average of 12%.