 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
Learning from Silence and Noise for Visual Sound Source Localization
Aug 29, 2025Visual sound source localization is a fundamental perception task that aims to detect the location of sounding sources in a video given its audio. Despite recent progress, we identify two shortcomings in current methods: 1) most approaches perform poorly in cases with low audio-visual semantic correspondence such as silence, noise, and offscreen sounds, i.e. in the presence of negative audio; and 2) most prior evaluations are limited to positive cases, where both datasets and metrics convey scenarios with a single visible sound source in the scene. To address this, we introduce three key contributions. First, we propose a new training strategy that incorporates silence and noise, which improves performance in positive cases, while being more robust against negative sounds. Our resulting self-supervised model, SSL-SaN, achieves state-of-the-art performance compared to other self-supervised models, both in sound localization and cross-modal retrieval. Second, we propose a new metric that quantifies the trade-off between alignment and separability of auditory and visual features across positive and negative audio-visual pairs. Third, we present IS3+, an extended and improved version of the IS3 synthetic dataset with negative audio. Our data, metrics and code are available on the https://xavijuanola.github.io/SSL-SaN/.
Domain Adaptation Method and Modality Gap Impact in Audio-Text Models for Prototypical Sound Classification
Jun 04, 2025Audio-text models are widely used in zero-shot environmental sound classification as they alleviate the need for annotated data. However, we show that their performance severely drops in the presence of background sound sources. Our analysis reveals that this degradation is primarily driven by SNR levels of background soundscapes, and independent of background type. To address this, we propose a novel method that quantifies and integrates the contribution of background sources into the classification process, improving performance without requiring model retraining. Our domain adaptation technique enhances accuracy across various backgrounds and SNR conditions. Moreover, we analyze the modality gap between audio and text embeddings, showing that narrowing this gap improves classification performance. The method generalizes effectively across state-of-the-art prototypical approaches, showcasing its scalability and robustness for diverse environments.
Musical Source Separation of Brazilian Percussion
Mar 06, 2025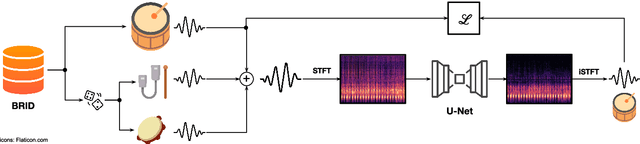
Musical source separation (MSS) has recently seen a big breakthrough in separating instruments from a mixture in the context of Western music, but research on non-Western instruments is still limited due to a lack of data. In this demo, we use an existing dataset of Brazilian sama percussion to create artificial mixtures for training a U-Net model to separate the surdo drum, a traditional instrument in samba. Despite limited training data, the model effectively isolates the surdo, given the drum's repetitive patterns and its characteristic low-pitched timbre. These results suggest that MSS systems can be successfully harnessed to work in more culturally-inclusive scenarios without the need of collecting extensive amounts of data.
Self-Supervised Multi-View Learning for Disentangled Music Audio Representations
Nov 05, 2024Self-supervised learning (SSL) offers a powerful way to learn robust, generalizable representations without labeled data. In music, where labeled data is scarce, existing SSL methods typically use generated supervision and multi-view redundancy to create pretext tasks. However, these approaches often produce entangled representations and lose view-specific information. We propose a novel self-supervised multi-view learning framework for audio designed to incentivize separation between private and shared representation spaces. A case study on audio disentanglement in a controlled setting demonstrates the effectiveness of our method.
SONIQUE: Video Background Music Generation Using Unpaired Audio-Visual Data
Oct 04, 2024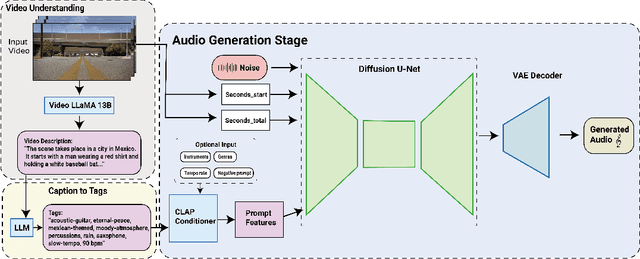
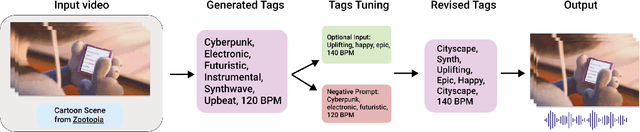

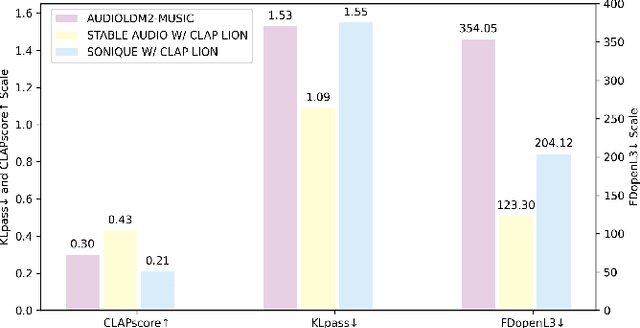
We present SONIQUE, a model for generating background music tailored to video content. Unlike traditional video-to-music generation approaches, which rely heavily on paired audio-visual datasets, SONIQUE leverages unpaired data, combining royalty-free music and independent video sources. By utilizing large language models (LLMs) for video understanding and converting visual descriptions into musical tags, alongside a U-Net-based conditional diffusion model, SONIQUE enables customizable music generation. Users can control specific aspects of the music, such as instruments, genres, tempo, and melodies, ensuring the generated output fits their creative vision. SONIQUE is open-source, with a demo available online.
A Critical Assessment of Visual Sound Source Localization Models Including Negative Audio
Oct 01, 2024The task of Visual Sound Source Localization (VSSL) involves identifying the location of sound sources in visual scenes, integrating audio-visual data for enhanced scene understanding. Despite advancements in state-of-the-art (SOTA) models, we observe three critical flaws: i) The evaluation of the models is mainly focused in sounds produced by objects that are visible in the image, ii) The evaluation often assumes a prior knowledge of the size of the sounding object, and iii) No universal threshold for localization in real-world scenarios is established, as previous approaches only consider positive examples without accounting for both positive and negative cases. In this paper, we introduce a novel test set and metrics designed to complete the current standard evaluation of VSSL models by testing them in scenarios where none of the objects in the image corresponds to the audio input, i.e. a negative audio. We consider three types of negative audio: silence, noise and offscreen. Our analysis reveals that numerous SOTA models fail to appropriately adjust their predictions based on audio input, suggesting that these models may not be leveraging audio information as intended. Additionally, we provide a comprehensive analysis of the range of maximum values in the estimated audio-visual similarity maps, in both positive and negative audio cases, and show that most of the models are not discriminative enough, making them unfit to choose a universal threshold appropriate to perform sound localization without any a priori information of the sounding object, that is, object size and visibility.
Two vs. Four-Channel Sound Event Localization and Detection
Sep 23, 2023Sound event localization and detection (SELD) systems estimate both the direction-of-arrival (DOA) and class of sound sources over time. In the DCASE 2022 SELD Challenge (Task 3), models are designed to operate in a 4-channel setting. While beneficial to further the development of SELD systems using a multichannel recording setup such as first-order Ambisonics (FOA), most consumer electronics devices rarely are able to record using more than two channels. For this reason, in this work we investigate the performance of the DCASE 2022 SELD baseline model using three audio input representations: FOA, binaural, and stereo. We perform a novel comparative analysis illustrating the effect of these audio input representations on SELD performance. Crucially, we show that binaural and stereo (i.e. 2-channel) audio-based SELD models are still able to localize and detect sound sources laterally quite well, despite overall performance degrading as less audio information is provided. Further, we segment our analysis by scenes containing varying degrees of sound source polyphony to better understand the effect of audio input representation on localization and detection performance as scene conditions become increasingly complex.
Sound Source Distance Estimation in Diverse and Dynamic Acoustic Conditions
Sep 17, 2023



Localizing a moving sound source in the real world involves determining its direction-of-arrival (DOA) and distance relative to a microphone. Advancements in DOA estimation have been facilitated by data-driven methods optimized with large open-source datasets with microphone array recordings in diverse environments. In contrast, estimating a sound source's distance remains understudied. Existing approaches assume recordings by non-coincident microphones to use methods that are susceptible to differences in room reverberation. We present a CRNN able to estimate the distance of moving sound sources across multiple datasets featuring diverse rooms, outperforming a recently-published approach. We also characterize our model's performance as a function of sound source distance and different training losses. This analysis reveals optimal training using a loss that weighs model errors as an inverse function of the sound source true distance. Our study is the first to demonstrate that sound source distance estimation can be performed across diverse acoustic conditions using deep learning.
Bridging High-Quality Audio and Video via Language for Sound Effects Retrieval from Visual Queries
Aug 17, 2023
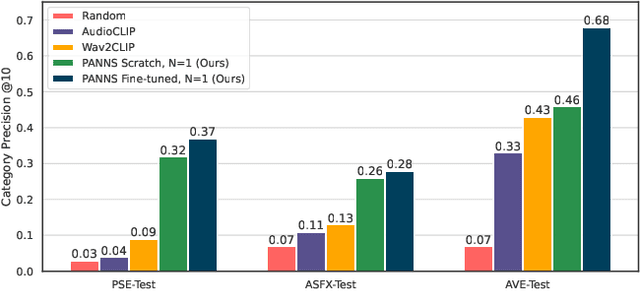
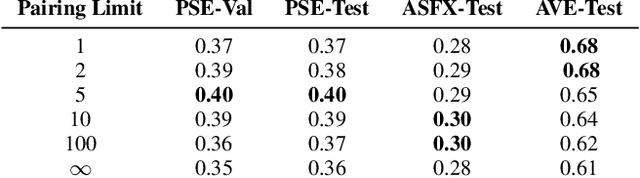
Finding the right sound effects (SFX) to match moments in a video is a difficult and time-consuming task, and relies heavily on the quality and completeness of text metadata. Retrieving high-quality (HQ) SFX using a video frame directly as the query is an attractive alternative, removing the reliance on text metadata and providing a low barrier to entry for non-experts. Due to the lack of HQ audio-visual training data, previous work on audio-visual retrieval relies on YouTube (in-the-wild) videos of varied quality for training, where the audio is often noisy and the video of amateur quality. As such it is unclear whether these systems would generalize to the task of matching HQ audio to production-quality video. To address this, we propose a multimodal framework for recommending HQ SFX given a video frame by (1) leveraging large language models and foundational vision-language models to bridge HQ audio and video to create audio-visual pairs, resulting in a highly scalable automatic audio-visual data curation pipeline; and (2) using pre-trained audio and visual encoders to train a contrastive learning-based retrieval system. We show that our system, trained using our automatic data curation pipeline, significantly outperforms baselines trained on in-the-wild data on the task of HQ SFX retrieval for video. Furthermore, while the baselines fail to generalize to this task, our system generalizes well from clean to in-the-wild data, outperforming the baselines on a dataset of YouTube videos despite only being trained on the HQ audio-visual pairs. A user study confirms that people prefer SFX retrieved by our system over the baseline 67% of the time both for HQ and in-the-wild data. Finally, we present ablations to determine the impact of model and data pipeline design choices on downstream retrieval performance. Please visit our project website to listen to and view our SFX retrieval results.