 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Disentangled Representations for Controllable Music Generation
Feb 15, 2026Recent approaches in music generation rely on disentangled representations, often labeled as structure and timbre or local and global, to enable controllable synthesis. Yet the underlying properties of these embeddings remain underexplored. In this work, we evaluate such disentangled representations in a set of music audio models for controllable generation using a probing-based framework that goes beyond standard downstream tasks. The selected models reflect diverse unsupervised disentanglement strategies, including inductive biases, data augmentations, adversarial objectives, and staged training procedures. We further isolate specific strategies to analyze their effect. Our analysis spans four key axes: informativeness, equivariance, invariance, and disentanglement, which are assessed across datasets, tasks, and controlled transformations. Our findings reveal inconsistencies between intended and actual semantics of the embeddings, suggesting that current strategies fall short of producing truly disentangled representations, and prompting a re-examination of how controllability is approached in music generation.
Domain Adaptation Method and Modality Gap Impact in Audio-Text Models for Prototypical Sound Classification
Jun 04, 2025Audio-text models are widely used in zero-shot environmental sound classification as they alleviate the need for annotated data. However, we show that their performance severely drops in the presence of background sound sources. Our analysis reveals that this degradation is primarily driven by SNR levels of background soundscapes, and independent of background type. To address this, we propose a novel method that quantifies and integrates the contribution of background sources into the classification process, improving performance without requiring model retraining. Our domain adaptation technique enhances accuracy across various backgrounds and SNR conditions. Moreover, we analyze the modality gap between audio and text embeddings, showing that narrowing this gap improves classification performance. The method generalizes effectively across state-of-the-art prototypical approaches, showcasing its scalability and robustness for diverse environments.
ChordSync: Conformer-Based Alignment of Chord Annotations to Music Audio
Aug 01, 2024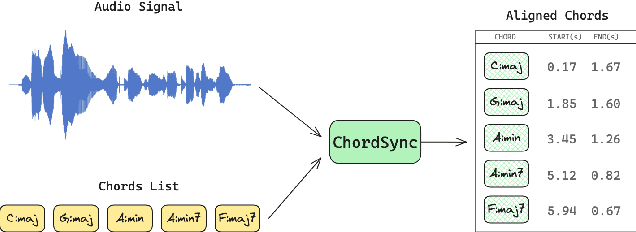
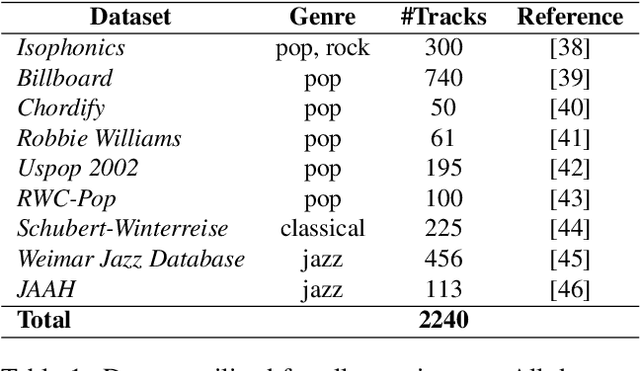
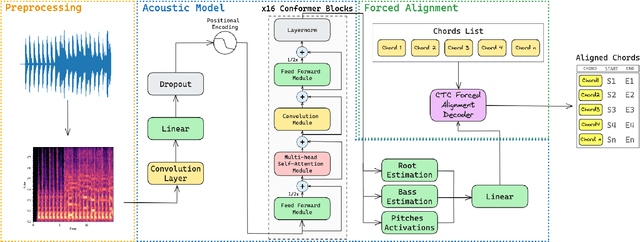
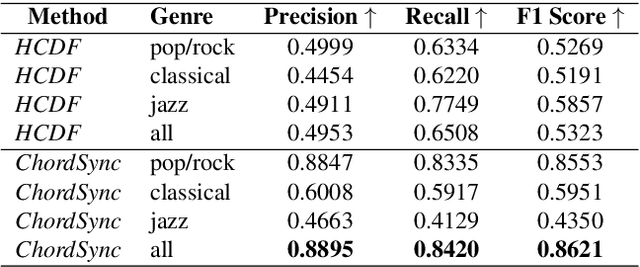
In the Western music tradition, chords are the main constituent components of harmony, a fundamental dimension of music. Despite its relevance for several Music Information Retrieval (MIR) tasks, chord-annotated audio datasets are limited and need more diversity. One way to improve those resources is to leverage the large number of chord annotations available online, but this requires aligning them with music audio. However, existing audio-to-score alignment techniques, which typically rely on Dynamic Time Warping (DTW), fail to address this challenge, as they require weakly aligned data for precise synchronisation. In this paper, we introduce ChordSync, a novel conformer-based model designed to seamlessly align chord annotations with audio, eliminating the need for weak alignment. We also provide a pre-trained model and a user-friendly library, enabling users to synchronise chord annotations with audio tracks effortlessly. In this way, ChordSync creates opportunities for harnessing crowd-sourced chord data for MIR, especially in audio chord estimation, thereby facilitating the generation of novel datasets. Additionally, our system extends its utility to music education, enhancing music learning experiences by providing accurately aligned annotations, thus enabling learners to engage in synchronised musical practices.
* 8 pages, 3 figures, 3 tables
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024


We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
Adapting Meter Tracking Models to Latin American Music
Apr 14, 2023Beat and downbeat tracking models have improved significantly in recent years with the introduction of deep learning methods. However, despite these improvements, several challenges remain. Particularly, the adaptation of available models to underrepresented music traditions in MIR is usually synonymous with collecting and annotating large amounts of data, which is impractical and time-consuming. Transfer learning, data augmentation, and fine-tuning techniques have been used quite successfully in related tasks and are known to alleviate this bottleneck. Furthermore, when studying these music traditions, models are not required to generalize to multiple mainstream music genres but to perform well in more constrained, homogeneous conditions. In this work, we investigate simple yet effective strategies to adapt beat and downbeat tracking models to two different Latin American music traditions and analyze the feasibility of these adaptations in real-world applications concerning the data and computational requirements. Contrary to common belief, our findings show it is possible to achieve good performance by spending just a few minutes annotating a portion of the data and training a model in a standard CPU machine, with the precise amount of resources needed depending on the task and the complexity of the dataset.
Soundata: A Python library for reproducible use of audio datasets
Oct 04, 2021Soundata is a Python library for loading and working with audio datasets in a standardized way, removing the need for writing custom loaders in every project, and improving reproducibility by providing tools to validate data against a canonical version. It speeds up research pipelines by allowing users to quickly download a dataset, load it into memory in a standardized and reproducible way, validate that the dataset is complete and correct, and more. Soundata is based and inspired on mirdata and design to complement mirdata by working with environmental sound, bioacoustic and speech datasets, among others. Soundata was created to be easy to use, easy to contribute to, and to increase reproducibility and standardize usage of sound datasets in a flexible way.