 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Music Autotagging with MGPHot Expert Annotations vs. Generic Tag Datasets
Sep 08, 2025



Music autotagging aims to automatically assign descriptive tags, such as genre, mood, or instrumentation, to audio recordings. Due to its challenges, diversity of semantic descriptions, and practical value in various applications, it has become a common downstream task for evaluating the performance of general-purpose music representations learned from audio data. We introduce a new benchmarking dataset based on the recently published MGPHot dataset, which includes expert musicological annotations, allowing for additional insights and comparisons with results obtained on common generic tag datasets. While MGPHot annotations have been shown to be useful for computational musicology, the original dataset neither includes audio nor provides evaluation setups for its use as a standardized autotagging benchmark. To address this, we provide a curated set of YouTube URLs with retrievable audio, and propose a train/val/test split for standardized evaluation, and precomputed representations for seven state-of-the-art models. Using these resources, we evaluated these models in MGPHot and standard reference tag datasets, highlighting key differences between expert and generic tag annotations. Altogether, our contributions provide a more advanced benchmarking framework for future research in music understanding.
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024


We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
mir_ref: A Representation Evaluation Framework for Music Information Retrieval Tasks
Dec 12, 2023


Music Information Retrieval (MIR) research is increasingly leveraging representation learning to obtain more compact, powerful music audio representations for various downstream MIR tasks. However, current representation evaluation methods are fragmented due to discrepancies in audio and label preprocessing, downstream model and metric implementations, data availability, and computational resources, often leading to inconsistent and limited results. In this work, we introduce mir_ref, an MIR Representation Evaluation Framework focused on seamless, transparent, local-first experiment orchestration to support representation development. It features implementations of a variety of components such as MIR datasets, tasks, embedding models, and tools for result analysis and visualization, while facilitating the implementation of custom components. To demonstrate its utility, we use it to conduct an extensive evaluation of several embedding models across various tasks and datasets, including evaluating their robustness to various audio perturbations and the ease of extracting relevant information from them.
Efficient Supervised Training of Audio Transformers for Music Representation Learning
Sep 28, 2023



In this work, we address music representation learning using convolution-free transformers. We build on top of existing spectrogram-based audio transformers such as AST and train our models on a supervised task using patchout training similar to PaSST. In contrast to previous works, we study how specific design decisions affect downstream music tagging tasks instead of focusing on the training task. We assess the impact of initializing the models with different pre-trained weights, using various input audio segment lengths, using learned representations from different blocks and tokens of the transformer for downstream tasks, and applying patchout at inference to speed up feature extraction. We find that 1) initializing the model from ImageNet or AudioSet weights and using longer input segments are beneficial both for the training and downstream tasks, 2) the best representations for the considered downstream tasks are located in the middle blocks of the transformer, and 3) using patchout at inference allows faster processing than our convolutional baselines while maintaining superior performance. The resulting models, MAEST, are publicly available and obtain the best performance among open models in music tagging tasks.
Pre-Training Strategies Using Contrastive Learning and Playlist Information for Music Classification and Similarity
Apr 24, 2023



In this work, we investigate an approach that relies on contrastive learning and music metadata as a weak source of supervision to train music representation models. Recent studies show that contrastive learning can be used with editorial metadata (e.g., artist or album name) to learn audio representations that are useful for different classification tasks. In this paper, we extend this idea to using playlist data as a source of music similarity information and investigate three approaches to generate anchor and positive track pairs. We evaluate these approaches by fine-tuning the pre-trained models for music multi-label classification tasks (genre, mood, and instrument tagging) and music similarity. We find that creating anchor and positive track pairs by relying on co-occurrences in playlists provides better music similarity and competitive classification results compared to choosing tracks from the same artist as in previous works. Additionally, our best pre-training approach based on playlists provides superior classification performance for most datasets.
Multilabel Prototype Generation for Data Reduction in k-Nearest Neighbour classification
Jul 22, 2022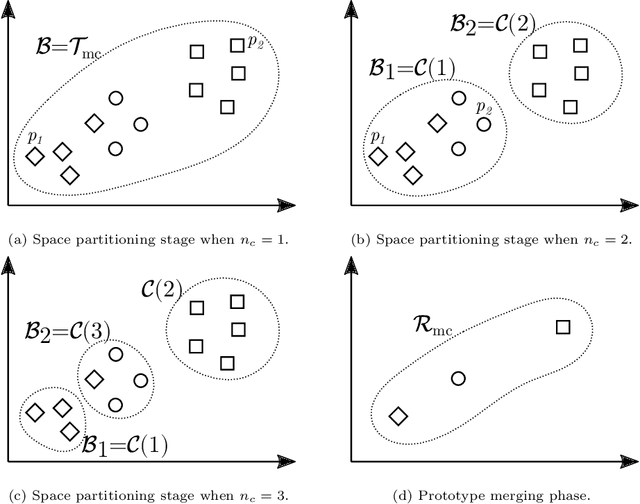
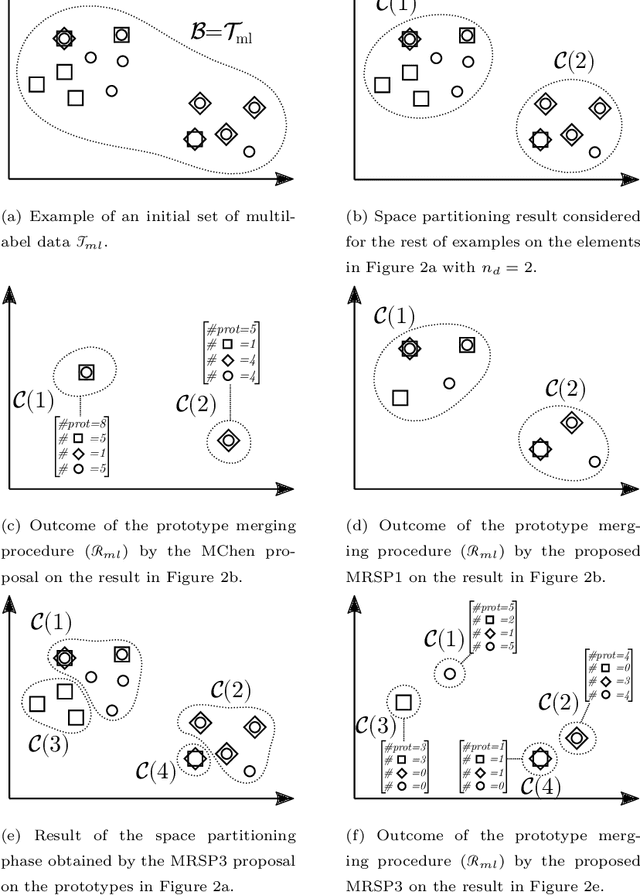
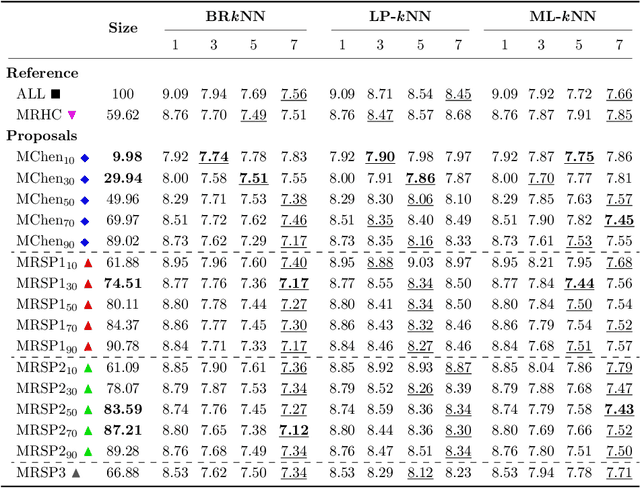
Prototype Generation (PG) methods are typically considered for improving the efficiency of the $k$-Nearest Neighbour ($k$NN) classifier when tackling high-size corpora. Such approaches aim at generating a reduced version of the corpus without decreasing the classification performance when compared to the initial set. Despite their large application in multiclass scenarios, very few works have addressed the proposal of PG methods for the multilabel space. In this regard, this work presents the novel adaptation of four multiclass PG strategies to the multilabel case. These proposals are evaluated with three multilabel $k$NN-based classifiers, 12 corpora comprising a varied range of domains and corpus sizes, and different noise scenarios artificially induced in the data. The results obtained show that the proposed adaptations are capable of significantly improving -- both in terms of efficiency and classification performance -- the only reference multilabel PG work in the literature as well as the case in which no PG method is applied, also presenting a statistically superior robustness in noisy scenarios. Moreover, these novel PG strategies allow prioritising either the efficiency or efficacy criteria through its configuration depending on the target scenario, hence covering a wide area in the solution space not previously filled by other works.
TensorFlow Audio Models in Essentia
Mar 16, 2020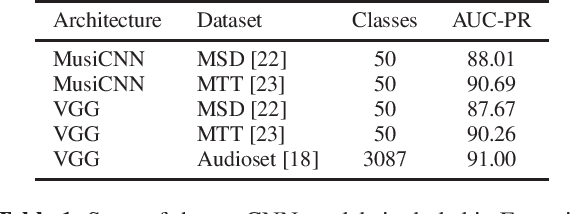
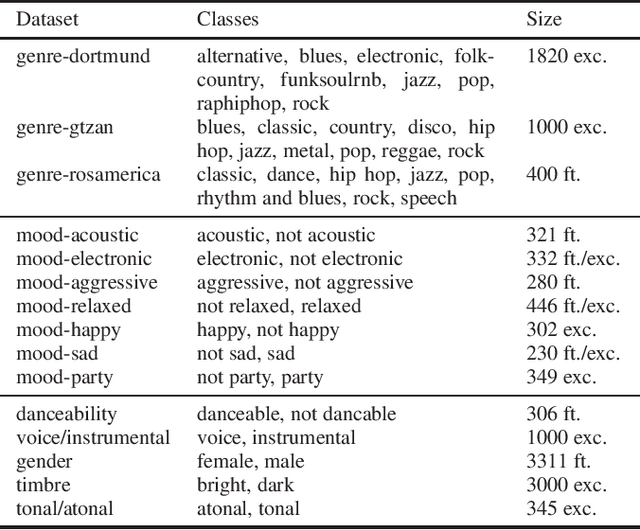

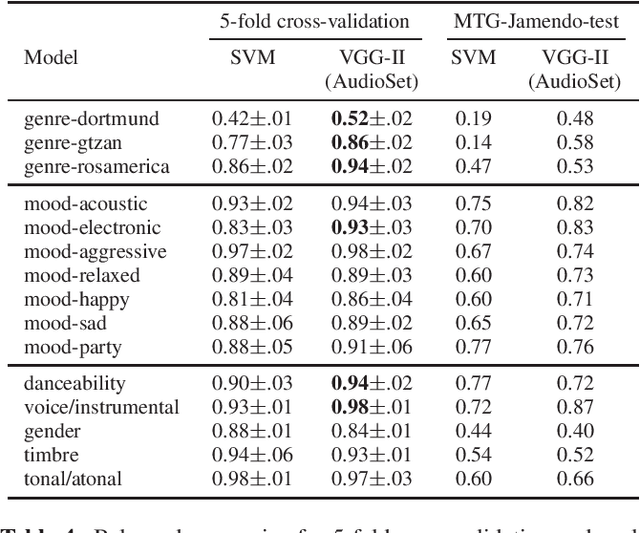
Essentia is a reference open-source C++/Python library for audio and music analysis. In this work, we present a set of algorithms that employ TensorFlow in Essentia, allow predictions with pre-trained deep learning models, and are designed to offer flexibility of use, easy extensibility, and real-time inference. To show the potential of this new interface with TensorFlow, we provide a number of pre-trained state-of-the-art music tagging and classification CNN models. We run an extensive evaluation of the developed models. In particular, we assess the generalization capabilities in a cross-collection evaluation utilizing both external tag datasets as well as manual annotations tailored to the taxonomies of our models.