 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaritime Search and Rescue Missions with Aerial Images: A Survey
Nov 12, 2024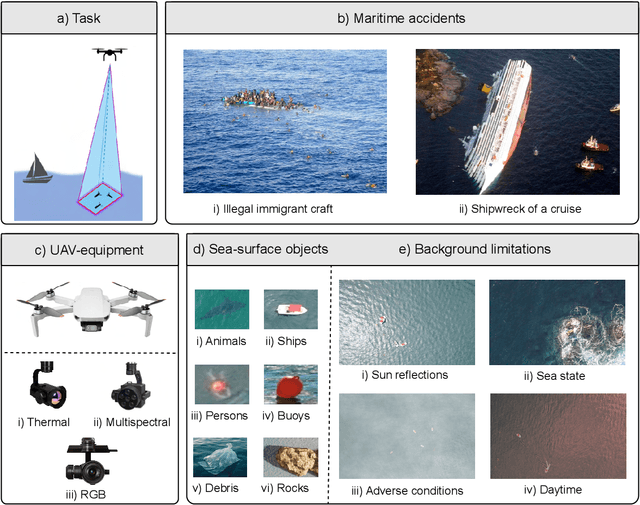
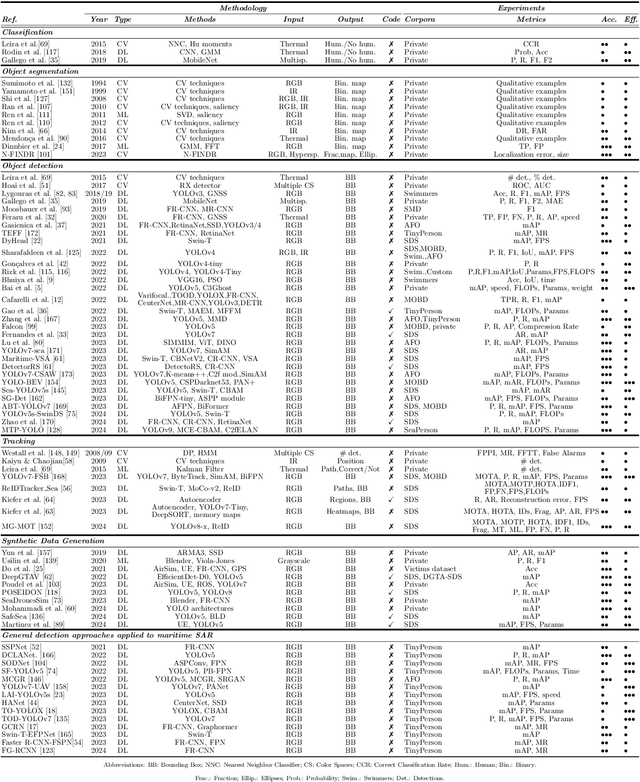
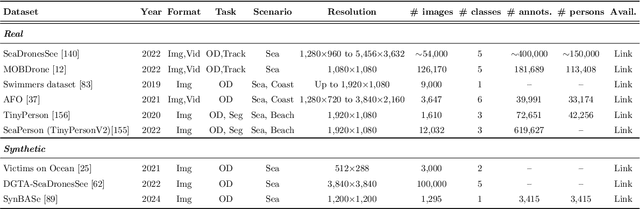
The speed of response by search and rescue teams at sea is of vital importance, as survival may depend on it. Recent technological advancements have led to the development of more efficient systems for locating individuals involved in a maritime incident, such as the use of Unmanned Aerial Vehicles (UAVs) equipped with cameras and other integrated sensors. Over the past decade, several researchers have contributed to the development of automatic systems capable of detecting people using aerial images, particularly by leveraging the advantages of deep learning. In this article, we provide a comprehensive review of the existing literature on this topic. We analyze the methods proposed to date, including both traditional techniques and more advanced approaches based on machine learning and neural networks. Additionally, we take into account the use of synthetic data to cover a wider range of scenarios without the need to deploy a team to collect data, which is one of the major obstacles for these systems. Overall, this paper situates the reader in the field of detecting people at sea using aerial images by quickly identifying the most suitable methodology for each scenario, as well as providing an in-depth discussion and direction for future trends.
Global Point Cloud Registration Network for Large Transformations
Mar 26, 2024Three-dimensional data registration is an established yet challenging problem that is key in many different applications, such as mapping the environment for autonomous vehicles, and modeling objects and people for avatar creation, among many others. Registration refers to the process of mapping multiple data into the same coordinate system by means of matching correspondences and transformation estimation. Novel proposals exploit the benefits of deep learning architectures for this purpose, as they learn the best features for the data, providing better matches and hence results. However, the state of the art is usually focused on cases of relatively small transformations, although in certain applications and in a real and practical environment, large transformations are very common. In this paper, we present ReLaTo (Registration for Large Transformations), an architecture that faces the cases where large transformations happen while maintaining good performance for local transformations. This proposal uses a novel Softmax pooling layer to find correspondences in a bilateral consensus manner between two point sets, sampling the most confident matches. These matches are used to estimate a coarse and global registration using weighted Singular Value Decomposition (SVD). A target-guided denoising step is then applied to both the obtained matches and latent features, estimating the final fine registration considering the local geometry. All these steps are carried out following an end-to-end approach, which has been shown to improve 10 state-of-the-art registration methods in two datasets commonly used for this task (ModelNet40 and KITTI), especially in the case of large transformations.
Identifying Student Profiles Within Online Judge Systems Using Explainable Artificial Intelligence
Jan 29, 2024



Online Judge (OJ) systems are typically considered within programming-related courses as they yield fast and objective assessments of the code developed by the students. Such an evaluation generally provides a single decision based on a rubric, most commonly whether the submission successfully accomplished the assignment. Nevertheless, since in an educational context such information may be deemed insufficient, it would be beneficial for both the student and the instructor to receive additional feedback about the overall development of the task. This work aims to tackle this limitation by considering the further exploitation of the information gathered by the OJ and automatically inferring feedback for both the student and the instructor. More precisely, we consider the use of learning-based schemes -- particularly, multi-instance learning (MIL) and classical machine learning formulations -- to model student behavior. Besides, explainable artificial intelligence (XAI) is contemplated to provide human-understandable feedback. The proposal has been evaluated considering a case of study comprising 2500 submissions from roughly 90 different students from a programming-related course in a computer science degree. The results obtained validate the proposal: The model is capable of significantly predicting the user outcome (either passing or failing the assignment) solely based on the behavioral pattern inferred by the submissions provided to the OJ. Moreover, the proposal is able to identify prone-to-fail student groups and profiles as well as other relevant information, which eventually serves as feedback to both the student and the instructor.
Few-shot learning for COVID-19 Chest X-Ray Classification with Imbalanced Data: An Inter vs. Intra Domain Study
Jan 18, 2024Medical image datasets are essential for training models used in computer-aided diagnosis, treatment planning, and medical research. However, some challenges are associated with these datasets, including variability in data distribution, data scarcity, and transfer learning issues when using models pre-trained from generic images. This work studies the effect of these challenges at the intra- and inter-domain level in few-shot learning scenarios with severe data imbalance. For this, we propose a methodology based on Siamese neural networks in which a series of techniques are integrated to mitigate the effects of data scarcity and distribution imbalance. Specifically, different initialization and data augmentation methods are analyzed, and four adaptations to Siamese networks of solutions to deal with imbalanced data are introduced, including data balancing and weighted loss, both separately and combined, and with a different balance of pairing ratios. Moreover, we also assess the inference process considering four classifiers, namely Histogram, $k$NN, SVM, and Random Forest. Evaluation is performed on three chest X-ray datasets with annotated cases of both positive and negative COVID-19 diagnoses. The accuracy of each technique proposed for the Siamese architecture is analyzed separately and their results are compared to those obtained using equivalent methods on a state-of-the-art CNN. We conclude that the introduced techniques offer promising improvements over the baseline in almost all cases, and that the selection of the technique may vary depending on the amount of data available and the level of imbalance.
Multilabel Prototype Generation for Data Reduction in k-Nearest Neighbour classification
Jul 22, 2022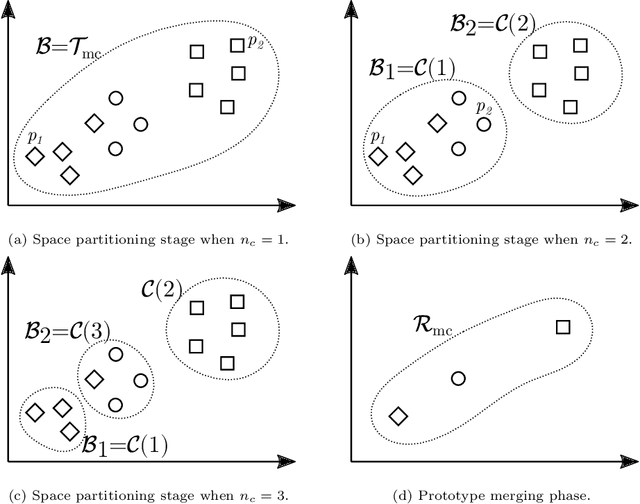
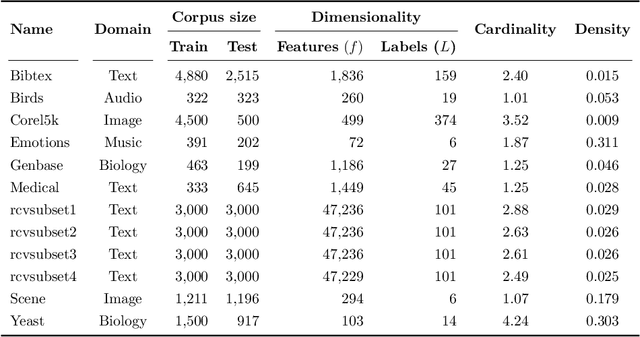
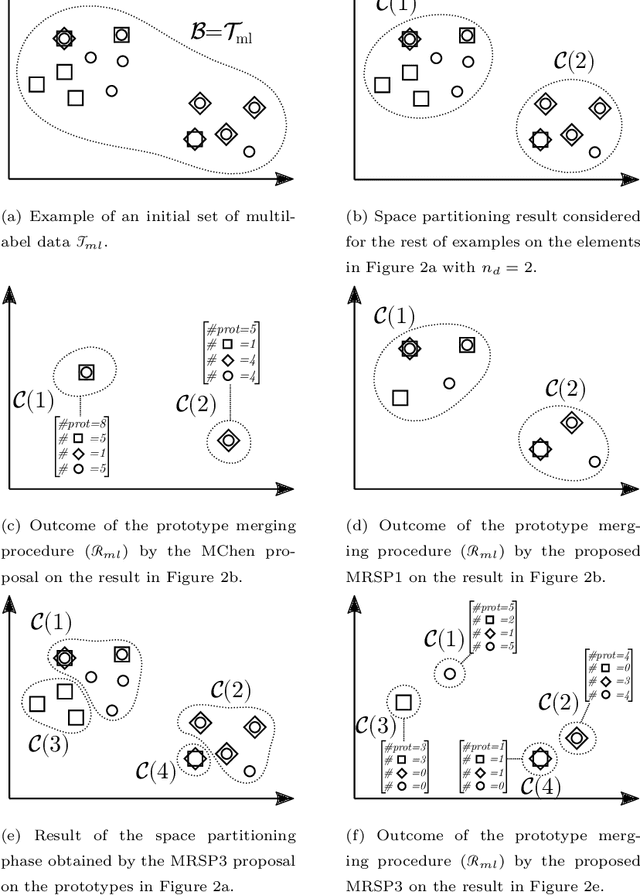
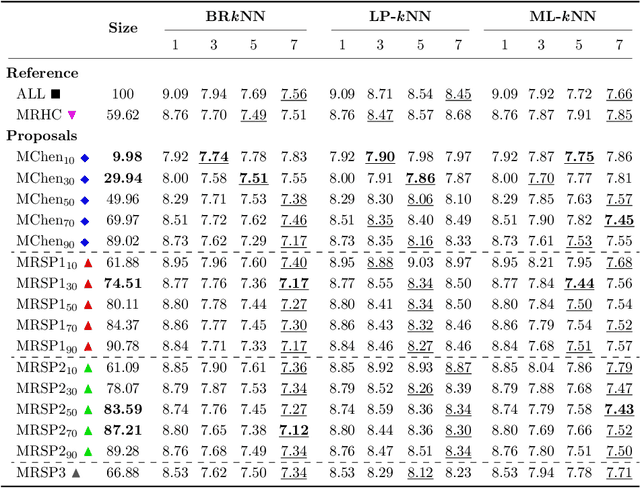
Prototype Generation (PG) methods are typically considered for improving the efficiency of the $k$-Nearest Neighbour ($k$NN) classifier when tackling high-size corpora. Such approaches aim at generating a reduced version of the corpus without decreasing the classification performance when compared to the initial set. Despite their large application in multiclass scenarios, very few works have addressed the proposal of PG methods for the multilabel space. In this regard, this work presents the novel adaptation of four multiclass PG strategies to the multilabel case. These proposals are evaluated with three multilabel $k$NN-based classifiers, 12 corpora comprising a varied range of domains and corpus sizes, and different noise scenarios artificially induced in the data. The results obtained show that the proposed adaptations are capable of significantly improving -- both in terms of efficiency and classification performance -- the only reference multilabel PG work in the literature as well as the case in which no PG method is applied, also presenting a statistically superior robustness in noisy scenarios. Moreover, these novel PG strategies allow prioritising either the efficiency or efficacy criteria through its configuration depending on the target scenario, hence covering a wide area in the solution space not previously filled by other works.
Efficient Gesture Recognition for the Assistance of Visually Impaired People using Multi-Head Neural Networks
May 14, 2022
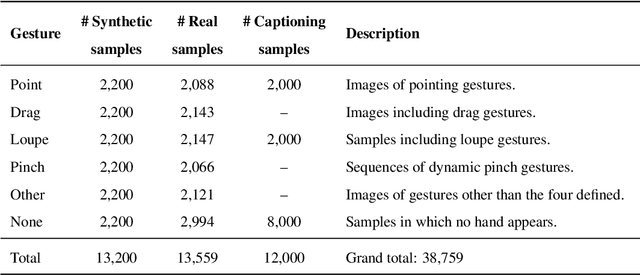
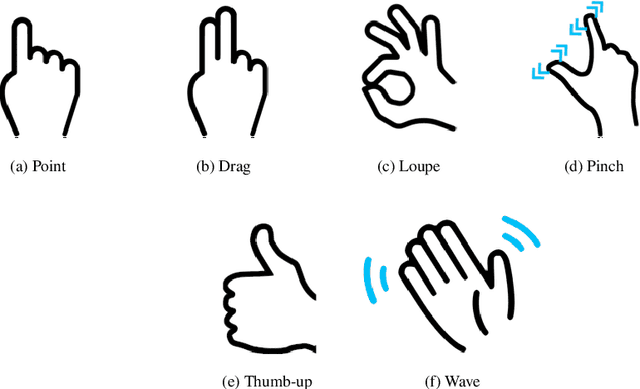

This paper proposes an interactive system for mobile devices controlled by hand gestures aimed at helping people with visual impairments. This system allows the user to interact with the device by making simple static and dynamic hand gestures. Each gesture triggers a different action in the system, such as object recognition, scene description or image scaling (e.g., pointing a finger at an object will show a description of it). The system is based on a multi-head neural network architecture, which initially detects and classifies the gestures, and subsequently, depending on the gesture detected, performs a second stage that carries out the corresponding action. This multi-head architecture optimizes the resources required to perform different tasks simultaneously, and takes advantage of the information obtained from an initial backbone to perform different processes in a second stage. To train and evaluate the system, a dataset with about 40k images was manually compiled and labeled including different types of hand gestures, backgrounds (indoors and outdoors), lighting conditions, etc. This dataset contains synthetic gestures (whose objective is to pre-train the system in order to improve the results) and real images captured using different mobile phones. The results obtained and the comparison made with the state of the art show competitive results as regards the different actions performed by the system, such as the accuracy of classification and localization of gestures, or the generation of descriptions for objects and scenes.
Multi-Label Logo Recognition and Retrieval based on Weighted Fusion of Neural Features
May 11, 2022

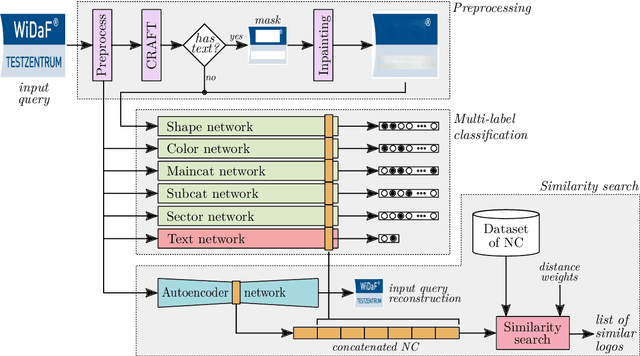

Logo classification is a particular case of image classification, since these may contain only text, images, or a combination of both. In this work, we propose a system for the multi-label classification and similarity search of logo images. The method allows obtaining the most similar logos on the basis of their shape, color, business sector, semantics, general characteristics, or a combination of such features established by the user. This is done by employing a set of multi-label networks specialized in certain characteristics of logos. The features extracted from these networks are combined to perform the similarity search according to the search criteria established. Since the text of logos is sometimes irrelevant for the classification, a preprocessing stage is carried out to remove it, thus improving the overall performance. The proposed approach is evaluated using the European Union Trademark (EUTM) dataset, structured with the hierarchical Vienna classification system, which includes a series of metadata with which to index trademarks. We also make a comparison between well known logo topologies and Vienna in order to help designers understand their correspondences. The experimentation carried out attained reliable performance results, both quantitatively and qualitatively, which outperformed the state-of-the-art results. In addition, since the semantics and classification of brands can often be subjective, we also surveyed graphic design students and professionals in order to assess the reliability of the proposed method.
Two Heads are Better than One: Geometric-Latent Attention for Point Cloud Classification and Segmentation
Oct 30, 2021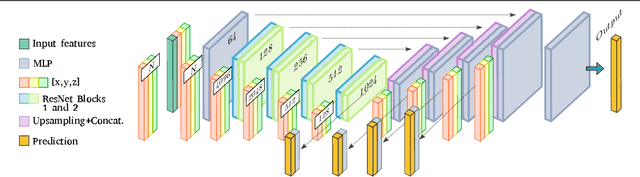
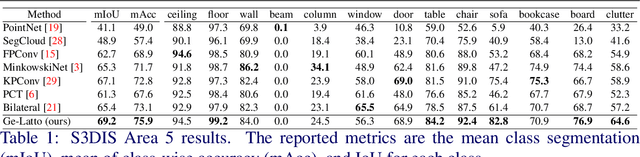
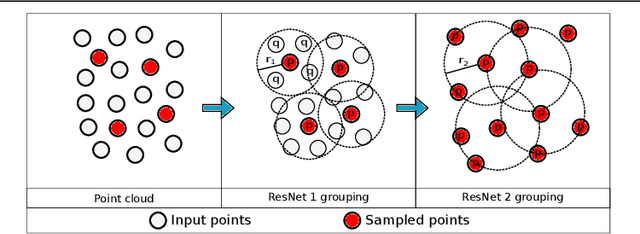

We present an innovative two-headed attention layer that combines geometric and latent features to segment a 3D scene into semantically meaningful subsets. Each head combines local and global information, using either the geometric or latent features, of a neighborhood of points and uses this information to learn better local relationships. This Geometric-Latent attention layer (Ge-Latto) is combined with a sub-sampling strategy to capture global features. Our method is invariant to permutation thanks to the use of shared-MLP layers, and it can also be used with point clouds with varying densities because the local attention layer does not depend on the neighbor order. Our proposal is simple yet robust, which allows it to achieve competitive results in the ShapeNetPart and ModelNet40 datasets, and the state-of-the-art when segmenting the complex dataset S3DIS, with 69.2% IoU on Area 5, and 89.7% overall accuracy using K-fold cross-validation on the 6 areas.