 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Gesture Recognition for the Assistance of Visually Impaired People using Multi-Head Neural Networks
May 14, 2022
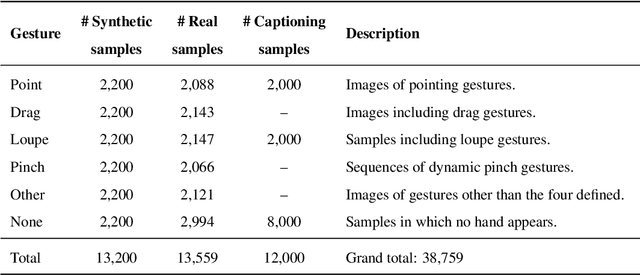
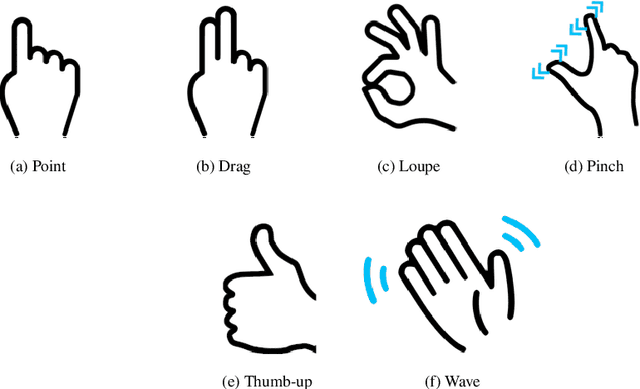

This paper proposes an interactive system for mobile devices controlled by hand gestures aimed at helping people with visual impairments. This system allows the user to interact with the device by making simple static and dynamic hand gestures. Each gesture triggers a different action in the system, such as object recognition, scene description or image scaling (e.g., pointing a finger at an object will show a description of it). The system is based on a multi-head neural network architecture, which initially detects and classifies the gestures, and subsequently, depending on the gesture detected, performs a second stage that carries out the corresponding action. This multi-head architecture optimizes the resources required to perform different tasks simultaneously, and takes advantage of the information obtained from an initial backbone to perform different processes in a second stage. To train and evaluate the system, a dataset with about 40k images was manually compiled and labeled including different types of hand gestures, backgrounds (indoors and outdoors), lighting conditions, etc. This dataset contains synthetic gestures (whose objective is to pre-train the system in order to improve the results) and real images captured using different mobile phones. The results obtained and the comparison made with the state of the art show competitive results as regards the different actions performed by the system, such as the accuracy of classification and localization of gestures, or the generation of descriptions for objects and scenes.