 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoBot: Efficient Learning of Bimanual Manipulation with Dexterous Hands From Third-Person Human Videos
Jan 04, 2026This work presents DemoBot, a learning framework that enables a dual-arm, multi-finger robotic system to acquire complex manipulation skills from a single unannotated RGB-D video demonstration. The method extracts structured motion trajectories of both hands and objects from raw video data. These trajectories serve as motion priors for a novel reinforcement learning (RL) pipeline that learns to refine them through contact-rich interactions, thereby eliminating the need to learn from scratch. To address the challenge of learning long-horizon manipulation skills, we introduce: (1) Temporal-segment based RL to enforce temporal alignment of the current state with demonstrations; (2) Success-Gated Reset strategy to balance the refinement of readily acquired skills and the exploration of subsequent task stages; and (3) Event-Driven Reward curriculum with adaptive thresholding to guide the RL learning of high-precision manipulation. The novel video processing and RL framework successfully achieved long-horizon synchronous and asynchronous bimanual assembly tasks, offering a scalable approach for direct skill acquisition from human videos.
Unobtrusive Monitoring of Physical Weakness: A Simulated Approach
Jun 14, 2024Aging and chronic conditions affect older adults' daily lives, making early detection of developing health issues crucial. Weakness, common in many conditions, alters physical movements and daily activities subtly. However, detecting such changes can be challenging due to their subtle and gradual nature. To address this, we employ a non-intrusive camera sensor to monitor individuals' daily sitting and relaxing activities for signs of weakness. We simulate weakness in healthy subjects by having them perform physical exercise and observing the behavioral changes in their daily activities before and after workouts. The proposed system captures fine-grained features related to body motion, inactivity, and environmental context in real-time while prioritizing privacy. A Bayesian Network is used to model the relationships between features, activities, and health conditions. We aim to identify specific features and activities that indicate such changes and determine the most suitable time scale for observing the change. Results show 0.97 accuracy in distinguishing simulated weakness at the daily level. Fine-grained behavioral features, including non-dominant upper body motion speed and scale, and inactivity distribution, along with a 300-second window, are found most effective. However, individual-specific models are recommended as no universal set of optimal features and activities was identified across all participants.
Global Point Cloud Registration Network for Large Transformations
Mar 26, 2024Three-dimensional data registration is an established yet challenging problem that is key in many different applications, such as mapping the environment for autonomous vehicles, and modeling objects and people for avatar creation, among many others. Registration refers to the process of mapping multiple data into the same coordinate system by means of matching correspondences and transformation estimation. Novel proposals exploit the benefits of deep learning architectures for this purpose, as they learn the best features for the data, providing better matches and hence results. However, the state of the art is usually focused on cases of relatively small transformations, although in certain applications and in a real and practical environment, large transformations are very common. In this paper, we present ReLaTo (Registration for Large Transformations), an architecture that faces the cases where large transformations happen while maintaining good performance for local transformations. This proposal uses a novel Softmax pooling layer to find correspondences in a bilateral consensus manner between two point sets, sampling the most confident matches. These matches are used to estimate a coarse and global registration using weighted Singular Value Decomposition (SVD). A target-guided denoising step is then applied to both the obtained matches and latent features, estimating the final fine registration considering the local geometry. All these steps are carried out following an end-to-end approach, which has been shown to improve 10 state-of-the-art registration methods in two datasets commonly used for this task (ModelNet40 and KITTI), especially in the case of large transformations.
DexDLO: Learning Goal-Conditioned Dexterous Policy for Dynamic Manipulation of Deformable Linear Objects
Dec 23, 2023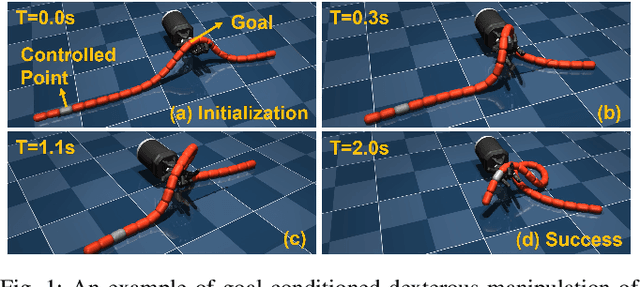



Deformable linear object (DLO) manipulation is needed in many fields. Previous research on deformable linear object (DLO) manipulation has primarily involved parallel jaw gripper manipulation with fixed grasping positions. However, the potential for dexterous manipulation of DLOs using an anthropomorphic hand is under-explored. We present DexDLO, a model-free framework that learns dexterous dynamic manipulation policies for deformable linear objects with a fixed-base dexterous hand in an end-to-end way. By abstracting several common DLO manipulation tasks into goal-conditioned tasks, our DexDLO can perform these tasks, such as DLO grabbing, DLO pulling, DLO end-tip position controlling, etc. Using the Mujoco physics simulator, we demonstrate that our framework can efficiently and effectively learn five different DLO manipulation tasks with the same framework parameters. We further provide a thorough analysis of learned policies, reward functions, and reduced observations for a comprehensive understanding of the framework.
Monitoring Inactivity of Single Older Adults at Home
Nov 03, 2023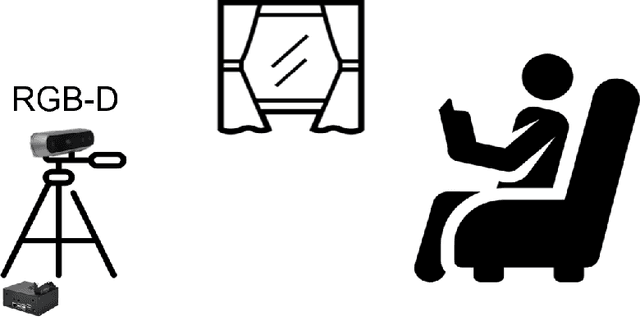
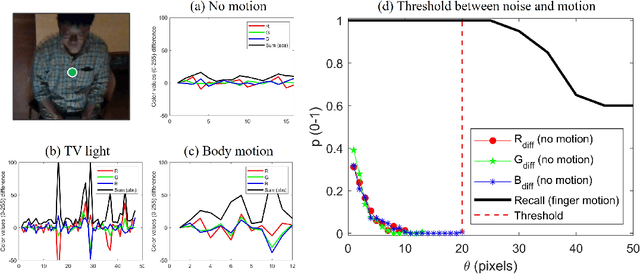

A new application for real-time monitoring of the lack of movement in older adults' own homes is proposed, aiming to support people's lives and independence in their later years. A lightweight camera monitoring system, based on an RGB-D camera and a compact computer processor, was developed and piloted in community homes to observe the daily behavior of older adults. Instances of body inactivity were detected in everyday scenarios anonymously and unobtrusively. These events can be explained at a higher level, such as a loss of consciousness or physiological deterioration. The accuracy of the inactivity monitoring system is assessed, and statistics of inactivity events related to the daily behavior of the older adults are provided. The results demonstrate that our method performs accurately in inactivity detection across various environments, including low room lighting, TV flickering, and different camera views.
A Multi-modal Garden Dataset and Hybrid 3D Dense Reconstruction Framework Based on Panoramic Stereo Images for a Trimming Robot
May 10, 2023
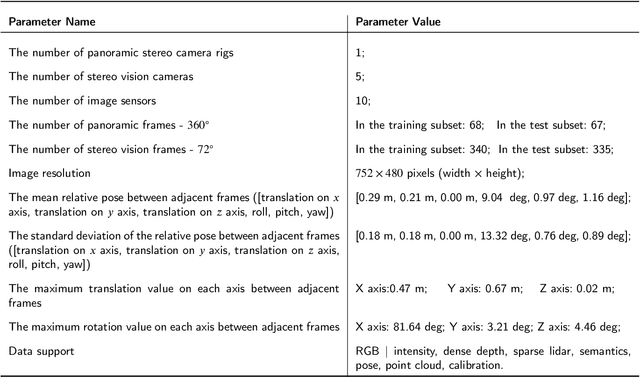
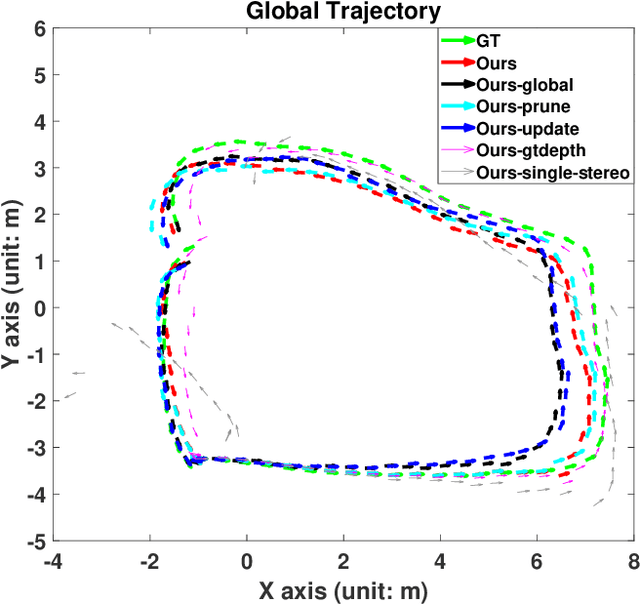
Recovering an outdoor environment's surface mesh is vital for an agricultural robot during task planning and remote visualization. Our proposed solution is based on a newly-designed panoramic stereo camera along with a hybrid novel software framework that consists of three fusion modules. The panoramic stereo camera with a pentagon shape consists of 5 stereo vision camera pairs to stream synchronized panoramic stereo images for the following three fusion modules. In the disparity fusion module, rectified stereo images produce the initial disparity maps using multiple stereo vision algorithms. Then, these initial disparity maps, along with the intensity images, are input into a disparity fusion network to produce refined disparity maps. Next, the refined disparity maps are converted into full-view point clouds or single-view point clouds for the pose fusion module. The pose fusion module adopts a two-stage global-coarse-to-local-fine strategy. In the first stage, each pair of full-view point clouds is registered by a global point cloud matching algorithm to estimate the transformation for a global pose graph's edge, which effectively implements loop closure. In the second stage, a local point cloud matching algorithm is used to match single-view point clouds in different nodes. Next, we locally refine the poses of all corresponding edges in the global pose graph using three proposed rules, thus constructing a refined pose graph. The refined pose graph is optimized to produce a global pose trajectory for volumetric fusion. In the volumetric fusion module, the global poses of all the nodes are used to integrate the single-view point clouds into the volume to produce the mesh of the whole garden. The proposed framework and its three fusion modules are tested on a real outdoor garden dataset to show the superiority of the performance.
A General Mobile Manipulator Automation Framework for Flexible Manufacturing in Hostile Industrial Environments
Feb 09, 2023
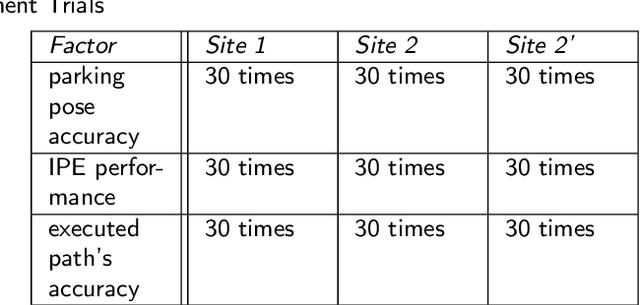

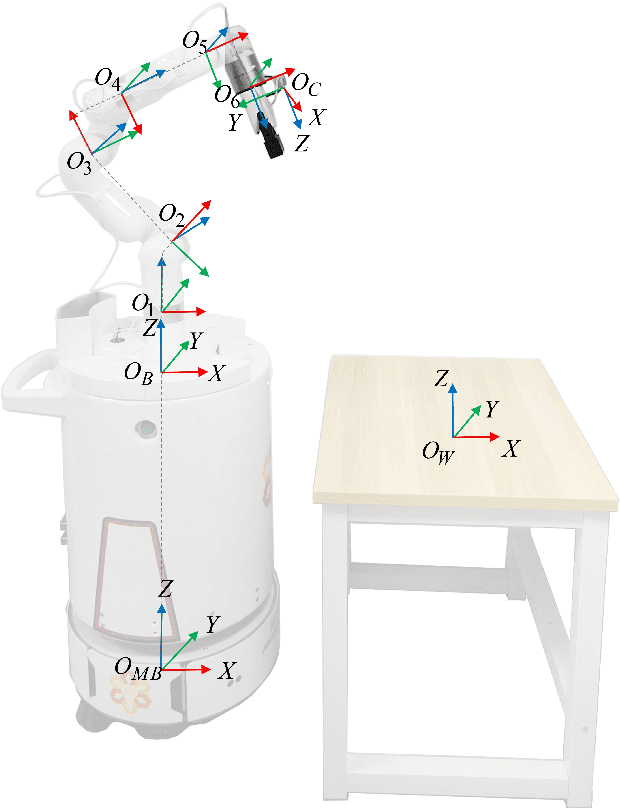
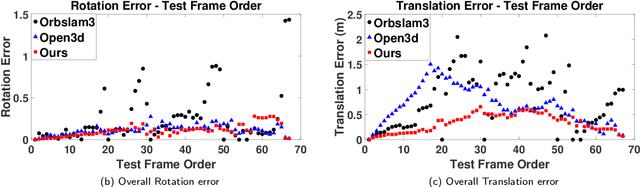
To enable a mobile manipulator to perform human tasks from a single teaching demonstration is vital to flexible manufacturing. We call our proposed method MMPA (Mobile Manipulator Process Automation with One-shot Teaching). Currently, there is no effective and robust MMPA framework which is not influenced by harsh industrial environments and the mobile base's parking precision. The proposed MMPA framework consists of two stages: collecting data (mobile base's location, environment information, end-effector's path) in the teaching stage for robot learning; letting the end-effector repeat the nearly same path as the reference path in the world frame to reproduce the work in the automation stage. More specifically, in the automation stage, the robot navigates to the specified location without the need of a precise parking. Then, based on colored point cloud registration, the proposed IPE (Iterative Pose Estimation by Eye & Hand) algorithm could estimate the accurate 6D relative parking pose of the robot arm base without the need of any marker. Finally, the robot could learn the error compensation from the parking pose's bias to modify the end-effector's path to make it repeat a nearly same path in the world coordinate system as recorded in the teaching stage. Hundreds of trials have been conducted with a real mobile manipulator to show the superior robustness of the system and the accuracy of the process automation regardless of the harsh industrial conditions and parking precision. For the released code, please contact marketing@amigaga.com
3D Lip Event Detection via Interframe Motion Divergence at Multiple Temporal Resolutions
Nov 18, 2021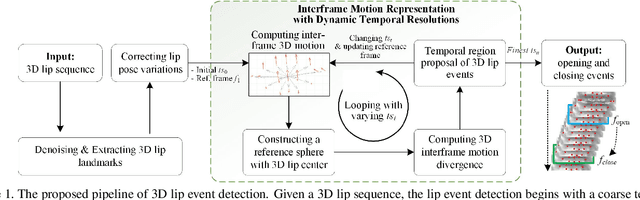
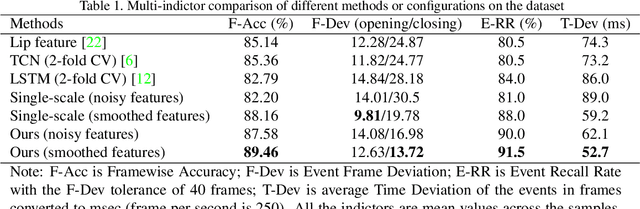
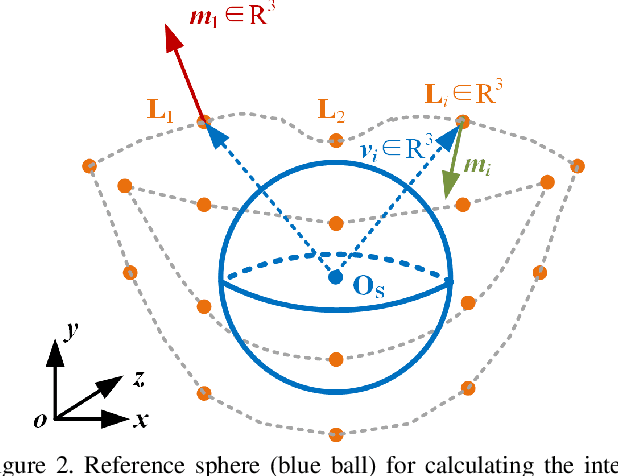
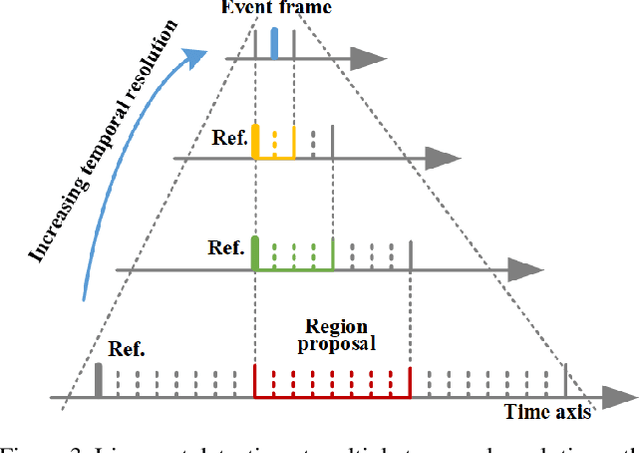
The lip is a dominant dynamic facial unit when a person is speaking. Detecting lip events is beneficial to speech analysis and support for the hearing impaired. This paper proposes a 3D lip event detection pipeline that automatically determines the lip events from a 3D speaking lip sequence. We define a motion divergence measure using 3D lip landmarks to quantify the interframe dynamics of a 3D speaking lip. Then, we cast the interframe motion detection in a multi-temporal-resolution framework that allows the detection to be applicable to different speaking speeds. The experiments on the S3DFM Dataset investigate the overall 3D lip dynamics based on the proposed motion divergence. The proposed 3D pipeline is able to detect opening and closing lip events across 100 sequences, achieving a state-of-the-art performance.
Learning Object-Centric Representations of Multi-Object Scenes from Multiple Views
Nov 13, 2021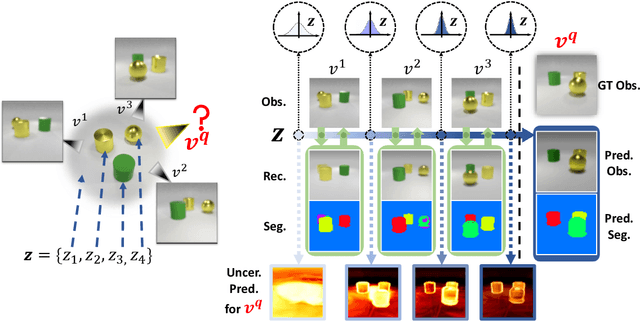
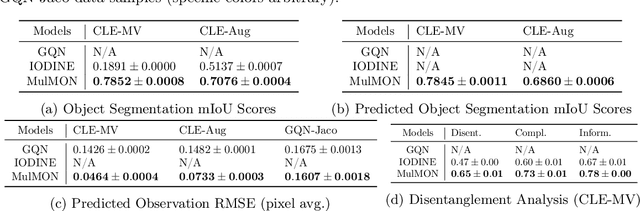
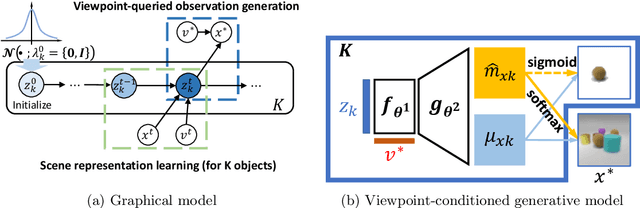

Learning object-centric representations of multi-object scenes is a promising approach towards machine intelligence, facilitating high-level reasoning and control from visual sensory data. However, current approaches for unsupervised object-centric scene representation are incapable of aggregating information from multiple observations of a scene. As a result, these "single-view" methods form their representations of a 3D scene based only on a single 2D observation (view). Naturally, this leads to several inaccuracies, with these methods falling victim to single-view spatial ambiguities. To address this, we propose The Multi-View and Multi-Object Network (MulMON) -- a method for learning accurate, object-centric representations of multi-object scenes by leveraging multiple views. In order to sidestep the main technical difficulty of the multi-object-multi-view scenario -- maintaining object correspondences across views -- MulMON iteratively updates the latent object representations for a scene over multiple views. To ensure that these iterative updates do indeed aggregate spatial information to form a complete 3D scene understanding, MulMON is asked to predict the appearance of the scene from novel viewpoints during training. Through experiments, we show that MulMON better-resolves spatial ambiguities than single-view methods -- learning more accurate and disentangled object representations -- and also achieves new functionality in predicting object segmentations for novel viewpoints.
Object-Centric Representation Learning with Generative Spatial-Temporal Factorization
Nov 09, 2021
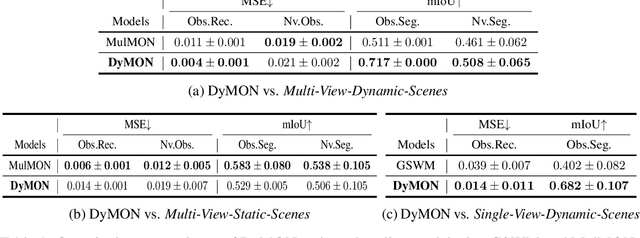
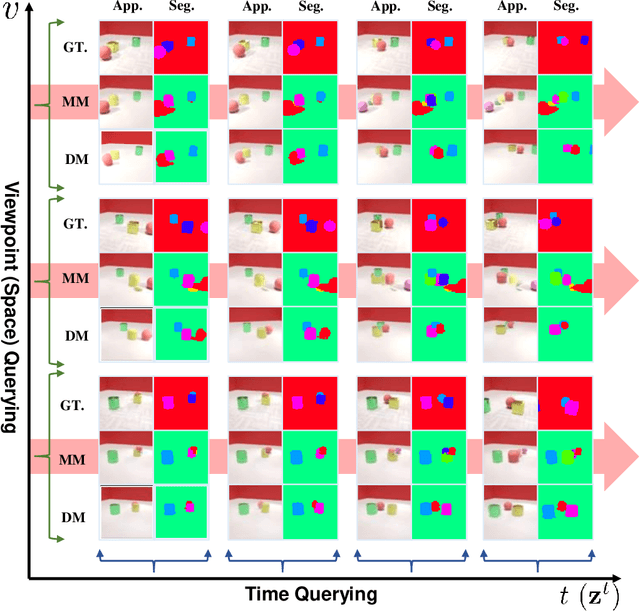

Learning object-centric scene representations is essential for attaining structural understanding and abstraction of complex scenes. Yet, as current approaches for unsupervised object-centric representation learning are built upon either a stationary observer assumption or a static scene assumption, they often: i) suffer single-view spatial ambiguities, or ii) infer incorrectly or inaccurately object representations from dynamic scenes. To address this, we propose Dynamics-aware Multi-Object Network (DyMON), a method that broadens the scope of multi-view object-centric representation learning to dynamic scenes. We train DyMON on multi-view-dynamic-scene data and show that DyMON learns -- without supervision -- to factorize the entangled effects of observer motions and scene object dynamics from a sequence of observations, and constructs scene object spatial representations suitable for rendering at arbitrary times (querying across time) and from arbitrary viewpoints (querying across space). We also show that the factorized scene representations (w.r.t. objects) support querying about a single object by space and time independently.