 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-Horizon Robot Manipulation Skills via Privileged Action
Feb 21, 2025



Long-horizon contact-rich tasks are challenging to learn with reinforcement learning, due to ineffective exploration of high-dimensional state spaces with sparse rewards. The learning process often gets stuck in local optimum and demands task-specific reward fine-tuning for complex scenarios. In this work, we propose a structured framework that leverages privileged actions with curriculum learning, enabling the policy to efficiently acquire long-horizon skills without relying on extensive reward engineering or reference trajectories. Specifically, we use privileged actions in simulation with a general training procedure that would be infeasible to implement in real-world scenarios. These privileges include relaxed constraints and virtual forces that enhance interaction and exploration with objects. Our results successfully achieve complex multi-stage long-horizon tasks that naturally combine non-prehensile manipulation with grasping to lift objects from non-graspable poses. We demonstrate generality by maintaining a parsimonious reward structure and showing convergence to diverse and robust behaviors across various environments. Additionally, real-world experiments further confirm that the skills acquired using our approach are transferable to real-world environments, exhibiting robust and intricate performance. Our approach outperforms state-of-the-art methods in these tasks, converging to solutions where others fail.
Object-Centric Representation Learning with Generative Spatial-Temporal Factorization
Nov 09, 2021
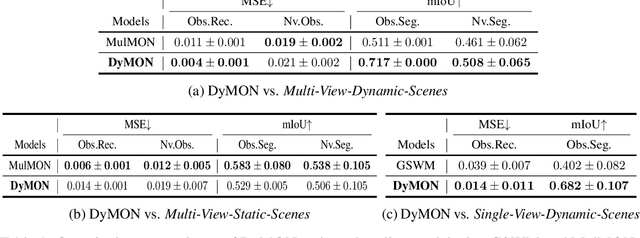
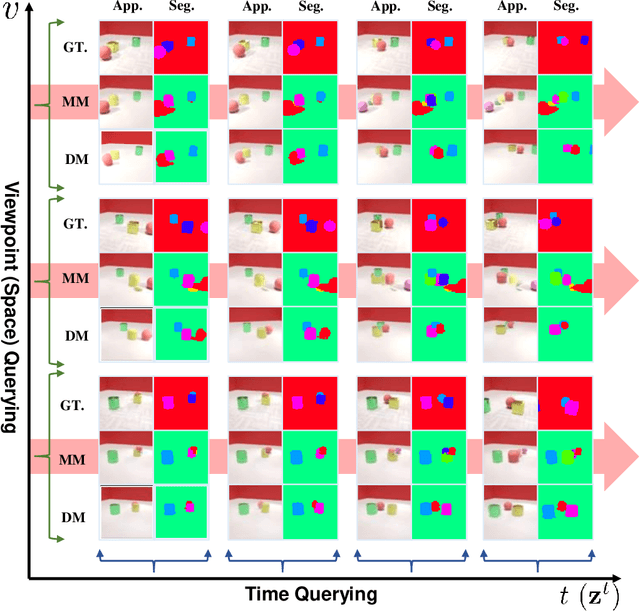

Learning object-centric scene representations is essential for attaining structural understanding and abstraction of complex scenes. Yet, as current approaches for unsupervised object-centric representation learning are built upon either a stationary observer assumption or a static scene assumption, they often: i) suffer single-view spatial ambiguities, or ii) infer incorrectly or inaccurately object representations from dynamic scenes. To address this, we propose Dynamics-aware Multi-Object Network (DyMON), a method that broadens the scope of multi-view object-centric representation learning to dynamic scenes. We train DyMON on multi-view-dynamic-scene data and show that DyMON learns -- without supervision -- to factorize the entangled effects of observer motions and scene object dynamics from a sequence of observations, and constructs scene object spatial representations suitable for rendering at arbitrary times (querying across time) and from arbitrary viewpoints (querying across space). We also show that the factorized scene representations (w.r.t. objects) support querying about a single object by space and time independently.
Learning Pregrasp Manipulation of Objects from Ungraspable Poses
Feb 15, 2020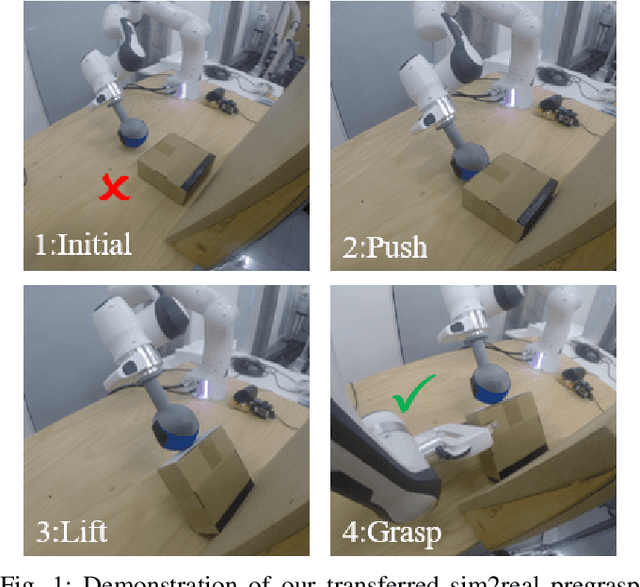
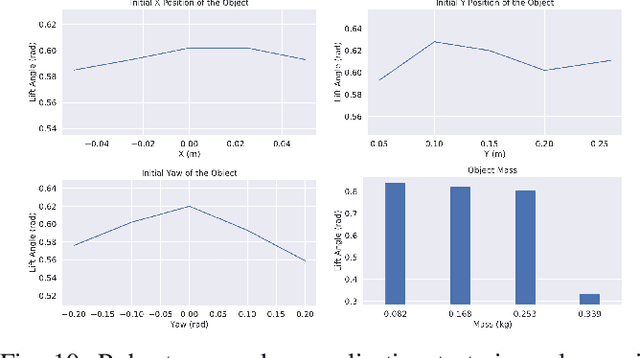


In robotic grasping, objects are often occluded in ungraspable configurations such that no pregrasp pose can be found, eg large flat boxes on the table that can only be grasped from the side. Inspired by humans' bimanual manipulation, eg one hand to lift up things and the other to grasp, we address this type of problems by introducing pregrasp manipulation - push and lift actions. We propose a model-free Deep Reinforcement Learning framework to train control policies that utilize visual information and proprioceptive states of the robot to autonomously discover robust pregrasp manipulation. The robot arm learns to first push the object towards a support surface and establishes a pivot to lift up one side of the object, thus creating a clearance between the object and the table for possible grasping solutions. Furthermore, we show the effectiveness of our proposed learning framework in training robust pregrasp policies that can directly transfer from simulation to real hardware through suitable design of training procedures, state, and action space. Lastly, we evaluate the effectiveness and the generalisation ability of the learned policies in real-world experiments, and demonstrate pregrasp manipulation of objects with various size, shape, weight, and surface friction.