 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemoBot: Efficient Learning of Bimanual Manipulation with Dexterous Hands From Third-Person Human Videos
Jan 04, 2026This work presents DemoBot, a learning framework that enables a dual-arm, multi-finger robotic system to acquire complex manipulation skills from a single unannotated RGB-D video demonstration. The method extracts structured motion trajectories of both hands and objects from raw video data. These trajectories serve as motion priors for a novel reinforcement learning (RL) pipeline that learns to refine them through contact-rich interactions, thereby eliminating the need to learn from scratch. To address the challenge of learning long-horizon manipulation skills, we introduce: (1) Temporal-segment based RL to enforce temporal alignment of the current state with demonstrations; (2) Success-Gated Reset strategy to balance the refinement of readily acquired skills and the exploration of subsequent task stages; and (3) Event-Driven Reward curriculum with adaptive thresholding to guide the RL learning of high-precision manipulation. The novel video processing and RL framework successfully achieved long-horizon synchronous and asynchronous bimanual assembly tasks, offering a scalable approach for direct skill acquisition from human videos.
Enhancing Tactile-based Reinforcement Learning for Robotic Control
Oct 24, 2025Achieving safe, reliable real-world robotic manipulation requires agents to evolve beyond vision and incorporate tactile sensing to overcome sensory deficits and reliance on idealised state information. Despite its potential, the efficacy of tactile sensing in reinforcement learning (RL) remains inconsistent. We address this by developing self-supervised learning (SSL) methodologies to more effectively harness tactile observations, focusing on a scalable setup of proprioception and sparse binary contacts. We empirically demonstrate that sparse binary tactile signals are critical for dexterity, particularly for interactions that proprioceptive control errors do not register, such as decoupled robot-object motions. Our agents achieve superhuman dexterity in complex contact tasks (ball bouncing and Baoding ball rotation). Furthermore, we find that decoupling the SSL memory from the on-policy memory can improve performance. We release the Robot Tactile Olympiad (RoTO) benchmark to standardise and promote future research in tactile-based manipulation. Project page: https://elle-miller.github.io/tactile_rl
Learning Long-Horizon Robot Manipulation Skills via Privileged Action
Feb 21, 2025



Long-horizon contact-rich tasks are challenging to learn with reinforcement learning, due to ineffective exploration of high-dimensional state spaces with sparse rewards. The learning process often gets stuck in local optimum and demands task-specific reward fine-tuning for complex scenarios. In this work, we propose a structured framework that leverages privileged actions with curriculum learning, enabling the policy to efficiently acquire long-horizon skills without relying on extensive reward engineering or reference trajectories. Specifically, we use privileged actions in simulation with a general training procedure that would be infeasible to implement in real-world scenarios. These privileges include relaxed constraints and virtual forces that enhance interaction and exploration with objects. Our results successfully achieve complex multi-stage long-horizon tasks that naturally combine non-prehensile manipulation with grasping to lift objects from non-graspable poses. We demonstrate generality by maintaining a parsimonious reward structure and showing convergence to diverse and robust behaviors across various environments. Additionally, real-world experiments further confirm that the skills acquired using our approach are transferable to real-world environments, exhibiting robust and intricate performance. Our approach outperforms state-of-the-art methods in these tasks, converging to solutions where others fail.
Few-shot Semantic Learning for Robust Multi-Biome 3D Semantic Mapping in Off-Road Environments
Nov 10, 2024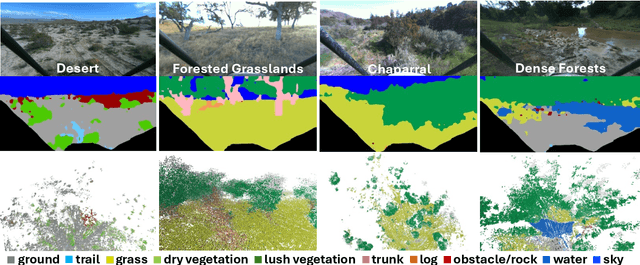
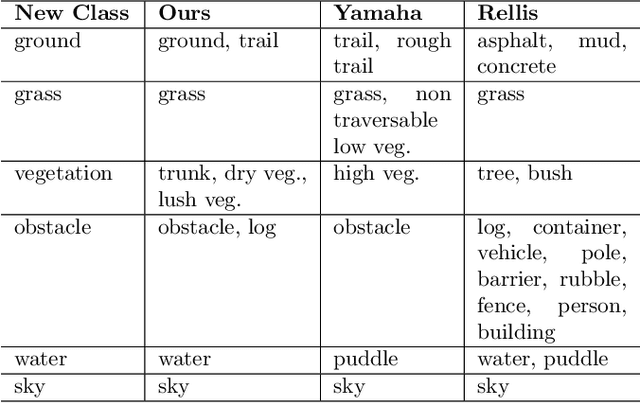

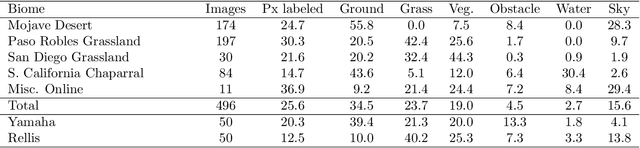
Off-road environments pose significant perception challenges for high-speed autonomous navigation due to unstructured terrain, degraded sensing conditions, and domain-shifts among biomes. Learning semantic information across these conditions and biomes can be challenging when a large amount of ground truth data is required. In this work, we propose an approach that leverages a pre-trained Vision Transformer (ViT) with fine-tuning on a small (<500 images), sparse and coarsely labeled (<30% pixels) multi-biome dataset to predict 2D semantic segmentation classes. These classes are fused over time via a novel range-based metric and aggregated into a 3D semantic voxel map. We demonstrate zero-shot out-of-biome 2D semantic segmentation on the Yamaha (52.9 mIoU) and Rellis (55.5 mIoU) datasets along with few-shot coarse sparse labeling with existing data for improved segmentation performance on Yamaha (66.6 mIoU) and Rellis (67.2 mIoU). We further illustrate the feasibility of using a voxel map with a range-based semantic fusion approach to handle common off-road hazards like pop-up hazards, overhangs, and water features.
Unknown Object Grasping for Assistive Robotics
Apr 23, 2024
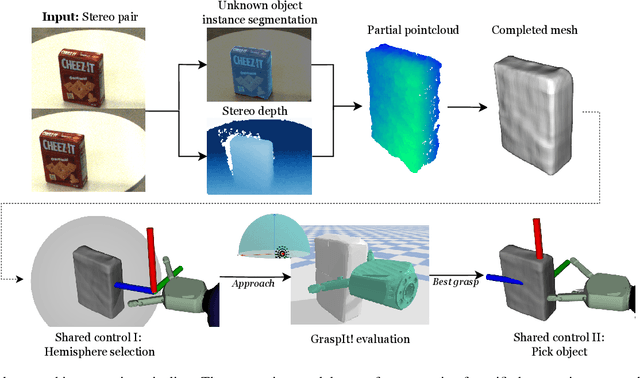
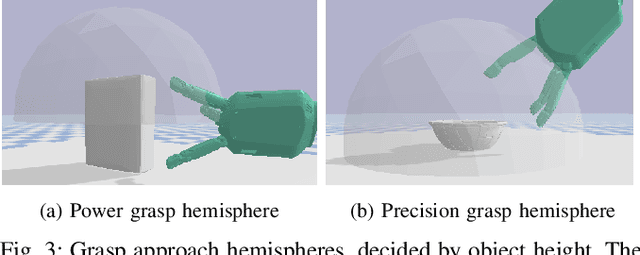
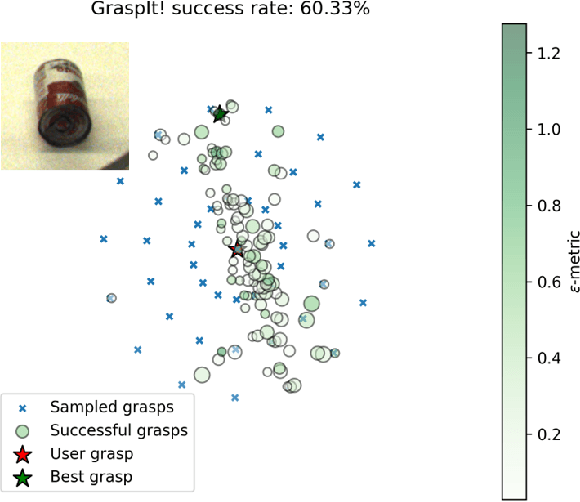
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.