 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeroto 2.0: The Robot Tactile Olympiad
May 20, 2026Tactile-based reinforcement learning (RL) is currently hindered by fragmented research and a focus on over-saturated orientation tasks. We introduce v2 of the Robot Tactile Olympiad (\texttt{roto 2.0}), a GPU-parallelised benchmark designed to standardise tactile-based RL across four distinct robotic morphologies (16-DOF to 24-DOF). Unlike prior benchmarks, roto focuses on end-to-end "blind" manipulation, utilising only proprioception and tactile sensing without state information or distillation. We demonstrate a significant performance leap, with our blind agents achieving 13 Baoding ball rotations in 10 seconds, an order of magnitude faster than current state-of-the-art speeds. By open-sourcing our environments and robustly tuned baselines, we reduce the barrier to entry and enable researchers to prioritise fundamental algorithmic challenges over tedious RL tuning. Website: https://elle-miller.github.io/roto/
CODA: Coordination via On-Policy Diffusion for Multi-Agent Offline Reinforcement Learning
Apr 25, 2026Offline multi-agent reinforcement learning (MARL) enables policy learning from fixed datasets, but is prone to coordination failure: agents trained on static, off-policy data converge to suboptimal joint behaviours because they cannot co-adapt as their policies change. We introduce CODA (Coordination via On-Policy Diffusion for Multi-Agent Reinforcement Learning), a diffusion-based multi-agent trajectory generator for data augmentation that samples conditioned on the current joint policy, producing synthetic experience which reflects the evolving behaviours of the agents, thereby providing a mechanism for co-adaptation. We find that previous diffusion-based augmentation approaches are insufficient for fostering multi-agent coordination because they produce static augmented datasets that do not evolve as the current joint policy changes during training; CODA resolves this by more closely simulating on-policy learning and is a meaningful step toward coordinated behaviours in the offline setting. CODA is algorithm-agnostic and can be layered onto both model-free and model-based offline reinforcement learning pipelines as an augmentation module. Empirically, CODA not only resolves canonical coordination pathologies in continuous polynomial games but also delivers strong results on the more complex MaMuJoCo continuous-control benchmarks.
Terra Nova: A Comprehensive Challenge Environment for Intelligent Agents
Nov 19, 2025

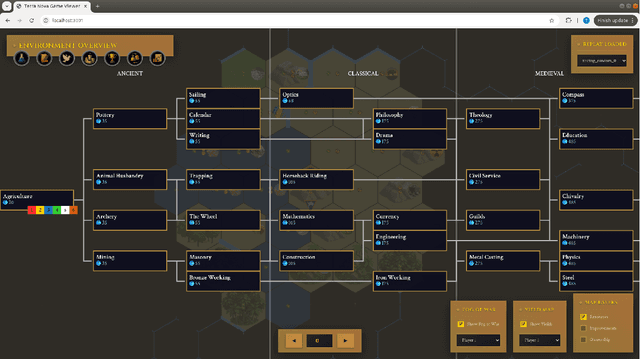
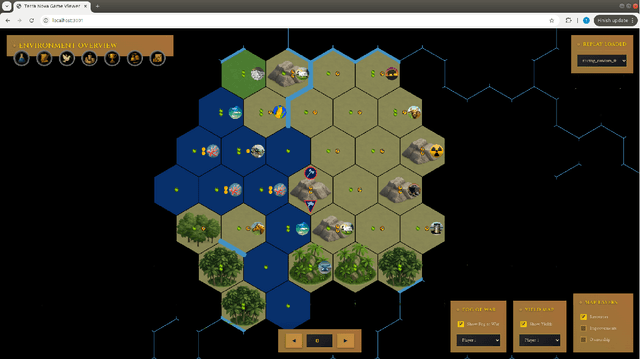
We introduce Terra Nova, a new comprehensive challenge environment (CCE) for reinforcement learning (RL) research inspired by Civilization V. A CCE is a single environment in which multiple canonical RL challenges (e.g., partial observability, credit assignment, representation learning, enormous action spaces, etc.) arise simultaneously. Mastery therefore demands integrated, long-horizon understanding across many interacting variables. We emphasize that this definition excludes challenges that only aggregate unrelated tasks in independent, parallel streams (e.g., learning to play all Atari games at once). These aggregated multitask benchmarks primarily asses whether an agent can catalog and switch among unrelated policies rather than test an agent's ability to perform deep reasoning across many interacting challenges.
Forgetting is Everywhere
Nov 06, 2025A fundamental challenge in developing general learning algorithms is their tendency to forget past knowledge when adapting to new data. Addressing this problem requires a principled understanding of forgetting; yet, despite decades of study, no unified definition has emerged that provides insights into the underlying dynamics of learning. We propose an algorithm- and task-agnostic theory that characterises forgetting as a lack of self-consistency in a learner's predictive distribution over future experiences, manifesting as a loss of predictive information. Our theory naturally yields a general measure of an algorithm's propensity to forget. To validate the theory, we design a comprehensive set of experiments that span classification, regression, generative modelling, and reinforcement learning. We empirically demonstrate how forgetting is present across all learning settings and plays a significant role in determining learning efficiency. Together, these results establish a principled understanding of forgetting and lay the foundation for analysing and improving the information retention capabilities of general learning algorithms.
Enhancing Tactile-based Reinforcement Learning for Robotic Control
Oct 24, 2025Achieving safe, reliable real-world robotic manipulation requires agents to evolve beyond vision and incorporate tactile sensing to overcome sensory deficits and reliance on idealised state information. Despite its potential, the efficacy of tactile sensing in reinforcement learning (RL) remains inconsistent. We address this by developing self-supervised learning (SSL) methodologies to more effectively harness tactile observations, focusing on a scalable setup of proprioception and sparse binary contacts. We empirically demonstrate that sparse binary tactile signals are critical for dexterity, particularly for interactions that proprioceptive control errors do not register, such as decoupled robot-object motions. Our agents achieve superhuman dexterity in complex contact tasks (ball bouncing and Baoding ball rotation). Furthermore, we find that decoupling the SSL memory from the on-policy memory can improve performance. We release the Robot Tactile Olympiad (RoTO) benchmark to standardise and promote future research in tactile-based manipulation. Project page: https://elle-miller.github.io/tactile_rl
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning
Mar 08, 2025
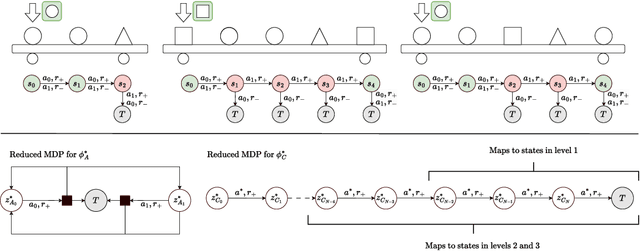

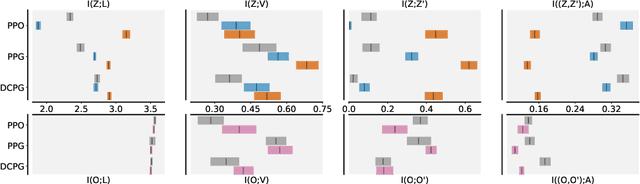
Extracting relevant information from a stream of high-dimensional observations is a central challenge for deep reinforcement learning agents. Actor-critic algorithms add further complexity to this challenge, as it is often unclear whether the same information will be relevant to both the actor and the critic. To this end, we here explore the principles that underlie effective representations for the actor and for the critic in on-policy algorithms. We focus our study on understanding whether the actor and critic will benefit from separate, rather than shared, representations. Our primary finding is that when separated, the representations for the actor and critic systematically specialise in extracting different types of information from the environment -- the actor's representation tends to focus on action-relevant information, while the critic's representation specialises in encoding value and dynamics information. We conduct a rigourous empirical study to understand how different representation learning approaches affect the actor and critic's specialisations and their downstream performance, in terms of sample efficiency and generation capabilities. Finally, we discover that a separated critic plays an important role in exploration and data collection during training. Our code, trained models and data are accessible at https://github.com/francelico/deac-rep.
Objects matter: object-centric world models improve reinforcement learning in visually complex environments
Jan 27, 2025Deep reinforcement learning has achieved remarkable success in learning control policies from pixels across a wide range of tasks, yet its application remains hindered by low sample efficiency, requiring significantly more environment interactions than humans to reach comparable performance. Model-based reinforcement learning (MBRL) offers a solution by leveraging learnt world models to generate simulated experience, thereby improving sample efficiency. However, in visually complex environments, small or dynamic elements can be critical for decision-making. Yet, traditional MBRL methods in pixel-based environments typically rely on auto-encoding with an $L_2$ loss, which is dominated by large areas and often fails to capture decision-relevant details. To address these limitations, we propose an object-centric MBRL pipeline, which integrates recent advances in computer vision to allow agents to focus on key decision-related elements. Our approach consists of four main steps: (1) annotating key objects related to rewards and goals with segmentation masks, (2) extracting object features using a pre-trained, frozen foundation vision model, (3) incorporating these object features with the raw observations to predict environmental dynamics, and (4) training the policy using imagined trajectories generated by this object-centric world model. Building on the efficient MBRL algorithm STORM, we call this pipeline OC-STORM. We demonstrate OC-STORM's practical value in overcoming the limitations of conventional MBRL approaches on both Atari games and the visually complex game Hollow Knight.
Efficient Offline Reinforcement Learning: The Critic is Critical
Jun 19, 2024Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
LLM-Personalize: Aligning LLM Planners with Human Preferences via Reinforced Self-Training for Housekeeping Robots
Apr 22, 2024



Large language models (LLMs) have shown significant potential for robotics applications, particularly task planning, by harnessing their language comprehension and text generation capabilities. However, in applications such as household robotics, a critical gap remains in the personalization of these models to individual user preferences. We introduce LLM-Personalize, a novel framework with an optimization pipeline designed to personalize LLM planners for household robotics. Our LLM-Personalize framework features an LLM planner that performs iterative planning in multi-room, partially-observable household scenarios, making use of a scene graph constructed with local observations. The generated plan consists of a sequence of high-level actions which are subsequently executed by a controller. Central to our approach is the optimization pipeline, which combines imitation learning and iterative self-training to personalize the LLM planner. In particular, the imitation learning phase performs initial LLM alignment from demonstrations, and bootstraps the model to facilitate effective iterative self-training, which further explores and aligns the model to user preferences. We evaluate LLM-Personalize on Housekeep, a challenging simulated real-world 3D benchmark for household rearrangements, and show that LLM-Personalize achieves more than a 30 percent increase in success rate over existing LLM planners, showcasing significantly improved alignment with human preferences. Project page: https://donggehan.github.io/projectllmpersonalize/.
Planning to Go Out-of-Distribution in Offline-to-Online Reinforcement Learning
Oct 09, 2023



Offline pretraining with a static dataset followed by online fine-tuning (offline-to-online, or OtO) is a paradigm that is well matched to a real-world RL deployment process: in few real settings would one deploy an offline policy with no test runs and tuning. In this scenario, we aim to find the best-performing policy within a limited budget of online interactions. Previous work in the OtO setting has focused on correcting for bias introduced by the policy-constraint mechanisms of offline RL algorithms. Such constraints keep the learned policy close to the behavior policy that collected the dataset, but this unnecessarily limits policy performance if the behavior policy is far from optimal. Instead, we forgo policy constraints and frame OtO RL as an exploration problem: we must maximize the benefit of the online data-collection. We study major online RL exploration paradigms, adapting them to work well with the OtO setting. These adapted methods contribute several strong baselines. Also, we introduce an algorithm for planning to go out of distribution (PTGOOD), which targets online exploration in relatively high-reward regions of the state-action space unlikely to be visited by the behavior policy. By leveraging concepts from the Conditional Entropy Bottleneck, PTGOOD encourages data collected online to provide new information relevant to improving the final deployment policy. In that way the limited interaction budget is used effectively. We show that PTGOOD significantly improves agent returns during online fine-tuning and finds the optimal policy in as few as 10k online steps in Walker and in as few as 50k in complex control tasks like Humanoid. Also, we find that PTGOOD avoids the suboptimal policy convergence that many of our baselines exhibit in several environments.