 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsSo3D: Inertial Navigation System and 3D Sonar SLAM for turbid environment inspection
Jan 09, 2026This paper presents InsSo3D, an accurate and efficient method for large-scale 3D Simultaneous Localisation and Mapping (SLAM) using a 3D Sonar and an Inertial Navigation System (INS). Unlike traditional sonar, which produces 2D images containing range and azimuth information but lacks elevation information, 3D Sonar produces a 3D point cloud, which therefore does not suffer from elevation ambiguity. We introduce a robust and modern SLAM framework adapted to the 3D Sonar data using INS as prior, detecting loop closure and performing pose graph optimisation. We evaluated InsSo3D performance inside a test tank with access to ground truth data and in an outdoor flooded quarry. Comparisons to reference trajectories and maps obtained from an underwater motion tracking system and visual Structure From Motion (SFM) demonstrate that InsSo3D efficiently corrects odometry drift. The average trajectory error is below 21cm during a 50-minute-long mission, producing a map of 10m by 20m with a 9cm average reconstruction error, enabling safe inspection of natural or artificial underwater structures even in murky water conditions.
VISO: Robust Underwater Visual-Inertial-Sonar SLAM with Photometric Rendering for Dense 3D Reconstruction
Jan 03, 2026Visual challenges in underwater environments significantly hinder the accuracy of vision-based localisation and the high-fidelity dense reconstruction. In this paper, we propose VISO, a robust underwater SLAM system that fuses a stereo camera, an inertial measurement unit (IMU), and a 3D sonar to achieve accurate 6-DoF localisation and enable efficient dense 3D reconstruction with high photometric fidelity. We introduce a coarse-to-fine online calibration approach for extrinsic parameters estimation between the 3D sonar and the camera. Additionally, a photometric rendering strategy is proposed for the 3D sonar point cloud to enrich the sonar map with visual information. Extensive experiments in a laboratory tank and an open lake demonstrate that VISO surpasses current state-of-the-art underwater and visual-based SLAM algorithms in terms of localisation robustness and accuracy, while also exhibiting real-time dense 3D reconstruction performance comparable to the offline dense mapping method.
Towards reliable subsea object recovery: a simulation study of an auv with a suction-actuated end effector
Jan 03, 2026Autonomous object recovery in the hadal zone is challenging due to extreme hydrostatic pressure, limited visibility and currents, and the need for precise manipulation at full ocean depth. Field experimentation in such environments is costly, high-risk, and constrained by limited vehicle availability, making early validation of autonomous behaviors difficult. This paper presents a simulation-based study of a complete autonomous subsea object recovery mission using a Hadal Small Vehicle (HSV) equipped with a three-degree-of-freedom robotic arm and a suction-actuated end effector. The Stonefish simulator is used to model realistic vehicle dynamics, hydrodynamic disturbances, sensing, and interaction with a target object under hadal-like conditions. The control framework combines a world-frame PID controller for vehicle navigation and stabilization with an inverse-kinematics-based manipulator controller augmented by acceleration feed-forward, enabling coordinated vehicle - manipulator operation. In simulation, the HSV autonomously descends from the sea surface to 6,000 m, performs structured seafloor coverage, detects a target object, and executes a suction-based recovery. The results demonstrate that high-fidelity simulation provides an effective and low-risk means of evaluating autonomous deep-sea intervention behaviors prior to field deployment.
Fast Policy Learning for 6-DOF Position Control of Underwater Vehicles
Dec 15, 2025Autonomous Underwater Vehicles (AUVs) require reliable six-degree-of-freedom (6-DOF) position control to operate effectively in complex and dynamic marine environments. Traditional controllers are effective under nominal conditions but exhibit degraded performance when faced with unmodeled dynamics or environmental disturbances. Reinforcement learning (RL) provides a powerful alternative but training is typically slow and sim-to-real transfer remains challenging. This work introduces a GPU-accelerated RL training pipeline built in JAX and MuJoCo-XLA (MJX). By jointly JIT-compiling large-scale parallel physics simulation and learning updates, we achieve training times of under two minutes.Through systematic evaluation of multiple RL algorithms, we show robust 6-DOF trajectory tracking and effective disturbance rejection in real underwater experiments, with policies transferred zero-shot from simulation. Our results provide the first explicit real-world demonstration of RL-based AUV position control across all six degrees of freedom.
Distributed AI Agents for Cognitive Underwater Robot Autonomy
Jul 31, 2025



Achieving robust cognitive autonomy in robots navigating complex, unpredictable environments remains a fundamental challenge in robotics. This paper presents Underwater Robot Self-Organizing Autonomy (UROSA), a groundbreaking architecture leveraging distributed Large Language Model AI agents integrated within the Robot Operating System 2 (ROS 2) framework to enable advanced cognitive capabilities in Autonomous Underwater Vehicles. UROSA decentralises cognition into specialised AI agents responsible for multimodal perception, adaptive reasoning, dynamic mission planning, and real-time decision-making. Central innovations include flexible agents dynamically adapting their roles, retrieval-augmented generation utilising vector databases for efficient knowledge management, reinforcement learning-driven behavioural optimisation, and autonomous on-the-fly ROS 2 node generation for runtime functional extensibility. Extensive empirical validation demonstrates UROSA's promising adaptability and reliability through realistic underwater missions in simulation and real-world deployments, showing significant advantages over traditional rule-based architectures in handling unforeseen scenarios, environmental uncertainties, and novel mission objectives. This work not only advances underwater autonomy but also establishes a scalable, safe, and versatile cognitive robotics framework capable of generalising to a diverse array of real-world applications.
Advancing Shared and Multi-Agent Autonomy in Underwater Missions: Integrating Knowledge Graphs and Retrieval-Augmented Generation
Jul 27, 2025Robotic platforms have become essential for marine operations by providing regular and continuous access to offshore assets, such as underwater infrastructure inspection, environmental monitoring, and resource exploration. However, the complex and dynamic nature of underwater environments, characterized by limited visibility, unpredictable currents, and communication constraints, presents significant challenges that demand advanced autonomy while ensuring operator trust and oversight. Central to addressing these challenges are knowledge representation and reasoning techniques, particularly knowledge graphs and retrieval-augmented generation (RAG) systems, that enable robots to efficiently structure, retrieve, and interpret complex environmental data. These capabilities empower robotic agents to reason, adapt, and respond effectively to changing conditions. The primary goal of this work is to demonstrate both multi-agent autonomy and shared autonomy, where multiple robotic agents operate independently while remaining connected to a human supervisor. We show how a RAG-powered large language model, augmented with knowledge graph data and domain taxonomy, enables autonomous multi-agent decision-making and facilitates seamless human-robot interaction, resulting in 100\% mission validation and behavior completeness. Finally, ablation studies reveal that without structured knowledge from the graph and/or taxonomy, the LLM is prone to hallucinations, which can compromise decision quality.
Context-Aware Behavior Learning with Heuristic Motion Memory for Underwater Manipulation
Jul 18, 2025



Autonomous motion planning is critical for efficient and safe underwater manipulation in dynamic marine environments. Current motion planning methods often fail to effectively utilize prior motion experiences and adapt to real-time uncertainties inherent in underwater settings. In this paper, we introduce an Adaptive Heuristic Motion Planner framework that integrates a Heuristic Motion Space (HMS) with Bayesian Networks to enhance motion planning for autonomous underwater manipulation. Our approach employs the Probabilistic Roadmap (PRM) algorithm within HMS to optimize paths by minimizing a composite cost function that accounts for distance, uncertainty, energy consumption, and execution time. By leveraging HMS, our framework significantly reduces the search space, thereby boosting computational performance and enabling real-time planning capabilities. Bayesian Networks are utilized to dynamically update uncertainty estimates based on real-time sensor data and environmental conditions, thereby refining the joint probability of path success. Through extensive simulations and real-world test scenarios, we showcase the advantages of our method in terms of enhanced performance and robustness. This probabilistic approach significantly advances the capability of autonomous underwater robots, ensuring optimized motion planning in the face of dynamic marine challenges.
MarineGym: A High-Performance Reinforcement Learning Platform for Underwater Robotics
Mar 12, 2025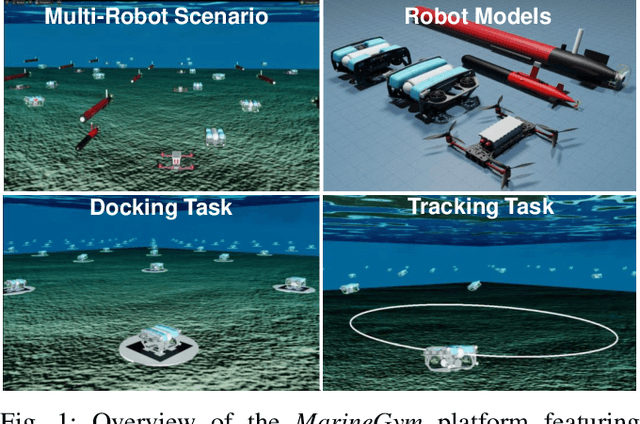
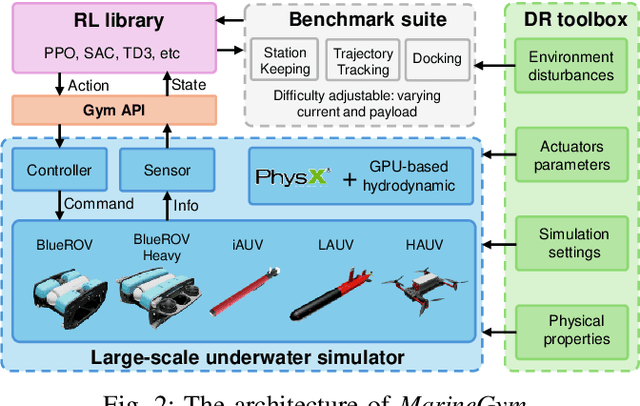
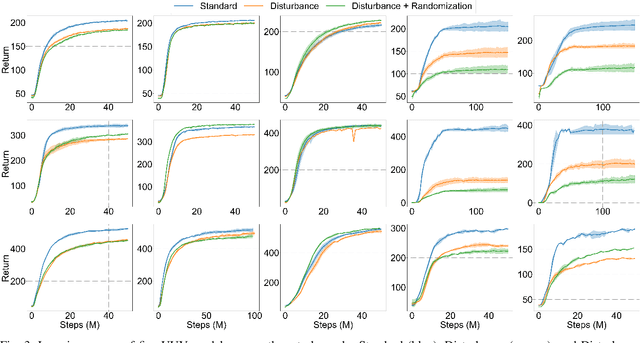
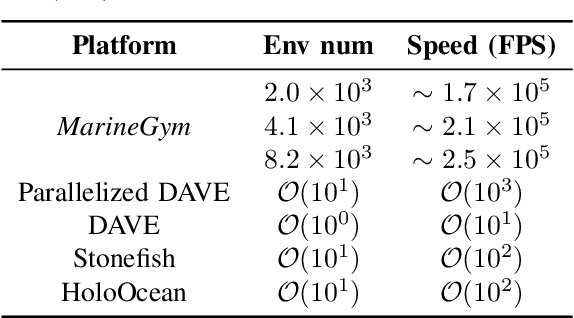
This work presents the MarineGym, a high-performance reinforcement learning (RL) platform specifically designed for underwater robotics. It aims to address the limitations of existing underwater simulation environments in terms of RL compatibility, training efficiency, and standardized benchmarking. MarineGym integrates a proposed GPU-accelerated hydrodynamic plugin based on Isaac Sim, achieving a rollout speed of 250,000 frames per second on a single NVIDIA RTX 3060 GPU. It also provides five models of unmanned underwater vehicles (UUVs), multiple propulsion systems, and a set of predefined tasks covering core underwater control challenges. Additionally, the DR toolkit allows flexible adjustments of simulation and task parameters during training to improve Sim2Real transfer. Further benchmark experiments demonstrate that MarineGym improves training efficiency over existing platforms and supports robust policy adaptation under various perturbations. We expect this platform could drive further advancements in RL research for underwater robotics. For more details about MarineGym and its applications, please visit our project page: https://marine-gym.com/.
Stonefish: Supporting Machine Learning Research in Marine Robotics
Feb 17, 2025Simulations are highly valuable in marine robotics, offering a cost-effective and controlled environment for testing in the challenging conditions of underwater and surface operations. Given the high costs and logistical difficulties of real-world trials, simulators capable of capturing the operational conditions of subsea environments have become key in developing and refining algorithms for remotely-operated and autonomous underwater vehicles. This paper highlights recent enhancements to the Stonefish simulator, an advanced open-source platform supporting development and testing of marine robotics solutions. Key updates include a suite of additional sensors, such as an event-based camera, a thermal camera, and an optical flow camera, as well as, visual light communication, support for tethered operations, improved thruster modelling, more flexible hydrodynamics, and enhanced sonar accuracy. These developments and an automated annotation tool significantly bolster Stonefish's role in marine robotics research, especially in the field of machine learning, where training data with a known ground truth is hard or impossible to collect.
SpasticMyoElbow: Physical Human-Robot Interaction Simulation Framework for Modelling Elbow Spasticity
Dec 06, 2024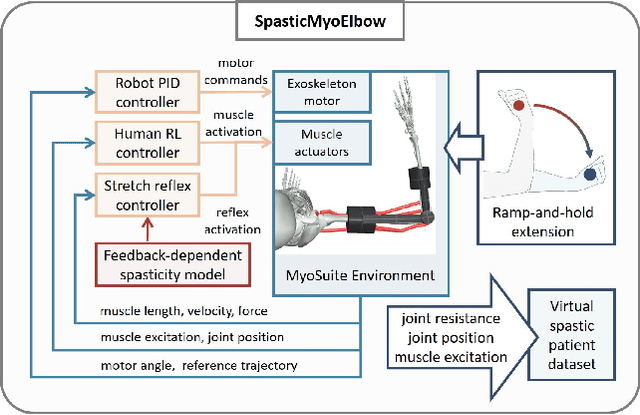
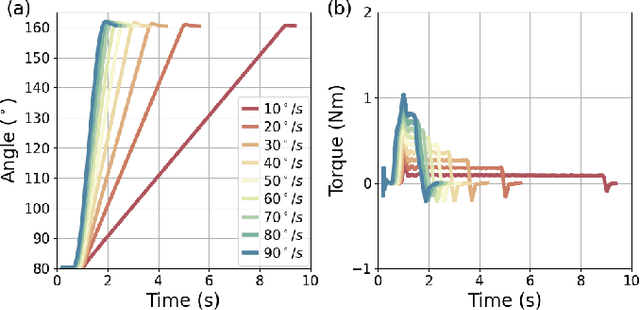
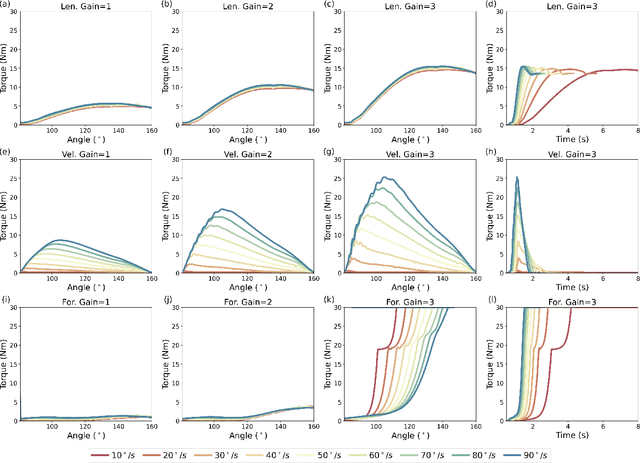
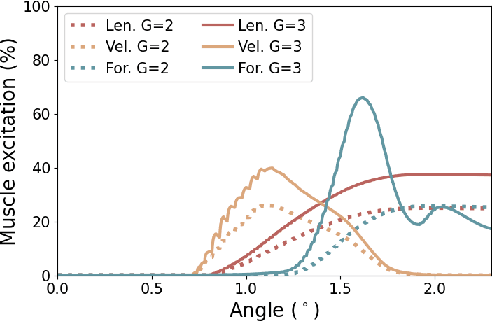
Robotic devices hold great potential for efficient and reliable assessment of neuromotor abnormalities in post-stroke patients. However, spasticity caused by stroke is still assessed manually in clinical settings. The limited and variable nature of data collected from patients has long posed a major barrier to quantitatively modelling spasticity with robotic measurements and fully validating robotic assessment techniques. This paper presents a simulation framework developed to support the design and validation of elbow spasticity models and mitigate data problems. The framework consists of a simulation environment of robot-assisted spasticity assessment, two motion controllers for the robot and human models, and a stretch reflex controller. Our framework allows simulation based on synthetic data without experimental data from human subjects. Using this framework, we replicated the constant-velocity stretch experiment typically used in robot-assisted spasticity assessment and evaluated four types of spasticity models. Our results show that a spasticity reflex model incorporating feedback on both muscle fibre velocity and length more accurately captures joint resistance characteristics during passive elbow stretching in spastic patients than a force-dependent model. When integrated with an appropriate spasticity model, this simulation framework has the potential to generate extensive datasets of virtual patients for future research on spasticity assessment.