 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchemaAgent: A Multi-Agents Framework for Generating Relational Database Schema
Mar 31, 2025The relational database design would output a schema based on user's requirements, which defines table structures and their interrelated relations. Translating requirements into accurate schema involves several non-trivial subtasks demanding both database expertise and domain-specific knowledge. This poses unique challenges for automated design of relational databases. Existing efforts are mostly based on customized rules or conventional deep learning models, often producing suboptimal schema. Recently, large language models (LLMs) have significantly advanced intelligent application development across various domains. In this paper, we propose SchemaAgent, a unified LLM-based multi-agent framework for the automated generation of high-quality database schema. SchemaAgent is the first to apply LLMs for schema generation, which emulates the workflow of manual schema design by assigning specialized roles to agents and enabling effective collaboration to refine their respective subtasks. Schema generation is a streamlined workflow, where directly applying the multi-agent framework may cause compounding impact of errors. To address this, we incorporate dedicated roles for reflection and inspection, alongside an innovative error detection and correction mechanism to identify and rectify issues across various phases. For evaluation, we present a benchmark named \textit{RSchema}, which contains more than 500 pairs of requirement description and schema. Experimental results on this benchmark demonstrate the superiority of our approach over mainstream LLMs for relational database schema generation.
MarineGym: A High-Performance Reinforcement Learning Platform for Underwater Robotics
Mar 12, 2025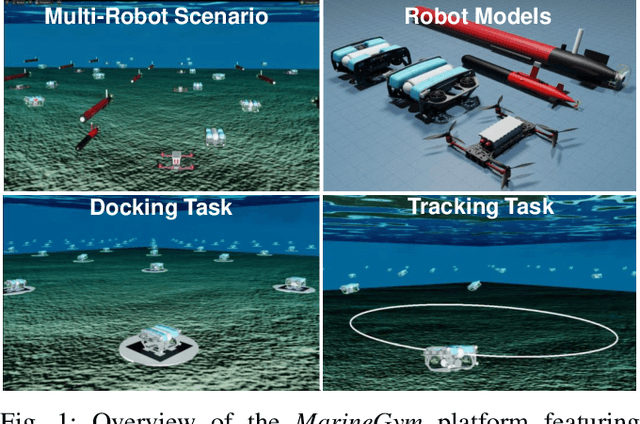
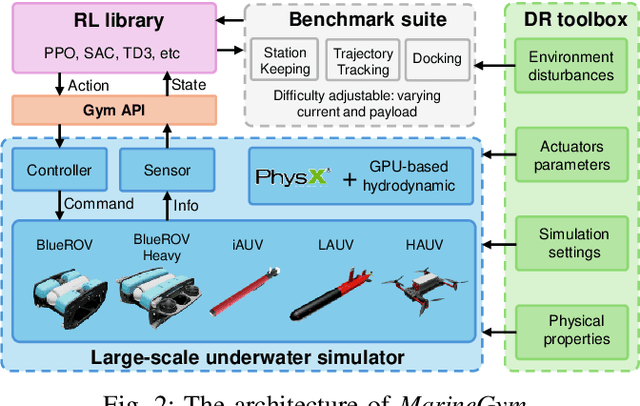
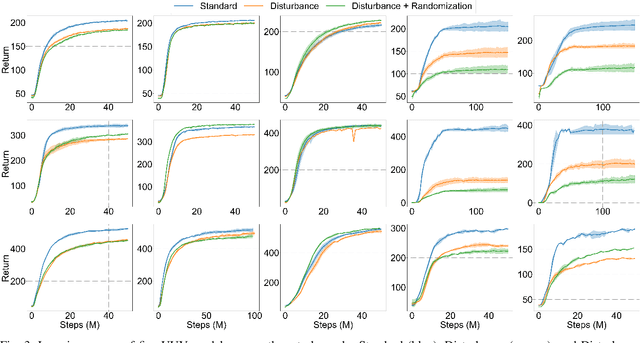
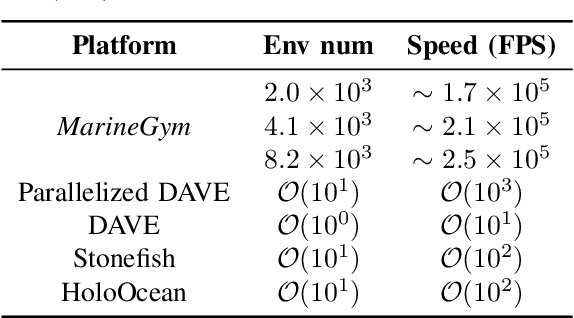
This work presents the MarineGym, a high-performance reinforcement learning (RL) platform specifically designed for underwater robotics. It aims to address the limitations of existing underwater simulation environments in terms of RL compatibility, training efficiency, and standardized benchmarking. MarineGym integrates a proposed GPU-accelerated hydrodynamic plugin based on Isaac Sim, achieving a rollout speed of 250,000 frames per second on a single NVIDIA RTX 3060 GPU. It also provides five models of unmanned underwater vehicles (UUVs), multiple propulsion systems, and a set of predefined tasks covering core underwater control challenges. Additionally, the DR toolkit allows flexible adjustments of simulation and task parameters during training to improve Sim2Real transfer. Further benchmark experiments demonstrate that MarineGym improves training efficiency over existing platforms and supports robust policy adaptation under various perturbations. We expect this platform could drive further advancements in RL research for underwater robotics. For more details about MarineGym and its applications, please visit our project page: https://marine-gym.com/.
SpasticMyoElbow: Physical Human-Robot Interaction Simulation Framework for Modelling Elbow Spasticity
Dec 06, 2024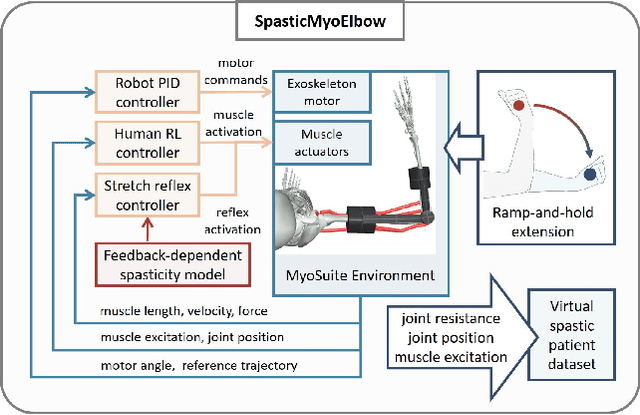
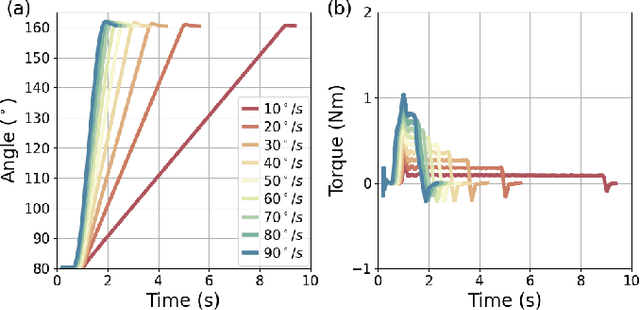
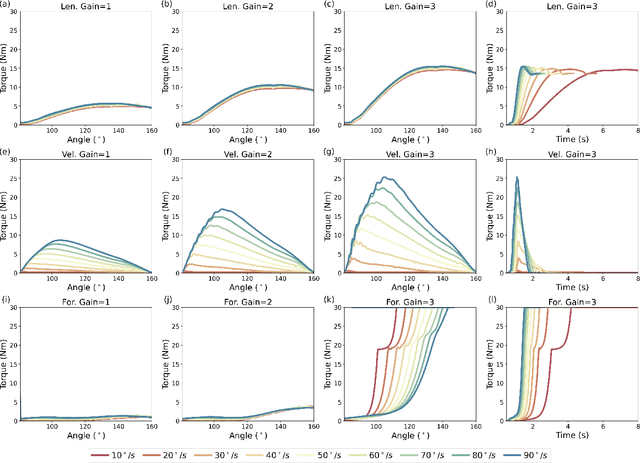
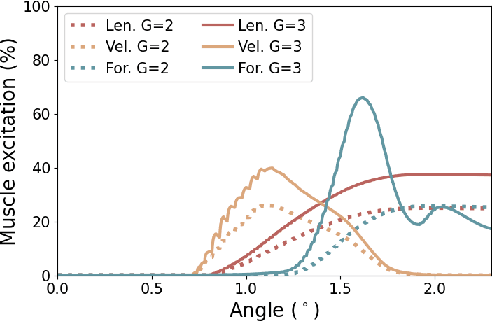
Robotic devices hold great potential for efficient and reliable assessment of neuromotor abnormalities in post-stroke patients. However, spasticity caused by stroke is still assessed manually in clinical settings. The limited and variable nature of data collected from patients has long posed a major barrier to quantitatively modelling spasticity with robotic measurements and fully validating robotic assessment techniques. This paper presents a simulation framework developed to support the design and validation of elbow spasticity models and mitigate data problems. The framework consists of a simulation environment of robot-assisted spasticity assessment, two motion controllers for the robot and human models, and a stretch reflex controller. Our framework allows simulation based on synthetic data without experimental data from human subjects. Using this framework, we replicated the constant-velocity stretch experiment typically used in robot-assisted spasticity assessment and evaluated four types of spasticity models. Our results show that a spasticity reflex model incorporating feedback on both muscle fibre velocity and length more accurately captures joint resistance characteristics during passive elbow stretching in spastic patients than a force-dependent model. When integrated with an appropriate spasticity model, this simulation framework has the potential to generate extensive datasets of virtual patients for future research on spasticity assessment.
MarineGym: Accelerated Training for Underwater Vehicles with High-Fidelity RL Simulation
Oct 18, 2024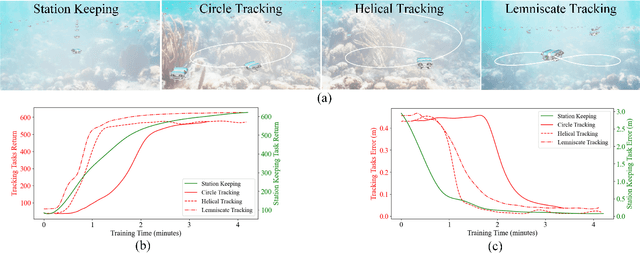
Reinforcement Learning (RL) is a promising solution, allowing Unmanned Underwater Vehicles (UUVs) to learn optimal behaviors through trial and error. However, existing simulators lack efficient integration with RL methods, limiting training scalability and performance. This paper introduces MarineGym, a novel simulation framework designed to enhance RL training efficiency for UUVs by utilizing GPU acceleration. MarineGym offers a 10,000-fold performance improvement over real-time simulation on a single GPU, enabling rapid training of RL algorithms across multiple underwater tasks. Key features include realistic dynamic modeling of UUVs, parallel environment execution, and compatibility with popular RL frameworks like PyTorch and TorchRL. The framework is validated through four distinct tasks: station-keeping, circle tracking, helical tracking, and lemniscate tracking. This framework sets the stage for advancing RL in underwater robotics and facilitating efficient training in complex, dynamic environments.
Replication of Impedance Identification Experiments on a Reinforcement-Learning-Controlled Digital Twin of Human Elbows
Feb 05, 2024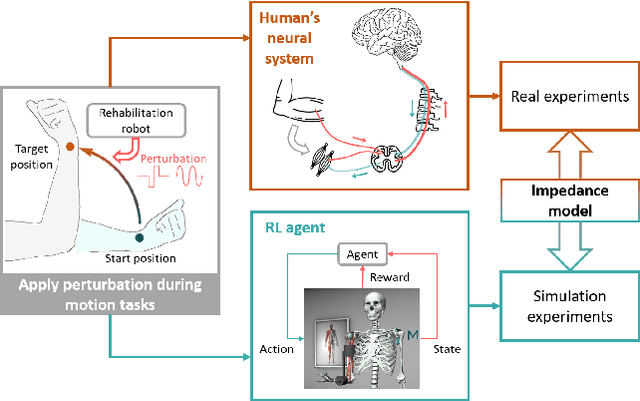
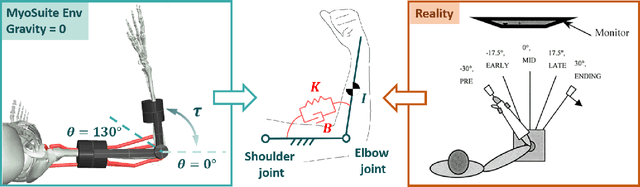
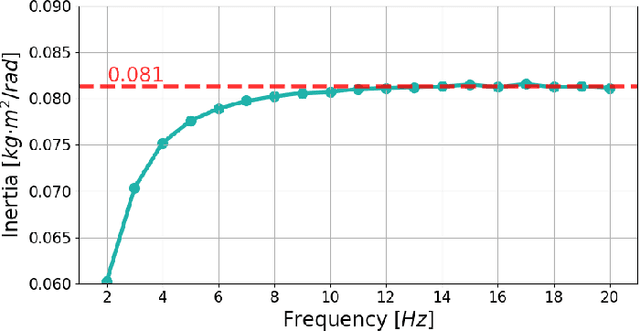
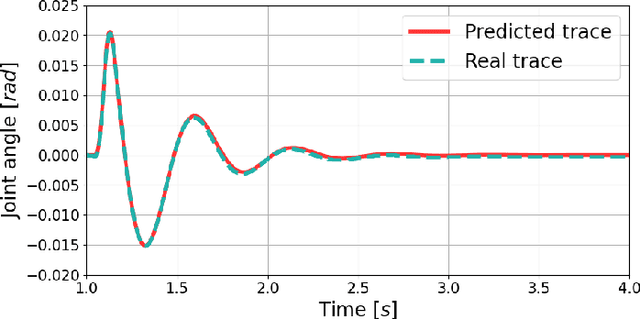
This study presents a pioneering effort to replicate human neuromechanical experiments within a virtual environment utilising a digital human model. By employing MyoSuite, a state-of-the-art human motion simulation platform enhanced by Reinforcement Learning (RL), multiple types of impedance identification experiments of human elbow were replicated on a musculoskeletal model. We compared the elbow movement controlled by an RL agent with the motion of an actual human elbow in terms of the impedance identified in torque-perturbation experiments. The findings reveal that the RL agent exhibits higher elbow impedance to stabilise the target elbow motion under perturbation than a human does, likely due to its shorter reaction time and superior sensory capabilities. This study serves as a preliminary exploration into the potential of virtual environment simulations for neuromechanical research, offering an initial yet promising alternative to conventional experimental approaches. An RL-controlled digital twin with complete musculoskeletal models of the human body is expected to be useful in designing experiments and validating rehabilitation theory before experiments on real human subjects.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
Nov 30, 2023This paper introduces innovative solutions to enhance spatial controllability in diffusion models reliant on text queries. We present two key innovations: Vision Guidance and the Layered Rendering Diffusion (LRDiff) framework. Vision Guidance, a spatial layout condition, acts as a clue in the perturbed distribution, greatly narrowing down the search space, to focus on the image sampling process adhering to the spatial layout condition. The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object. Such a layered rendering strategy effectively prevents issues like unintended conceptual blending or mismatches, while allowing for more coherent and contextually accurate image synthesis. The proposed method provides a more efficient and accurate means of synthesising images that align with specific spatial and contextual requirements. We demonstrate through our experiments that our method provides better results than existing techniques both quantitatively and qualitatively. We apply our method to three practical applications: bounding box-to-image, semantic mask-to-image and image editing.