 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenthiCat: An opti-acoustic dataset for advancing benthic classification and habitat mapping
Oct 06, 2025Benthic habitat mapping is fundamental for understanding marine ecosystems, guiding conservation efforts, and supporting sustainable resource management. Yet, the scarcity of large, annotated datasets limits the development and benchmarking of machine learning models in this domain. This paper introduces a thorough multi-modal dataset, comprising about a million side-scan sonar (SSS) tiles collected along the coast of Catalonia (Spain), complemented by bathymetric maps and a set of co-registered optical images from targeted surveys using an autonomous underwater vehicle (AUV). Approximately \num{36000} of the SSS tiles have been manually annotated with segmentation masks to enable supervised fine-tuning of classification models. All the raw sensor data, together with mosaics, are also released to support further exploration and algorithm development. To address challenges in multi-sensor data fusion for AUVs, we spatially associate optical images with corresponding SSS tiles, facilitating self-supervised, cross-modal representation learning. Accompanying open-source preprocessing and annotation tools are provided to enhance accessibility and encourage research. This resource aims to establish a standardized benchmark for underwater habitat mapping, promoting advancements in autonomous seafloor classification and multi-sensor integration.
eStonefish-scenes: A synthetically generated dataset for underwater event-based optical flow prediction tasks
May 19, 2025



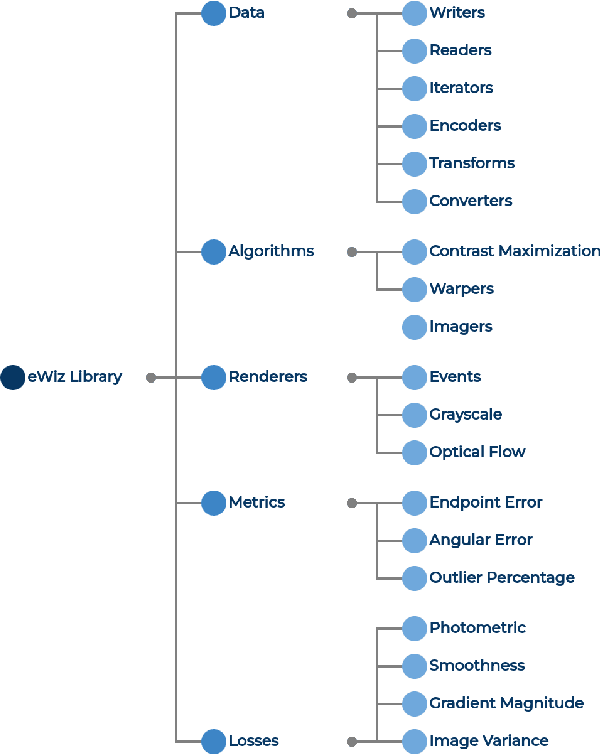
The combined use of event-based vision and Spiking Neural Networks (SNNs) is expected to significantly impact robotics, particularly in tasks like visual odometry and obstacle avoidance. While existing real-world event-based datasets for optical flow prediction, typically captured with Unmanned Aerial Vehicles (UAVs), offer valuable insights, they are limited in diversity, scalability, and are challenging to collect. Moreover, there is a notable lack of labelled datasets for underwater applications, which hinders the integration of event-based vision with Autonomous Underwater Vehicles (AUVs). To address this, synthetic datasets could provide a scalable solution while bridging the gap between simulation and reality. In this work, we introduce eStonefish-scenes, a synthetic event-based optical flow dataset based on the Stonefish simulator. Along with the dataset, we present a data generation pipeline that enables the creation of customizable underwater environments. This pipeline allows for simulating dynamic scenarios, such as biologically inspired schools of fish exhibiting realistic motion patterns, including obstacle avoidance and reactive navigation around corals. Additionally, we introduce a scene generator that can build realistic reef seabeds by randomly distributing coral across the terrain. To streamline data accessibility, we present eWiz, a comprehensive library designed for processing event-based data, offering tools for data loading, augmentation, visualization, encoding, and training data generation, along with loss functions and performance metrics.
Hyperspectral Imaging for Identifying Foreign Objects on Pork Belly
Mar 20, 2025



Ensuring food safety and quality is critical in the food processing industry, where the detection of contaminants remains a persistent challenge. This study presents an automated solution for detecting foreign objects on pork belly meat using hyperspectral imaging (HSI). A hyperspectral camera was used to capture data across various bands in the near-infrared (NIR) spectrum (900-1700 nm), enabling accurate identification of contaminants that are often undetectable through traditional visual inspection methods. The proposed solution combines pre-processing techniques with a segmentation approach based on a lightweight Vision Transformer (ViT) to distinguish contaminants from meat, fat, and conveyor belt materials. The adopted strategy demonstrates high detection accuracy and training efficiency, while also addressing key industrial challenges such as inherent noise, temperature variations, and spectral similarity between contaminants and pork belly. Experimental results validate the effectiveness of hyperspectral imaging in enhancing food safety, highlighting its potential for broad real-time applications in automated quality control processes.
Stonefish: Supporting Machine Learning Research in Marine Robotics
Feb 17, 2025Simulations are highly valuable in marine robotics, offering a cost-effective and controlled environment for testing in the challenging conditions of underwater and surface operations. Given the high costs and logistical difficulties of real-world trials, simulators capable of capturing the operational conditions of subsea environments have become key in developing and refining algorithms for remotely-operated and autonomous underwater vehicles. This paper highlights recent enhancements to the Stonefish simulator, an advanced open-source platform supporting development and testing of marine robotics solutions. Key updates include a suite of additional sensors, such as an event-based camera, a thermal camera, and an optical flow camera, as well as, visual light communication, support for tethered operations, improved thruster modelling, more flexible hydrodynamics, and enhanced sonar accuracy. These developments and an automated annotation tool significantly bolster Stonefish's role in marine robotics research, especially in the field of machine learning, where training data with a known ground truth is hard or impossible to collect.
The iToBoS dataset: skin region images extracted from 3D total body photographs for lesion detection
Jan 30, 2025



Artificial intelligence has significantly advanced skin cancer diagnosis by enabling rapid and accurate detection of malignant lesions. In this domain, most publicly available image datasets consist of single, isolated skin lesions positioned at the center of the image. While these lesion-centric datasets have been fundamental for developing diagnostic algorithms, they lack the context of the surrounding skin, which is critical for improving lesion detection. The iToBoS dataset was created to address this challenge. It includes 16,954 images of skin regions from 100 participants, captured using 3D total body photography. Each image roughly corresponds to a $7 \times 9$ cm section of skin with all suspicious lesions annotated using bounding boxes. Additionally, the dataset provides metadata such as anatomical location, age group, and sun damage score for each image. This dataset aims to facilitate training and benchmarking of algorithms, with the goal of enabling early detection of skin cancer and deployment of this technology in non-clinical environments.
eCARLA-scenes: A synthetically generated dataset for event-based optical flow prediction
Dec 12, 2024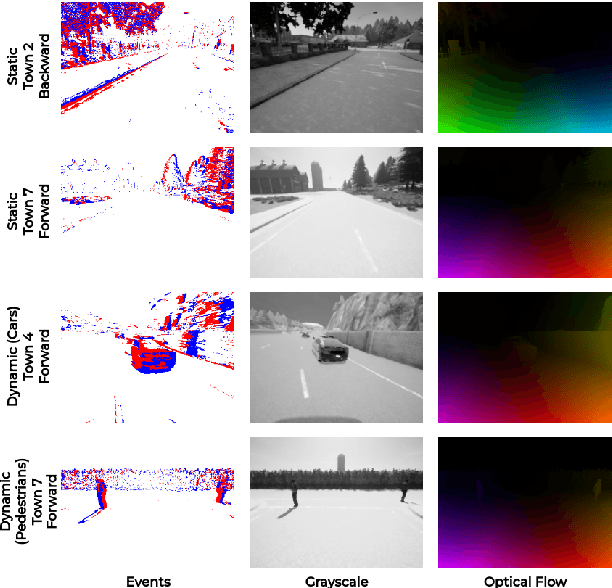

The joint use of event-based vision and Spiking Neural Networks (SNNs) is expected to have a large impact in robotics in the near future, in tasks such as, visual odometry and obstacle avoidance. While researchers have used real-world event datasets for optical flow prediction (mostly captured with Unmanned Aerial Vehicles (UAVs)), these datasets are limited in diversity, scalability, and are challenging to collect. Thus, synthetic datasets offer a scalable alternative by bridging the gap between reality and simulation. In this work, we address the lack of datasets by introducing eWiz, a comprehensive library for processing event-based data. It includes tools for data loading, augmentation, visualization, encoding, and generation of training data, along with loss functions and performance metrics. We further present a synthetic event-based datasets and data generation pipelines for optical flow prediction tasks. Built on top of eWiz, eCARLA-scenes makes use of the CARLA simulator to simulate self-driving car scenarios. The ultimate goal of this dataset is the depiction of diverse environments while laying a foundation for advancing event-based camera applications in autonomous field vehicle navigation, paving the way for using SNNs on neuromorphic hardware such as the Intel Loihi.
A Convolutional Vision Transformer for Semantic Segmentation of Side-Scan Sonar Data
Feb 24, 2023



Distinguishing among different marine benthic habitat characteristics is of key importance in a wide set of seabed operations ranging from installations of oil rigs to laying networks of cables and monitoring the impact of humans on marine ecosystems. The Side-Scan Sonar (SSS) is a widely used imaging sensor in this regard. It produces high-resolution seafloor maps by logging the intensities of sound waves reflected back from the seafloor. In this work, we leverage these acoustic intensity maps to produce pixel-wise categorization of different seafloor types. We propose a novel architecture adapted from the Vision Transformer (ViT) in an encoder-decoder framework. Further, in doing so, the applicability of ViTs is evaluated on smaller datasets. To overcome the lack of CNN-like inductive biases, thereby making ViTs more conducive to applications in low data regimes, we propose a novel feature extraction module to replace the Multi-layer Perceptron (MLP) block within transformer layers and a novel module to extract multiscale patch embeddings. A lightweight decoder is also proposed to complement this design in order to further boost multiscale feature extraction. With the modified architecture, we achieve state-of-the-art results and also meet real-time computational requirements. We make our code available at ~\url{https://github.com/hayatrajani/s3seg-vit