 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Integration with Evolvable Policies
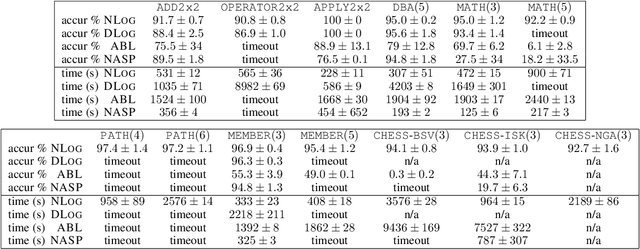
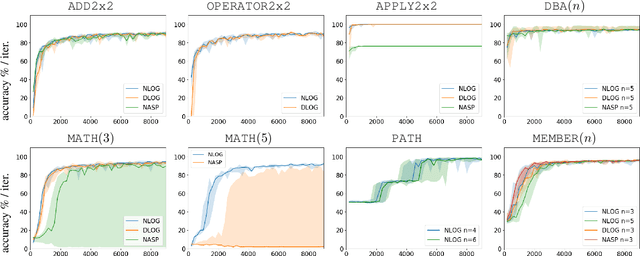
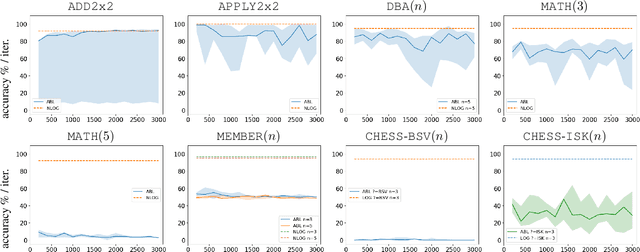
Jan 08, 2026Neural-Symbolic (NeSy) Artificial Intelligence has emerged as a promising approach for combining the learning capabilities of neural networks with the interpretable reasoning of symbolic systems. However, existing NeSy frameworks typically require either predefined symbolic policies or policies that are differentiable, limiting their applicability when domain expertise is unavailable or when policies are inherently non-differentiable. We propose a framework that addresses this limitation by enabling the concurrent learning of both non-differentiable symbolic policies and neural network weights through an evolutionary process. Our approach casts NeSy systems as organisms in a population that evolve through mutations (both symbolic rule additions and neural weight changes), with fitness-based selection guiding convergence toward hidden target policies. The framework extends the NEUROLOG architecture to make symbolic policies trainable, adapts Valiant's Evolvability framework to the NeSy context, and employs Machine Coaching semantics for mutable symbolic representations. Neural networks are trained through abductive reasoning from the symbolic component, eliminating differentiability requirements. Through extensive experimentation, we demonstrate that NeSy systems starting with empty policies and random neural weights can successfully approximate hidden non-differentiable target policies, achieving median correct performance approaching 100%. This work represents a step toward enabling NeSy research in domains where the acquisition of symbolic knowledge from experts is challenging or infeasible.
PEDESTRIAN: An Egocentric Vision Dataset for Obstacle Detection on Pavements
Dec 22, 2025Walking has always been a primary mode of transportation and is recognized as an essential activity for maintaining good health. Despite the need for safe walking conditions in urban environments, sidewalks are frequently obstructed by various obstacles that hinder free pedestrian movement. Any object obstructing a pedestrian's path can pose a safety hazard. The advancement of pervasive computing and egocentric vision techniques offers the potential to design systems that can automatically detect such obstacles in real time, thereby enhancing pedestrian safety. The development of effective and efficient identification algorithms relies on the availability of comprehensive and well-balanced datasets of egocentric data. In this work, we introduce the PEDESTRIAN dataset, comprising egocentric data for 29 different obstacles commonly found on urban sidewalks. A total of 340 videos were collected using mobile phone cameras, capturing a pedestrian's point of view. Additionally, we present the results of a series of experiments that involved training several state-of-the-art deep learning algorithms using the proposed dataset, which can be used as a benchmark for obstacle detection and recognition tasks. The dataset can be used for training pavement obstacle detectors to enhance the safety of pedestrians in urban areas.
Advancing Shared and Multi-Agent Autonomy in Underwater Missions: Integrating Knowledge Graphs and Retrieval-Augmented Generation
Jul 27, 2025Robotic platforms have become essential for marine operations by providing regular and continuous access to offshore assets, such as underwater infrastructure inspection, environmental monitoring, and resource exploration. However, the complex and dynamic nature of underwater environments, characterized by limited visibility, unpredictable currents, and communication constraints, presents significant challenges that demand advanced autonomy while ensuring operator trust and oversight. Central to addressing these challenges are knowledge representation and reasoning techniques, particularly knowledge graphs and retrieval-augmented generation (RAG) systems, that enable robots to efficiently structure, retrieve, and interpret complex environmental data. These capabilities empower robotic agents to reason, adapt, and respond effectively to changing conditions. The primary goal of this work is to demonstrate both multi-agent autonomy and shared autonomy, where multiple robotic agents operate independently while remaining connected to a human supervisor. We show how a RAG-powered large language model, augmented with knowledge graph data and domain taxonomy, enables autonomous multi-agent decision-making and facilitates seamless human-robot interaction, resulting in 100\% mission validation and behavior completeness. Finally, ablation studies reveal that without structured knowledge from the graph and/or taxonomy, the LLM is prone to hallucinations, which can compromise decision quality.
Experience and Prediction: A Metric of Hardness for a Novel Litmus Test
Sep 05, 2023In the last decade, the Winograd Schema Challenge (WSC) has become a central aspect of the research community as a novel litmus test. Consequently, the WSC has spurred research interest because it can be seen as the means to understand human behavior. In this regard, the development of new techniques has made possible the usage of Winograd schemas in various fields, such as the design of novel forms of CAPTCHAs. Work from the literature that established a baseline for human adult performance on the WSC has shown that not all schemas are the same, meaning that they could potentially be categorized according to their perceived hardness for humans. In this regard, this \textit{hardness-metric} could be used in future challenges or in the WSC CAPTCHA service to differentiate between Winograd schemas. Recent work of ours has shown that this could be achieved via the design of an automated system that is able to output the hardness-indexes of Winograd schemas, albeit with limitations regarding the number of schemas it could be applied on. This paper adds to previous research by presenting a new system that is based on Machine Learning (ML), able to output the hardness of any Winograd schema faster and more accurately than any other previously used method. Our developed system, which works within two different approaches, namely the random forest and deep learning (LSTM-based), is ready to be used as an extension of any other system that aims to differentiate between Winograd schemas, according to their perceived hardness for humans. At the same time, along with our developed system we extend previous work by presenting the results of a large-scale experiment that shows how human performance varies across Winograd schemas.
* 33 pages, 10 figures,
Neural Sculpting: Uncovering hierarchically modular task structure through pruning and network analysis
Jun 03, 2023Natural target functions and tasks typically exhibit hierarchical modularity - they can be broken down into simpler sub-functions that are organized in a hierarchy. Such sub-functions have two important features: they have a distinct set of inputs (input-separability) and they are reused as inputs higher in the hierarchy (reusability). Previous studies have established that hierarchically modular neural networks, which are inherently sparse, offer benefits such as learning efficiency, generalization, multi-task learning, and transferability. However, identifying the underlying sub-functions and their hierarchical structure for a given task can be challenging. The high-level question in this work is: if we learn a task using a sufficiently deep neural network, how can we uncover the underlying hierarchy of sub-functions in that task? As a starting point, we examine the domain of Boolean functions, where it is easier to determine whether a task is hierarchically modular. We propose an approach based on iterative unit and edge pruning (during training), combined with network analysis for module detection and hierarchy inference. Finally, we demonstrate that this method can uncover the hierarchical modularity of a wide range of Boolean functions and two vision tasks based on the MNIST digits dataset.
Computational Argumentation and Cognition
Nov 12, 2021This paper examines the interdisciplinary research question of how to integrate Computational Argumentation, as studied in AI, with Cognition, as can be found in Cognitive Science, Linguistics, and Philosophy. It stems from the work of the 1st Workshop on Computational Argumentation and Cognition (COGNITAR), which was organized as part of the 24th European Conference on Artificial Intelligence (ECAI), and took place virtually on September 8th, 2020. The paper begins with a brief presentation of the scientific motivation for the integration of Computational Argumentation and Cognition, arguing that within the context of Human-Centric AI the use of theory and methods from Computational Argumentation for the study of Cognition can be a promising avenue to pursue. A short summary of each of the workshop presentations is given showing the wide spectrum of problems where the synthesis of the theory and methods of Computational Argumentation with other approaches that study Cognition can be applied. The paper presents the main problems and challenges in the area that would need to be addressed, both at the scientific level but also at the epistemological level, particularly in relation to the synthesis of ideas and approaches from the various disciplines involved.
Explainability and the Fourth AI Revolution
Nov 12, 2021This chapter discusses AI from the prism of an automated process for the organization of data, and exemplifies the role that explainability has to play in moving from the current generation of AI systems to the next one, where the role of humans is lifted from that of data annotators working for the AI systems to that of collaborators working with the AI systems.
Abduction and Argumentation for Explainable Machine Learning: A Position Survey
Oct 24, 2020

This paper presents Abduction and Argumentation as two principled forms for reasoning, and fleshes out the fundamental role that they can play within Machine Learning. It reviews the state-of-the-art work over the past few decades on the link of these two reasoning forms with machine learning work, and from this it elaborates on how the explanation-generating role of Abduction and Argumentation makes them naturally-fitting mechanisms for the development of Explainable Machine Learning and AI systems. Abduction contributes towards this goal by facilitating learning through the transformation, preparation, and homogenization of data. Argumentation, as a conservative extension of classical deductive reasoning, offers a flexible prediction and coverage mechanism for learning -- an associated target language for learned knowledge -- that explicitly acknowledges the need to deal, in the context of learning, with uncertain, incomplete and inconsistent data that are incompatible with any classically-represented logical theory.
Neural-Symbolic Integration: A Compositional Perspective
Oct 22, 2020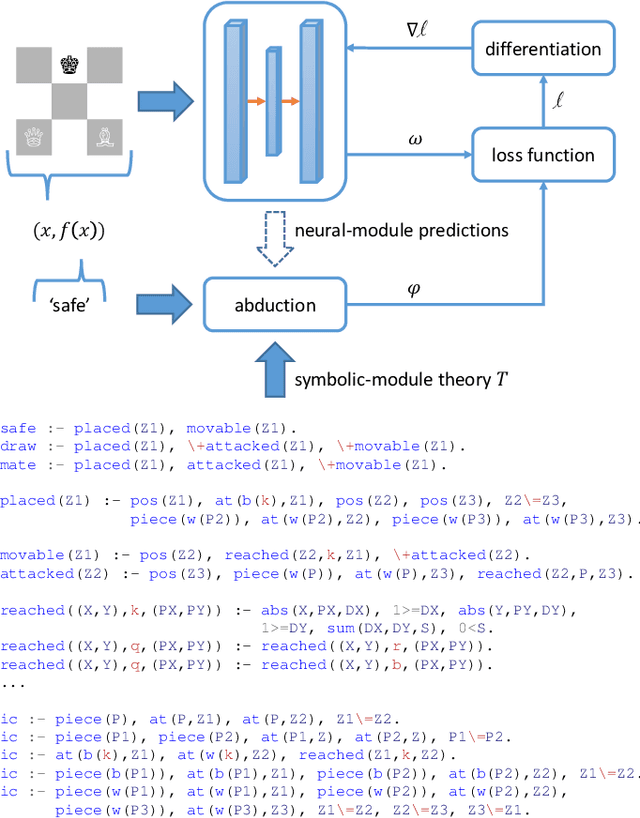
Despite significant progress in the development of neural-symbolic frameworks, the question of how to integrate a neural and a symbolic system in a \emph{compositional} manner remains open. Our work seeks to fill this gap by treating these two systems as black boxes to be integrated as modules into a single architecture, without making assumptions on their internal structure and semantics. Instead, we expect only that each module exposes certain methods for accessing the functions that the module implements: the symbolic module exposes a deduction method for computing the function's output on a given input, and an abduction method for computing the function's inputs for a given output; the neural module exposes a deduction method for computing the function's output on a given input, and an induction method for updating the function given input-output training instances. We are, then, able to show that a symbolic module --- with any choice for syntax and semantics, as long as the deduction and abduction methods are exposed --- can be cleanly integrated with a neural module, and facilitate the latter's efficient training, achieving empirical performance that exceeds that of previous work.
Contestable Black Boxes
Jun 30, 2020The right to contest a decision with consequences on individuals or the society is a well-established democratic right. Despite this right also being explicitly included in GDPR in reference to automated decision-making, its study seems to have received much less attention in the AI literature compared, for example, to the right for explanation. This paper investigates the type of assurances that are needed in the contesting process when algorithmic black-boxes are involved, opening new questions about the interplay of contestability and explainability. We argue that specialised complementary methodologies to evaluate automated decision-making in the case of a particular decision being contested need to be developed. Further, we propose a combination of well-established software engineering and rule-based approaches as a possible socio-technical solution to the issue of contestability, one of the new democratic challenges posed by the automation of decision making.