 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Process of Human-AI Value Alignment
Sep 17, 2025Background: Value alignment in computer science research is often used to refer to the process of aligning artificial intelligence with humans, but the way the phrase is used often lacks precision. Objectives: In this paper, we conduct a systematic literature review to advance the understanding of value alignment in artificial intelligence by characterising the topic in the context of its research literature. We use this to suggest a more precise definition of the term. Methods: We analyse 172 value alignment research articles that have been published in recent years and synthesise their content using thematic analyses. Results: Our analysis leads to six themes: value alignment drivers & approaches; challenges in value alignment; values in value alignment; cognitive processes in humans and AI; human-agent teaming; and designing and developing value-aligned systems. Conclusions: By analysing these themes in the context of the literature we define value alignment as an ongoing process between humans and autonomous agents that aims to express and implement abstract values in diverse contexts, while managing the cognitive limits of both humans and AI agents and also balancing the conflicting ethical and political demands generated by the values in different groups. Our analysis gives rise to a set of research challenges and opportunities in the field of value alignment for future work.
Negotiating Control: Neurosymbolic Variable Autonomy
Jul 23, 2024Variable autonomy equips a system, such as a robot, with mixed initiatives such that it can adjust its independence level based on the task's complexity and the surrounding environment. Variable autonomy solves two main problems in robotic planning: the first is the problem of humans being unable to keep focus in monitoring and intervening during robotic tasks without appropriate human factor indicators, and the second is achieving mission success in unforeseen and uncertain environments in the face of static reward structures. An open problem in variable autonomy is developing robust methods to dynamically balance autonomy and human intervention in real-time, ensuring optimal performance and safety in unpredictable and evolving environments. We posit that addressing unpredictable and evolving environments through an addition of rule-based symbolic logic has the potential to make autonomy adjustments more contextually reliable and adding feedback to reinforcement learning through data from mixed-initiative control further increases efficacy and safety of autonomous behaviour.
Clash of the Explainers: Argumentation for Context-Appropriate Explanations
Dec 12, 2023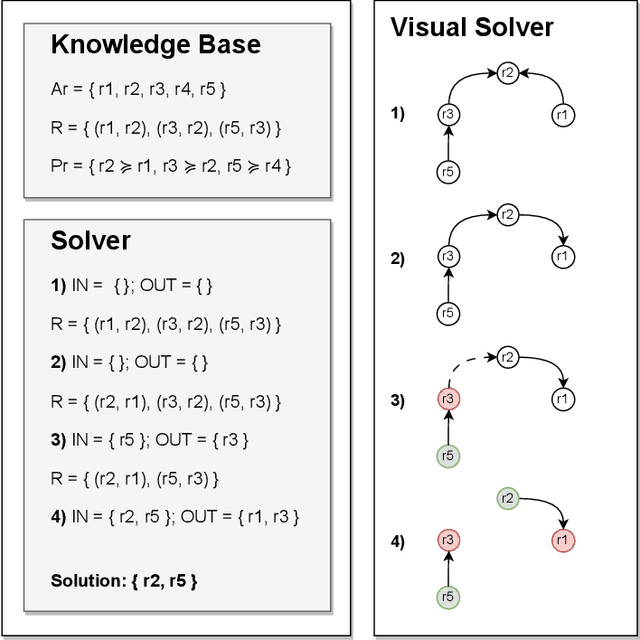
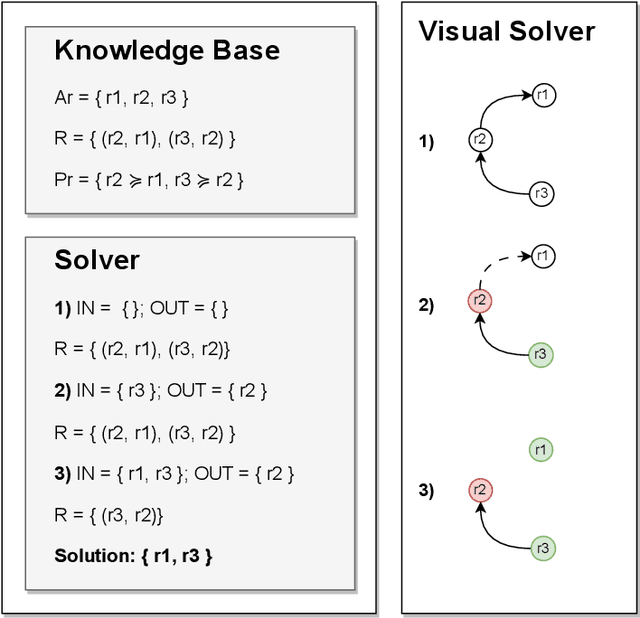
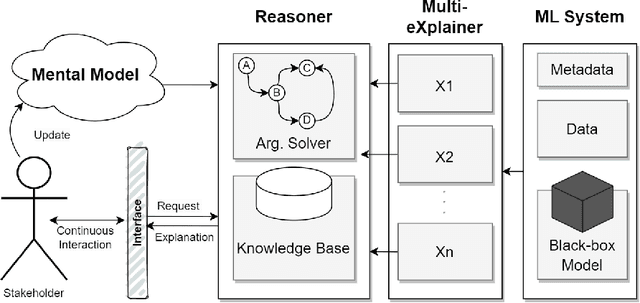
Understanding when and why to apply any given eXplainable Artificial Intelligence (XAI) technique is not a straightforward task. There is no single approach that is best suited for a given context. This paper aims to address the challenge of selecting the most appropriate explainer given the context in which an explanation is required. For AI explainability to be effective, explanations and how they are presented needs to be oriented towards the stakeholder receiving the explanation. If -- in general -- no single explanation technique surpasses the rest, then reasoning over the available methods is required in order to select one that is context-appropriate. Due to the transparency they afford, we propose employing argumentation techniques to reach an agreement over the most suitable explainers from a given set of possible explainers. In this paper, we propose a modular reasoning system consisting of a given mental model of the relevant stakeholder, a reasoner component that solves the argumentation problem generated by a multi-explainer component, and an AI model that is to be explained suitably to the stakeholder of interest. By formalising supporting premises -- and inferences -- we can map stakeholder characteristics to those of explanation techniques. This allows us to reason over the techniques and prioritise the best one for the given context, while also offering transparency into the selection decision.
Towards an MLOps Architecture for XAI in Industrial Applications
Sep 22, 2023



Machine learning (ML) has become a popular tool in the industrial sector as it helps to improve operations, increase efficiency, and reduce costs. However, deploying and managing ML models in production environments can be complex. This is where Machine Learning Operations (MLOps) comes in. MLOps aims to streamline this deployment and management process. One of the remaining MLOps challenges is the need for explanations. These explanations are essential for understanding how ML models reason, which is key to trust and acceptance. Better identification of errors and improved model accuracy are only two resulting advantages. An often neglected fact is that deployed models are bypassed in practice when accuracy and especially explainability do not meet user expectations. We developed a novel MLOps software architecture to address the challenge of integrating explanations and feedback capabilities into the ML development and deployment processes. In the project EXPLAIN, our architecture is implemented in a series of industrial use cases. The proposed MLOps software architecture has several advantages. It provides an efficient way to manage ML models in production environments. Further, it allows for integrating explanations into the development and deployment processes.
Robot Health Indicator: A Visual Cue to Improve Level of Autonomy Switching Systems
Mar 12, 2023Using different Levels of Autonomy (LoA), a human operator can vary the extent of control they have over a robot's actions. LoAs enable operators to mitigate a robot's performance degradation or limitations in the its autonomous capabilities. However, LoA regulation and other tasks may often overload an operator's cognitive abilities. Inspired by video game user interfaces, we study if adding a 'Robot Health Bar' to the robot control UI can reduce the cognitive demand and perceptual effort required for LoA regulation while promoting trust and transparency. This Health Bar uses the robot vitals and robot health framework to quantify and present runtime performance degradation in robots. Results from our pilot study indicate that when using a health bar, operators used to manual control more to minimise the risk of robot failure during high performance degradation. It also gave us insights and lessons to inform subsequent experiments on human-robot teaming.
Let it RAIN for Social Good
Jul 26, 2022Artificial Intelligence (AI) as a highly transformative technology take on a special role as both an enabler and a threat to UN Sustainable Development Goals (SDGs). AI Ethics and emerging high-level policy efforts stand at the pivot point between these outcomes but is barred from effect due the abstraction gap between high-level values and responsible action. In this paper the Responsible Norms (RAIN) framework is presented, bridging this gap thereby enabling effective high-level control of AI impact. With effective and operationalized AI Ethics, AI technologies can be directed towards global sustainable development.
Embracing AWKWARD! Real-time Adjustment of Reactive Plans Using Social Norms
Apr 26, 2022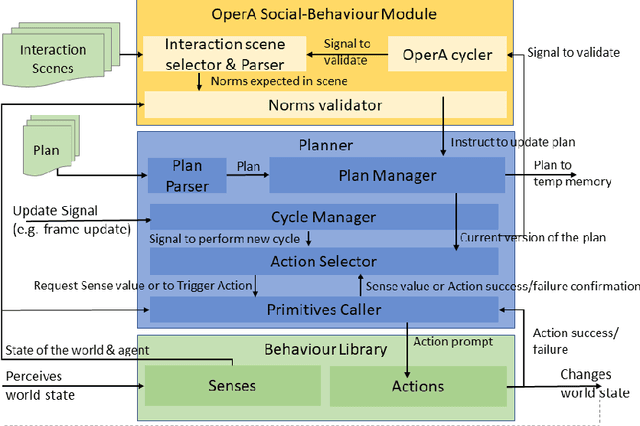


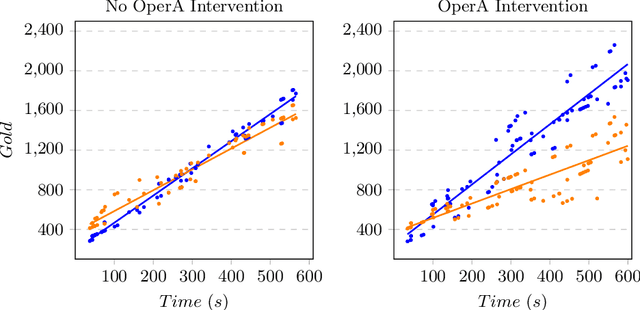
This paper presents the AWKWARD agent architecture for the development of agents in Multi-Agent Systems. AWKWARD agents can have their plans re-configured in real time to align with social role requirements under changing environmental and social circumstances. The proposed hybrid architecture makes use of Behaviour Oriented Design (BOD) to develop agents with reactive planning and of the well-established OperA framework to provide organisational, social, and interaction definitions in order to validate and adjust agents' behaviours. Together, OperA and BOD can achieve real-time adjustment of agent plans for evolving social roles, while providing the additional benefit of transparency into the interactions that drive this behavioural change in individual agents. We present this architecture to motivate the bridging between traditional symbolic- and behaviour-based AI communities, where such combined solutions can help MAS researchers in their pursuit of building stronger, more robust intelligent agent teams. We use DOTA2, a game where success is heavily dependent on social interactions, as a medium to demonstrate a sample implementation of our proposed hybrid architecture.
Interrogating the Black Box: Transparency through Information-Seeking Dialogues
Feb 09, 2021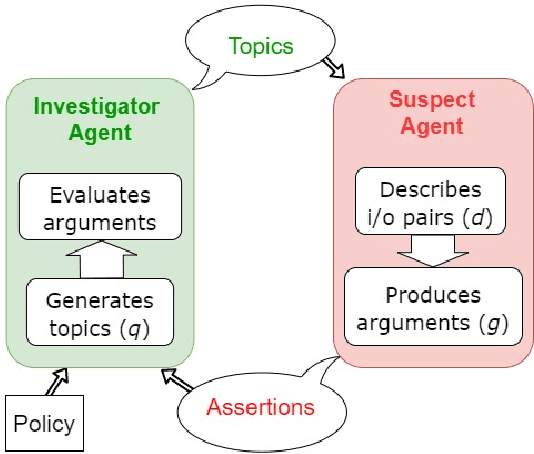

This paper is preoccupied with the following question: given a (possibly opaque) learning system, how can we understand whether its behaviour adheres to governance constraints? The answer can be quite simple: we just need to "ask" the system about it. We propose to construct an investigator agent to query a learning agent -- the suspect agent -- to investigate its adherence to a given ethical policy in the context of an information-seeking dialogue, modeled in formal argumentation settings. This formal dialogue framework is the main contribution of this paper. Through it, we break down compliance checking mechanisms into three modular components, each of which can be tailored to various needs in a vast amount of ways: an investigator agent, a suspect agent, and an acceptance protocol determining whether the responses of the suspect agent comply with the policy. This acceptance protocol presents a fundamentally different approach to aggregation: rather than using quantitative methods to deal with the non-determinism of a learning system, we leverage the use of argumentation semantics to investigate the notion of properties holding consistently. Overall, we argue that the introduced formal dialogue framework opens many avenues both in the area of compliance checking and in the analysis of properties of opaque systems.
Contestable Black Boxes
Jun 30, 2020The right to contest a decision with consequences on individuals or the society is a well-established democratic right. Despite this right also being explicitly included in GDPR in reference to automated decision-making, its study seems to have received much less attention in the AI literature compared, for example, to the right for explanation. This paper investigates the type of assurances that are needed in the contesting process when algorithmic black-boxes are involved, opening new questions about the interplay of contestability and explainability. We argue that specialised complementary methodologies to evaluate automated decision-making in the case of a particular decision being contested need to be developed. Further, we propose a combination of well-established software engineering and rule-based approaches as a possible socio-technical solution to the issue of contestability, one of the new democratic challenges posed by the automation of decision making.
Governance by Glass-Box: Implementing Transparent Moral Bounds for AI Behaviour
Apr 30, 2019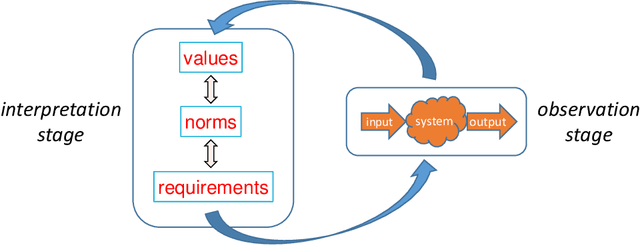
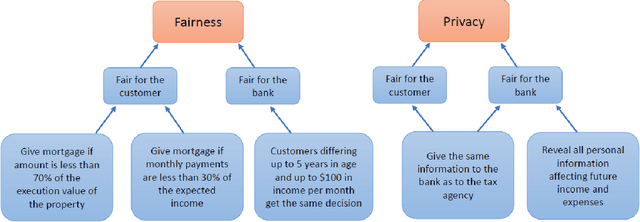
Artificial Intelligence (AI) applications are being used to predict and assess behaviour in multiple domains, such as criminal justice and consumer finance, which directly affect human well-being. However, if AI is to improve people's lives, then people must be able to trust AI, which means being able to understand what the system is doing and why. Even though transparency is often seen as the requirement in this case, realistically it might not always be possible or desirable, whereas the need to ensure that the system operates within set moral bounds remains. In this paper, we present an approach to evaluate the moral bounds of an AI system based on the monitoring of its inputs and outputs. We place a "glass box" around the system by mapping moral values into explicit verifiable norms that constrain inputs and outputs, in such a way that if these remain within the box we can guarantee that the system adheres to the value. The focus on inputs and outputs allows for the verification and comparison of vastly different intelligent systems; from deep neural networks to agent-based systems. The explicit transformation of abstract moral values into concrete norms brings great benefits in terms of explainability; stakeholders know exactly how the system is interpreting and employing relevant abstract moral human values and calibrate their trust accordingly. Moreover, by operating at a higher level we can check the compliance of the system with different interpretations of the same value. These advantages will have an impact on the well-being of AI systems users at large, building their trust and providing them with concrete knowledge on how systems adhere to moral values.