 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Jun 26, 2024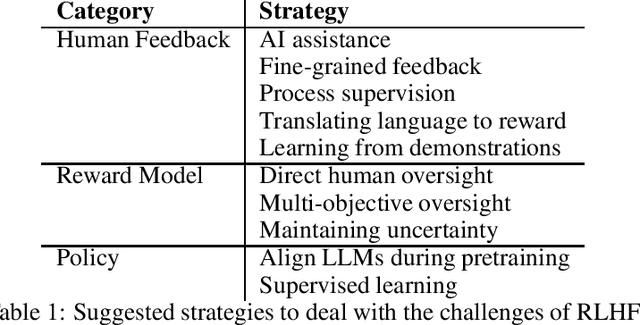
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
Clash of the Explainers: Argumentation for Context-Appropriate Explanations
Dec 12, 2023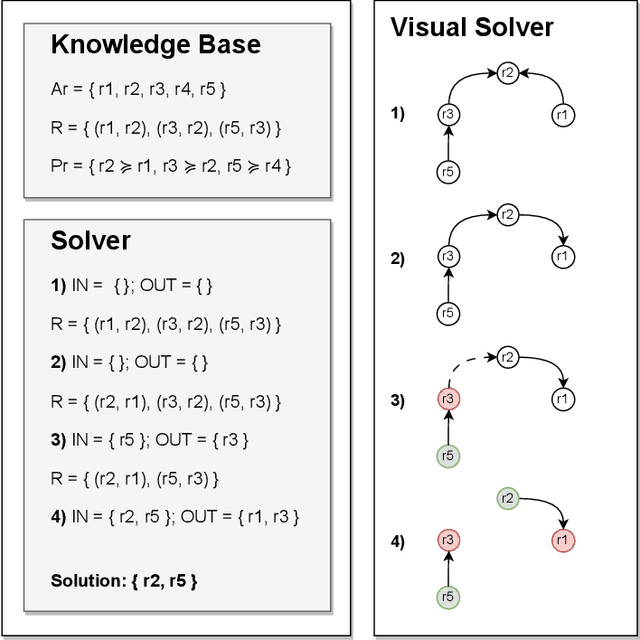
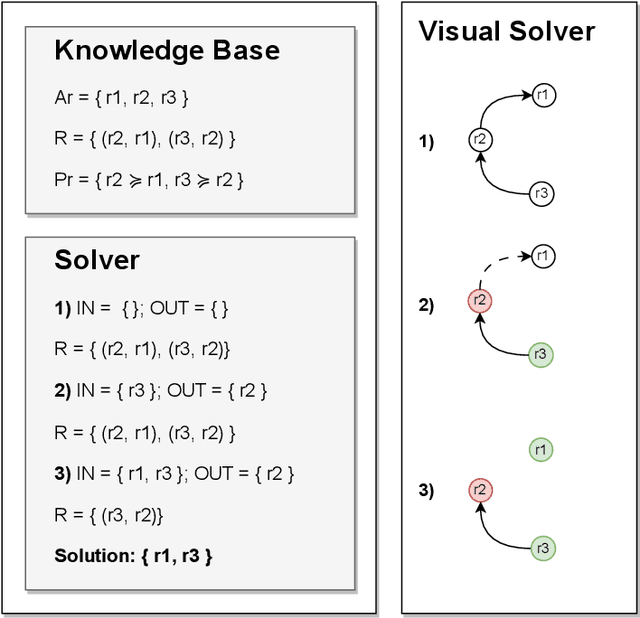
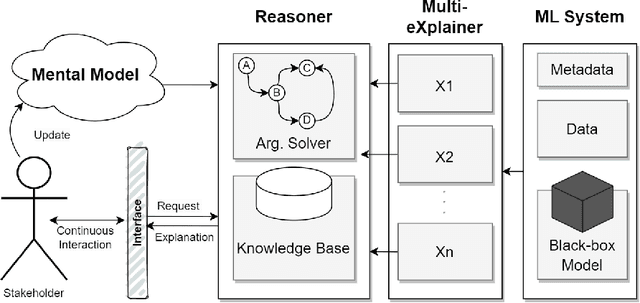
Understanding when and why to apply any given eXplainable Artificial Intelligence (XAI) technique is not a straightforward task. There is no single approach that is best suited for a given context. This paper aims to address the challenge of selecting the most appropriate explainer given the context in which an explanation is required. For AI explainability to be effective, explanations and how they are presented needs to be oriented towards the stakeholder receiving the explanation. If -- in general -- no single explanation technique surpasses the rest, then reasoning over the available methods is required in order to select one that is context-appropriate. Due to the transparency they afford, we propose employing argumentation techniques to reach an agreement over the most suitable explainers from a given set of possible explainers. In this paper, we propose a modular reasoning system consisting of a given mental model of the relevant stakeholder, a reasoner component that solves the argumentation problem generated by a multi-explainer component, and an AI model that is to be explained suitably to the stakeholder of interest. By formalising supporting premises -- and inferences -- we can map stakeholder characteristics to those of explanation techniques. This allows us to reason over the techniques and prioritise the best one for the given context, while also offering transparency into the selection decision.
Towards an MLOps Architecture for XAI in Industrial Applications
Sep 22, 2023



Machine learning (ML) has become a popular tool in the industrial sector as it helps to improve operations, increase efficiency, and reduce costs. However, deploying and managing ML models in production environments can be complex. This is where Machine Learning Operations (MLOps) comes in. MLOps aims to streamline this deployment and management process. One of the remaining MLOps challenges is the need for explanations. These explanations are essential for understanding how ML models reason, which is key to trust and acceptance. Better identification of errors and improved model accuracy are only two resulting advantages. An often neglected fact is that deployed models are bypassed in practice when accuracy and especially explainability do not meet user expectations. We developed a novel MLOps software architecture to address the challenge of integrating explanations and feedback capabilities into the ML development and deployment processes. In the project EXPLAIN, our architecture is implemented in a series of industrial use cases. The proposed MLOps software architecture has several advantages. It provides an efficient way to manage ML models in production environments. Further, it allows for integrating explanations into the development and deployment processes.
Embracing AWKWARD! Real-time Adjustment of Reactive Plans Using Social Norms
Apr 26, 2022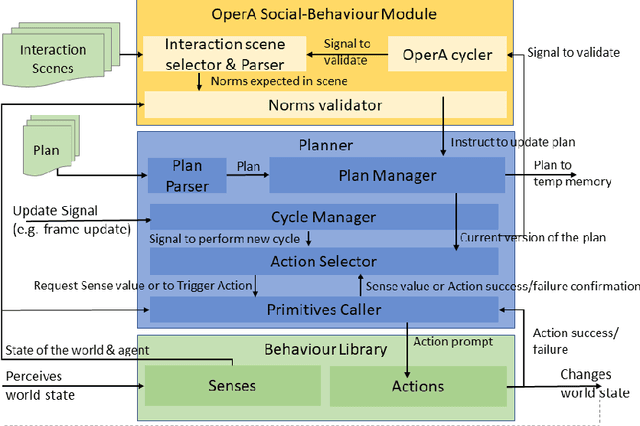


This paper presents the AWKWARD agent architecture for the development of agents in Multi-Agent Systems. AWKWARD agents can have their plans re-configured in real time to align with social role requirements under changing environmental and social circumstances. The proposed hybrid architecture makes use of Behaviour Oriented Design (BOD) to develop agents with reactive planning and of the well-established OperA framework to provide organisational, social, and interaction definitions in order to validate and adjust agents' behaviours. Together, OperA and BOD can achieve real-time adjustment of agent plans for evolving social roles, while providing the additional benefit of transparency into the interactions that drive this behavioural change in individual agents. We present this architecture to motivate the bridging between traditional symbolic- and behaviour-based AI communities, where such combined solutions can help MAS researchers in their pursuit of building stronger, more robust intelligent agent teams. We use DOTA2, a game where success is heavily dependent on social interactions, as a medium to demonstrate a sample implementation of our proposed hybrid architecture.